
什么是数据仓库服务
数据仓库服务 DWS是一种基于华为云基础架构和平台的在线数据分析处理数据库,提供即开即用、可扩展且完全托管的分析型数据库服务,兼容ANSI/ISO标准的SQL92、SQL99和SQL 2003语法,同时兼容PostgreSQL/Oracle/Teradata/MySQL等数据库生态,为各行业PB级海量大数据分析提供有竞争力的解决方案。
DWS提供存算一体、存算分离多种产品形态,围绕企业级内核、实时分析、协同计算、融合分析、云原生五大方向构筑业界第一数据仓库。详情请参见数据仓库类型。
- 存算一体:面向数据分析场景,为用户提供高性能、高扩展、高可靠、高安全、易运维的企业级数仓服务,支持2048节点、20PB级超大规模数据分析能力,适用于“库、仓、市、湖”一体化的融合分析业务。
- 存算分离:采用存算分离云原生架构,计算、存储分层弹性伸缩,极致性价比,采用多逻辑集群(Virtual Warehouse,以下简称VW)共享存储技术,实现不同负载的计算隔离和并发扩展,适用于OLAP分析场景。
DWS可广泛应用于金融、车联网、政企、电商、能源、电信等多个领域,已连续两年入选Gartner发布的数据管理解决方案魔力象限,相比传统数据仓库,性价比提升数倍,具备大规模扩展能力和企业级可靠性。
集群逻辑架构

|
名称 |
描述 |
说明 |
|---|---|---|
|
CM |
集群管理模块(Cluster Manager)。管理和监控分布式系统中各个功能单元和物理资源的运行情况,确保整个系统的稳定运行。 |
CM由CM Agent、OM Monitor和CM Server组成。
DWS提供了CM Server的主备实例方案,以保证集群管理系统本身的高可用性。正常情况下,CM Agent连接主CM Server,在主CM Server发生故障的情况下,备CM Server会主动升为主CM Server,避免出现CM Server单点故障。 |
|
GTM |
全局事务管理器(Global Transaction Manager),负责生成和维护全局事务ID、事务快照、时间戳等全局唯一的信息。 |
整个集群只有一组GTM:主、备GTM各一个。 |
|
WLM |
工作负载管理器(Workload Manager)。控制系统资源的分配,防止过量业务负载对系统的冲击而导致业务拥塞和系统崩溃。 |
不同于集群中的实例(GTM、CM、CN、DN)模块,不需要在安装过程中指定主机名称。安装程序会自动在各主机上安装此模块。 |
|
CN |
协调节点(Coordinator)。负责接收来自应用的访问请求,并向客户端返回执行结果;负责分解任务,并调度任务分片在各DN上并行执行。 |
集群中,CN有多个并且CN的角色是对等的(执行DML语句时连接到任何一个CN都可以得到一致的结果)。只需要在CN和应用程序之间增加一个负载均衡器,使得CN对应用是透明的。CN故障时,由负载均衡自动路由连接到另一个CN,请参见集群绑定和解绑ELB。 当前分布式事务框架下无法避免CN之间的互连,为了减少GTM上线程过多导致负载过大,建议CN配置数目≤10个。 DWS通过CCN(Central Coordinator )负责集群内的资源全局负载控制,以实现自适应的动态负载管理。CM在第一次集群启动时,通过集群部署形式,选择编号最小的CN作为CCN。若CCN故障之后,由CM选择新的CCN进行替换。 |
|
DN |
数据节点(Datanode)。负责存储业务数据(支持行存、列存、混合存储)、执行数据查询任务以及向CN返回执行结果。 |
在集群中,DN有多个。每个DN存储了一部分数据。DWS对DN提供了高可用方案:主DN、备DN、从备DN。三者的工作原理如下:
也就是说从备DN永远只作为从备使用,不会因为主DN或备DN故障而升级为主DN或备DN,从备DN只存放原主DN故障时,新升为主的DN同步到从备DN的Xlog数据和数据通道复制产生的数据。因此从备DN不额外占用存储资源,相比传统三副本节约了三分之一的存储空间。 |
|
Storage |
服务器的本地存储资源,持久化存储数据。 |
- |
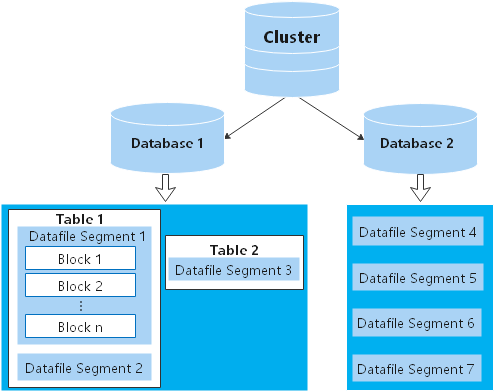
集群的每个DN上负责存储数据,其存储介质也是磁盘。图2从逻辑上介绍了每个DN上都有哪些对象,以及这些对象之间的关系,其中:
- Database,即数据库,用于管理各类数据对象,各数据库间相互隔离。
- Datafile Segment,即数据文件,通常每张表只对应一个数据文件。如果某张表的数据大于1GB,则会分为多个数据文件存储。
- Table,即表,每张表只能属于一个数据库。
- Block,即数据块,是数据库管理的基本单位,默认大小为8KB。
数据有三种分布方式,可以在建表的时候指定:REPLICATION、ROUNDROBIN 、HASH。
集群物理架构
DWS支持存算一体架构和存算分离架构。
其中,存算一体架构,数据存储在DN本地盘上。存算分离架构,DN本地盘仅做数据缓存和存储元数据,用户数据存储在OBS对象存储上。您可以根据需要选择相应的架构。

