
工作负载异常:启动容器失败
问题定位
工作负载详情中,若事件中提示“启动容器失败”,请按照如下方式来初步排查原因:
- 登录异常工作负载所在的节点。
- 查看工作负载实例非正常退出的容器ID。
如果节点为docker,请执行docker命令:
docker ps -a | grep $podName
如果节点为containerd,请执行containerd命令:crictl ps -a | grep $podName
- 查看退出容器的错误日志。
如果节点为docker,请执行docker命令:
docker logs $containerID
如果节点为containerd,请执行containerd命令:crictl logs $containerID
根据日志提示修复工作负载本身的问题。
- 查看操作系统的错误日志。
cat /var/log/messages | grep $containerID | grep oom
根据日志判断是否触发了系统OOM。
排查思路
根据具体事件信息确定具体问题原因,如表1所示。
|
日志或事件信息 |
问题原因与解决方案 |
|---|---|
|
日志中存在exit(0) |
容器中无进程。 请调试容器是否能正常运行。 |
|
事件信息:Liveness probe failed: Get http… 日志中存在exit(137) |
健康检查执行失败。 |
|
事件信息: Thin Pool has 15991 free data blocks which is less than minimum required 16383 free data blocks. Create more free space in thin pool or use dm.min_free_space option to change behavior |
磁盘空间不足,需要清理磁盘空间。 |
|
日志中存在OOM字眼 |
内存不足。 |
|
Address already in use |
Pod中容器端口冲突。 |
|
Error: failed to start container "filebeat": Error response from daemon: OCI runtime create failed: container_linux.go:330: starting container process caused "process_linux.go:381: container init caused \"setenv: invalid argument\"": unknown |
负载中挂载了Secret,Secret对应的值没有进行base64加密。 |
除上述可能原因外,还可能存在如下原因,请根据顺序排查。
- 排查项八:容器启动命令配置有误导致
- 排查项九:用户自身业务BUG
- 在ARM架构的节点上创建工作负载时未使用正确的镜像版本,使用正确的镜像版本即可解决该问题。
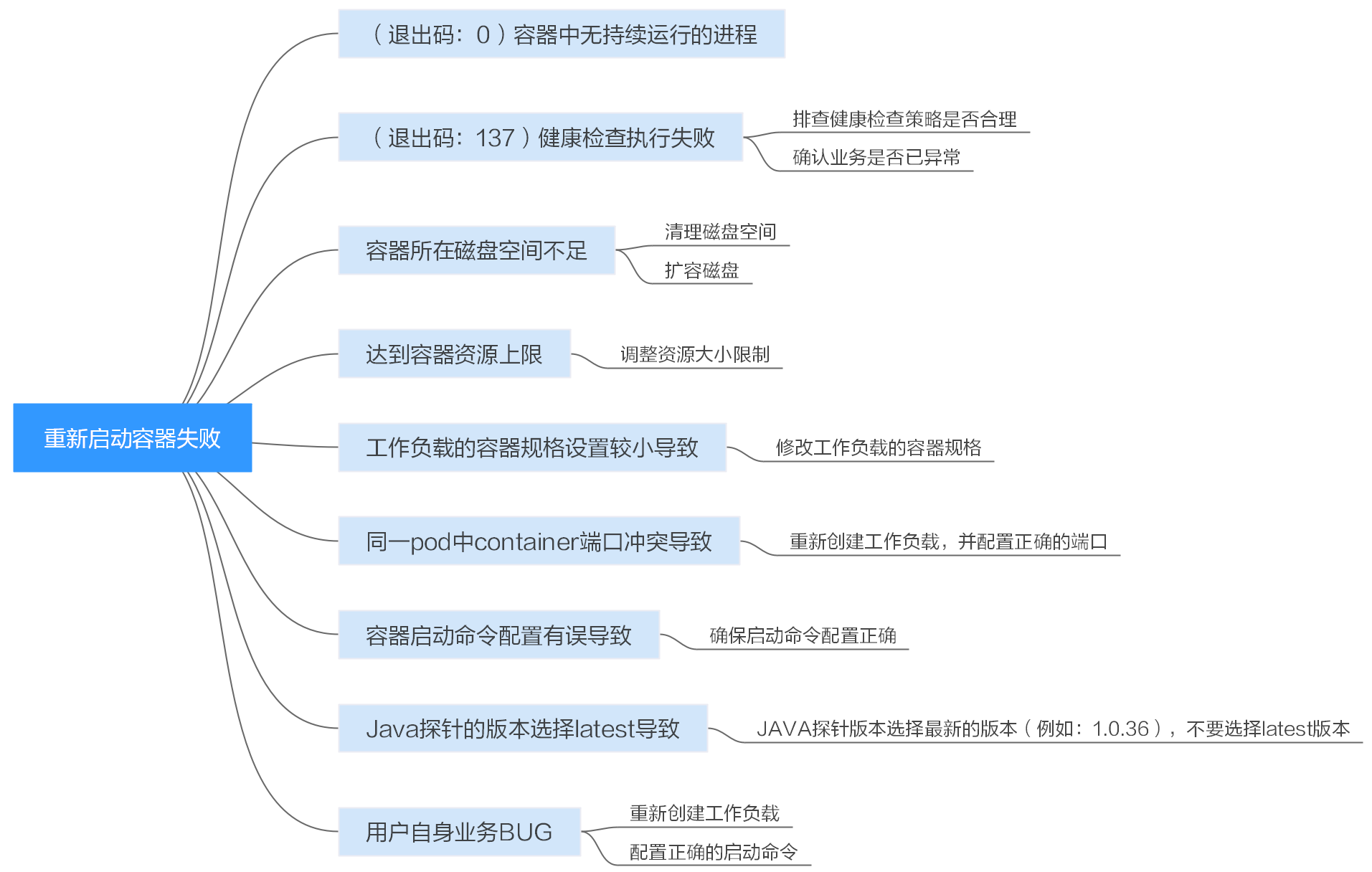
排查项一:(退出码:0)容器中无持续运行的进程
