
数据湖探索简介
什么是数据湖探索
数据湖探索(Data Lake Insight,简称DLI)是完全兼容Apache Spark、Apache Flink、HetuEngine生态,提供一站式的流处理、批处理、交互式分析的Serverless融合处理分析服务。用户不需要管理任何服务器,即开即用。
DLI支持标准SQL、Spark SQL、Flink SQL,支持多种接入方式,并兼容主流数据格式。数据无需复杂的抽取、转换、加载,使用SQL或程序就可以对云上RDS、DWS、CSS、OBS、ECS自建数据库以及线下数据库的异构数据进行探索。
视频简介
视频介绍什么是数据湖探索服务。
DLI计算引擎
DLI提供了多种计算引擎,Spark引擎、Flink引擎、HetuEngine,分别适用于不同的数据处理场景。
Spark更适合大规模数据的批处理和复杂分析,而Flink则在实时流处理方面表现出色。HetuEngine是高性能交互式SQL分析及数据虚拟化引擎。
- 功能特点:
Spark是用于大规模数据处理的统一分析引擎,聚焦于查询计算分析。
DLI在开源Spark基础上进行了大量的性能优化与服务化改造,不仅兼容Apache Spark生态和接口,性能较开源提升了2.5倍,在小时级即可实现EB级数据查询分析。
DLI的Spark引擎支持大规模数据的批处理和交互式分析,提供高性能的分布式计算能力。
- 适用场景:
- 适用于需要进行大规模数据批处理和复杂数据分析的场景。
- 适合对历史数据进行深度挖掘和分析,例如数据仓库中的数据查询和报表生成。
- 功能特点
- Flink是一款分布式计算引擎,既可以用于批处理,也可以用于流处理。
- DLI在开源Flink基础上进行了特性增强和安全增强,提供了数据处理所需的Stream SQL特性。
- 支持实时流处理,能够处理大规模的实时数据流,支持事件时间处理和状态管理
- 适用场景
- 适用于需要实时处理数据流的场景,例如实时监控系统、实时推荐系统。
- 适合对实时数据进行快速分析和响应,例如金融交易监控、物联网设备数据处理。
- 功能特点
HetuEngine是高性能交互式SQL分析及数据虚拟化引擎,能够与大数据生态无缝融合,实现海量数据的秒级交互式查询。
HetuEngine+Lakeformation能够快速处理大规模数据集的查询请求,迅速和高效从大数据中提取信息,极大地简化了数据的管理和分析流程,提升大数据环境下的索引和查询性能。
了解更多HetuEngine请参考HetuEngine语法参考。
图1 DLI支持HetuEngine+Lakeformation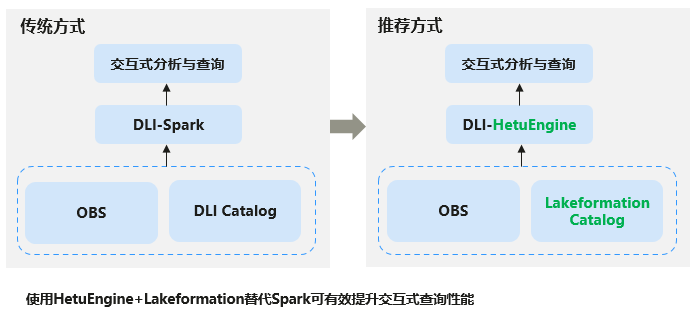
- TB级数据秒级响应:
HetuEngine通过自动优化资源与负载的配比,能够对TB级数据实现秒级响应,极大提升了数据查询的效率。
- Serverless资源开箱即用:
Serverless服务模式无需关注底层配置、软件更新和故障问题,资源易维护,易扩展。
- 多种资源类型满足不同场景业务需求:
共享资源池:按量计费,提供更具性价比的计算资源。
独享资源池:提供独享资源池,满足高性能资源需求。
- 数据生态增强:
HetuEngine+Lakeformation支持与永洪BI、FineBI、DBeaver等主流BI工具的对接,增强数据分析领域的应用能力。
- 实时数据处理性能提升5倍:
HetuEngine+Lakeformation支持Apache Hudi的COW和MOR表。点查性能上相较于开源的Trino提升5倍,可以更快地响应查询请求,提供实时的数据访问。