存算一体架构
DWS基于Shared-nothing分布式架构,具备MPP(Massively Parallel Processing)大规模并行处理引擎,由众多拥有独立且互不共享的CPU、内存、存储等系统资源的逻辑节点组成。在这样的系统架构中,业务数据被分散存储在多个节点上,数据分析任务被推送到数据所在位置就近执行,并行地完成大规模的数据处理工作,实现对数据处理的快速响应。

- 应用层
数据加载工具、ETL(Extract-Transform-Load)工具、以及商业智能BI工具、数据挖掘和分析工具,均可以通过标准接口与DWS集成。DWS兼容PostgreSQL生态,且SQL语法进行了兼容MySQL、Oracle和Teradata的处理。应用只需做少量改动即可向DWS平滑迁移。
- 接口
支持应用程序通过标准JDBC和ODBC连接DWS。
- DWS
一个DWS集群由多个在相同子网中的相同规格的节点组成,共同提供服务。集群的每个DN负责存储数据,其存储介质是磁盘。协调节点(Coordinator)负责接收来自应用的访问请求,并向客户端返回执行结果。此外,协调节点还负责分解任务,并调度任务分片在各DN上并行执行。
- 自动数据备份
支持将集群快照自动备份到EB级对象存储服务OBS(Object Storage Service)中,方便利用业务空闲期对集群做周期备份以保证集群异常后的数据恢复。
快照是DWS集群在某一时间点的完整备份,记录了该时刻指定集群的所有配置数据和业务数据。
- 工具链
提供了数据并行加载工具GDS(General Data Service)、SQL语法迁移工具DSC(Database Schema Convertor)、SQL开发工具Data Studio、迁移工具GDS-Kafka,并支持通过控制台对集群进行运维监控。
存算分离架构
DWS全新推出云原生数仓存算分离版本,利用云基础设施提供的资源池化和海量存储能力,结合MPP数据库技术,采用计算存储分离架构,实现了极致弹性、实时入库、数据实时共享和湖仓一体等特性。
云原生数仓存算分离采用计算存储分离架构,解决了计算存储必须等比例缩放的问题。赋能用户面向业务峰谷时,对计算能力进行快速且独立的扩缩要求,同时保证存储无限扩展、按需付费,快速、敏捷的响应业务变化,同时具有更高的性价比,进一步助力企业降本增效。
存算分离具有以下优势:
- 湖仓一体:提供简单、易维护的湖仓一体体验,无缝对接DLI,支持元数据自动导入、外部表查询加速、内外表关联查询,支持数据湖格式读写,简化数据入湖入仓。
- 实时写入:提供H-Store存储引擎,对实时写入场景进行了设计优化,支持高吞吐实时写入与更新,同时支持大批量写入场景。
- 极致弹性:计算资源快速伸缩,存储空间按需使用,同时大幅度降低存储成本。历史数据无需再迁移到其他存储介质上,让数据分析更简单,一站式解决金融、互联网等行业快速增长的数据分析需求。
- 数据共享:一份数据承载多样负载,数据实时共享,多写多读的使用模式,在支持不同业务数据快速共享的同时,具备良好的计算资源隔离能力。

- 极致弹性
- 逻辑集群(Virtual Warehouse) 随业务需求并发扩展。
- 多VW间数据实时共享,一份数据承载多样负载,无需拷贝。
- 通过多VW实现吞吐/并发的线性提升,同时具备良好的读写分离、负载隔离能力。
- 湖仓一体
- 数据湖与数据仓库数据无缝混合查询。
- 数据湖分析体验数仓的极致性能和精准管控度。
存算一体与存算分离产品形态对比
|
数仓类型 |
存算一体 |
存算分离 |
||
|---|---|---|---|---|
|
存储介质 |
数据存储在计算节点的本地磁盘(根据选择的存储类型决定存储在SSD云盘或SSD本地盘上)。
|
列存数据存储在华为云对象存储(OBS),计算节点本地磁盘主要作为OBS数据的查询缓存,行存仍然存储在计算节点本地磁盘。 |
||
|
产品优势 |
数据存储在计算节点本地磁盘,性能高。 |
存算分离,计算、存储分层弹性,存储按需使用,计算快速伸缩,无限算力、无限容量。 数据存储在对象存储上,存储成本更低,多VW支持的并发更高。 支持数据共享,支持湖仓一体。 |
||