- 登录异常工作负载所在的节点。
- 查看容器状态。
如果节点为docker,请执行docker命令:
docker ps -a | grep $podName
如果节点为containerd,请执行containerd命令:crictl ps -a | grep $podName
如下图所示:

当容器中无持续运行的进程时,会出现exit(0)的状态码,此时说明容器中无进程。
排查项二:(退出码:137)健康检查执行失败
工作负载配置的健康检查会定时检查业务,异常情况下pod会报实例不健康的事件且pod一直重启失败。
工作负载若配置liveness型(工作负载存活探针)健康检查,当健康检查失败次数超过阈值时,会重启实例中的容器。在工作负载详情页面查看事件,若K8s事件中出现“Liveness probe failed: Get http…”时,表示健康检查失败。
解决方案:
请在工作负载详情页中,切换至“容器管理”页签,核查容器的“健康检查”配置信息,排查健康检查策略是否合理或业务是否已异常。
排查项三:容器所在磁盘空间不足
如下磁盘为创建节点时选择的docker专用盘分出来的thinpool盘,以root用户执行lvs命令可以查看当前磁盘的使用量。
Thin Pool has 15991 free data blocks which is less than minimum required 16383 free data blocks. Create more free space in thin pool or use dm.min_free_space option to change behavior

解决方案:
方案一:清理镜像
- 使用containerd容器引擎的节点:
- 查看节点上的本地镜像。
crictl images -v
- 确认镜像无需使用,并通过镜像ID删除无需使用的镜像。
crictl rmi {镜像ID}
- 查看节点上的本地镜像。
- 使用docker容器引擎的节点:
- 查看节点上的本地镜像。
docker images
- 确认镜像无需使用,并通过镜像ID删除无需使用的镜像。
docker rmi {镜像ID}
- 查看节点上的本地镜像。

请勿删除cce-pause等系统镜像,否则可能导致无法正常创建容器。
方案二:扩容磁盘
扩容磁盘的操作步骤如下:
- 在EVS控制台扩容数据盘。
在EVS控制台扩容成功后,仅扩大了云硬盘的存储容量,还需要执行后续步骤扩容逻辑卷和文件系统。
- 登录CCE控制台,进入集群,在左侧选择“节点管理”,单击节点后的“同步云服务器”。
- 登录目标节点。
- 使用lsblk命令查看节点块设备信息。
这里存在两种情况,根据容器存储Rootfs而不同。
排查项四:达到容器资源上限
事件详情中有OOM字样。并且,在日志中也会有记录:
cat /var/log/messages | grep 96feb0a425d6 | grep oom

创建工作负载时,设置的限制资源若小于实际所需资源,会触发系统OOM,并导致容器异常退出。
排查项六:同一pod中container端口冲突导致