- TB级数据秒级响应:
- 适用场景
适用于大规模数据存储中进行数据查询和分析。
核心功能
DLI详细的功能清单请参考DLI功能总览。
|
功能分类 |
功能描述 |
|---|---|
|
DLI是基于Serverless架构的数据处理和分析服务 |
DLI是无服务器化的大数据查询分析服务,使用DLI服务您只需为实际使用的弹性计算资源付费,无需维护和管理云服务器。
|
|
DLI支持多种类型的计算引擎 |
完全兼容Apache Spark、Apache Flink、HetuEngine等生态,支持标准SQL、Spark SQL、Flink SQL,兼容CSV、JSON、Parquet和ORC主流数据格式。
|
|
DLI支持多种连接方式 |
DLI提供了多种连接方式满足不同的用户需求和使用场景。 DLI支持的链接方式:
更多DLI连接方式的介绍请参考DLI支持的开发工具。 |
|
DLI支持对接多种数据源的跨源分析 |
|
|
DLI支持的三大基本作业类型 |
|
|
DLI支持存算分离 |
用户将数据存储到OBS后,DLI可以直接和OBS对接进行数据分析。存算分离的架构下,使得存储资源和计算资源可以分开申请和计费,降低了成本并提高了资源利用率。 存算分离场景下,DLI支持OBS在创建桶时数据冗余策略选择单AZ或者多AZ存储,两种存储策略区别如下:
|
|
DLI通过弹性资源池实现对资源的统一的管理和调度 |
弹性资源池后端采用CCE集群的架构,支持异构,对资源进行统一的管理和调度。 详细内容可以参考DLI用户指南的弹性资源池和队列简介。 |
DLI产品结构
DLI的产品结构如下:

DLI产品架构中包括以下核心模块:
|
模块名称 |
功能说明 |
|---|---|
|
生态工具 |
数据湖探索(DLI)通过其强大的Serverless架构和多模引擎支持,能够满足不同行业的多样化需求,推动各行业的数字化转型和创新。 |
|
计算引擎 |
|
|
统一资源管理 |
|
|
统一元数据管理 |
|
|
存储服务 |
使用OBS、数据库存储用于数据分析的结构化或非结构化数据,提供数据的持久化存储服务。 |
|
数据源连接 |
|
|
数据应用 |
支持对接业界主流BI工具、 灵活满足数据展示需求。 |
如何访问DLI
云服务平台提供了Web化的服务管理平台,既可以通过管理控制台和基于HTTPS请求的API(Application programming interface)管理方式来访问DLI,又可以通过JDBC客户端连接DLI服务端。
更多DLI连接方式请参考DLI支持的开发工具。
- API方式
如果用户需要将云平台上的DLI服务集成到第三方系统,用于二次开发,可以使用API方式访问DLI服务。
具体操作请参见《数据湖探索API参考》。
- JDBC
DLI支持使用JDBC连接服务端进行数据查询操作。具体内容请参考《数据湖探索开发指南》。
- 数据治理中心DataArts Studio
数据治理中心DataArts Studio具有数据全生命周期管理、智能数据管理能力的一站式治理运营平台,支持行业知识库智能化建设,支持大数据存储、大数据计算分析引擎等数据底座,帮助企业快速构建从数据接入到数据分析的端到端智能数据系统,消除数据孤岛,统一数据标准,加快数据变现,实现数字化转型。
在DataArts Studio管理中心控制台创建数据连接即可访问DLI,进行数据分析。
关于DataArts Studio的操作指导请参考《数据治理中心产品文档》。