- 登录异常工作负载所在的节点。
- 查看工作负载实例非正常退出的容器ID。
如果节点为docker,请执行docker命令:
docker ps -a | grep $podName
如果节点为containerd,请执行containerd命令:crictl ps -a | grep $podName
- 查看退出容器的错误日志。
如果节点为docker,请执行docker命令:
docker logs $containerID
如果节点为containerd,请执行containerd命令:crictl logs $containerID
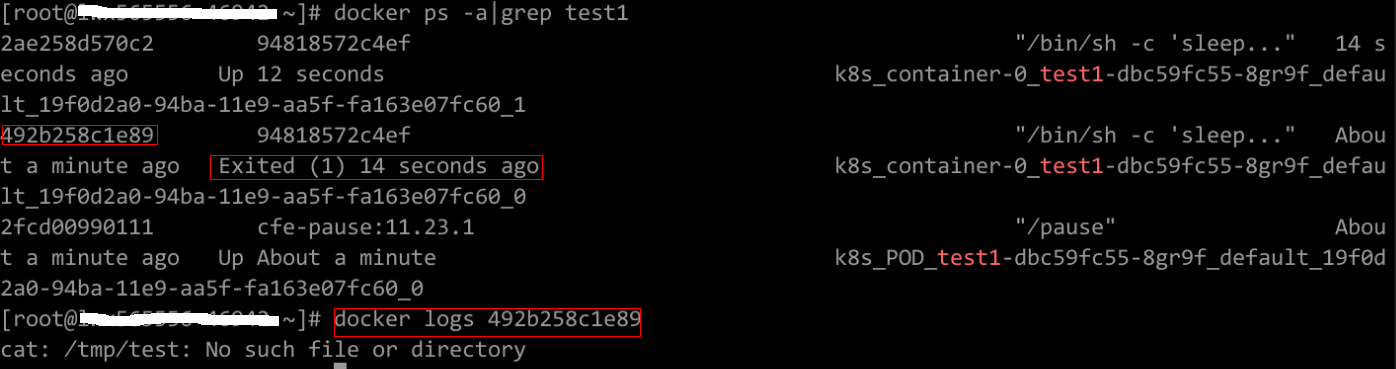
根据日志提示修复工作负载本身的问题。如下图所示,即同一Pod中的container端口冲突导致容器启动失败。
图2 container冲突导致容器启动失败
解决方案:
重新创建工作负载,并配置正确的端口,确保端口不冲突。
排查项七:工作负载挂载的密钥值不符合要求
事件详情中出现以下错误:
Error: failed to start container "filebeat": Error response from daemon: OCI runtime create failed: container_linux.go:330: starting container process caused "process_linux.go:381: container init caused \"setenv: invalid argument\"": unknown
出现以上问题的根因是由于工作负载中挂载了Secret,但Secret对应的值没有进行base64加密。
解决方案:
通过控制台创建Secret,Secret对应的值会自动进行base64加密。
如果通过YAML进行创建,需要手动对密钥值进行base64加密:
# echo -n "待编码内容" | base64
排查项九:用户自身业务BUG
请检查工作负载启动命令是否正确执行,或工作负载本身bug导致容器不断重启。
- 登录异常工作负载所在的节点。
- 查看工作负载实例非正常退出的容器ID。
如果节点为docker,请执行docker命令:
docker ps -a | grep $podName
如果节点为containerd,请执行containerd命令:crictl ps -a | grep $podName
- 查看退出容器的错误日志。
如果节点为docker,请执行docker命令:
docker logs $containerID
如果节点为containerd,请执行containerd命令:crictl logs $containerID
注意:这里的containerID为已退出的容器的ID
图3 容器启动命令配置不正确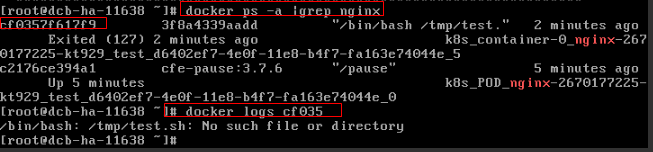
如上图所示,容器配置的启动命令不正确导致容器启动失败。其他错误请根据日志提示修复工作负载本身的BUG问题。
解决方案:
重新创建工作负载,并配置正确的启动命令。




