
Spark应用开发简介
Spark简介
Spark是分布式批处理框架,提供分析挖掘与迭代式内存计算能力,支持多种语言(Scala/Java/Python)的应用开发。 适用以下场景:
- 数据处理(Data Processing):可以用来快速处理数据,兼具容错性和可扩展性。
- 迭代计算(Iterative Computation):支持迭代计算,有效应对多步的数据处理逻辑。
- 数据挖掘(Data Mining):在海量数据基础上进行复杂的挖掘分析,可支持各种数据挖掘和机器学习算法。
- 流式处理(Streaming Processing):支持秒级延迟的流式处理,可支持多种外部数据源。
- 查询分析(Query Analysis):支持标准SQL查询分析,同时提供DSL(DataFrame), 并支持多种外部输入。
本文档重点介绍Spark、Spark SQL和Spark Streaming应用开发指导。
Spark开发接口简介
Spark支持使用Scala、Java和Python语言进行程序开发,由于Spark本身是由Scala语言开发出来的,且Scala语言具有简洁易懂的特性,推荐用户使用Scala语言进行Spark应用程序开发。
按不同的语言分,Spark的API接口如表1所示。
|
功能 |
说明 |
|---|---|
|
Scala API |
提供Scala语言的API,Spark Core、SparkSQL和Spark Streaming模块的常用接口请参见Spark Scala API接口介绍。由于Scala语言的简洁易懂,推荐用户使用Scala接口进行程序开发。 |
|
Java API |
提供Java语言的API,Spark Core、SparkSQL和Spark Streaming模块的常用接口请参见Spark Java API接口介绍。 |
|
Python API |
提供Python语言的API,Spark Core、SparkSQL和Spark Streaming模块的常用接口请参见Spark Python API接口介绍。 |
按不同的模块分,Spark Core和Spark Streaming使用上表中的API接口进行程序开发。而SparkSQL模块,支持CLI或者JDBCServer两种方式访问。其中JDBCServer的连接方式也有Beeline和JDBC客户端代码两种。详情请参见Spark JDBCServer接口介绍。

spark-sql脚本、spark-shell脚本和spark-submit脚本(运行的应用中带SQL操作),不支持使用proxy user参数去提交任务。
基本概念
- RDD
即弹性分布数据集(Resilient Distributed Dataset),是Spark的核心概念。指的是一个只读的,可分区的分布式数据集,这个数据集的全部或部分可以缓存在内存中,在多次计算间重用。
RDD的生成:
- 从HDFS输入创建,或从与Hadoop兼容的其他存储系统中输入创建。
- 从父RDD转换得到新RDD。
- 从数据集合转换而来,通过编码实现。
RDD的存储:
- 用户可以选择不同的存储级别缓存RDD以便重用(RDD有11种存储级别)。
- 当前RDD默认是存储于内存,但当内存不足时,RDD会溢出到磁盘中。
- Dependency(RDD的依赖)
RDD的依赖分别为:窄依赖和宽依赖。
图1 RDD的依赖
- 窄依赖:指父RDD的每一个分区最多被一个子RDD的分区所用。
- 宽依赖:指子RDD的分区依赖于父RDD的所有分区。
窄依赖对优化很有利。逻辑上,每个RDD的算子都是一个fork/join(此join非上文的join算子,而是指同步多个并行任务的barrier):把计算fork到每个分区,算完后join,然后fork/join下一个RDD的算子。如果直接翻译到物理实现,是很不经济的:一是每一个RDD(即使是中间结果)都需要物化到内存或存储中,费时费空间;二是join作为全局的barrier,是很昂贵的,会被最慢的那个节点拖死。如果子RDD的分区到父RDD的分区是窄依赖,就可以实施经典的fusion优化,把两个fork/join合为一个;如果连续的变换算子序列都是窄依赖,就可以把很多个fork/join并为一个,不但减少了大量的全局barrier,而且无需物化很多中间结果RDD,这将极大地提升性能。Spark把这个叫做流水线(pipeline)优化。
- Transformation和Action(RDD的操作)
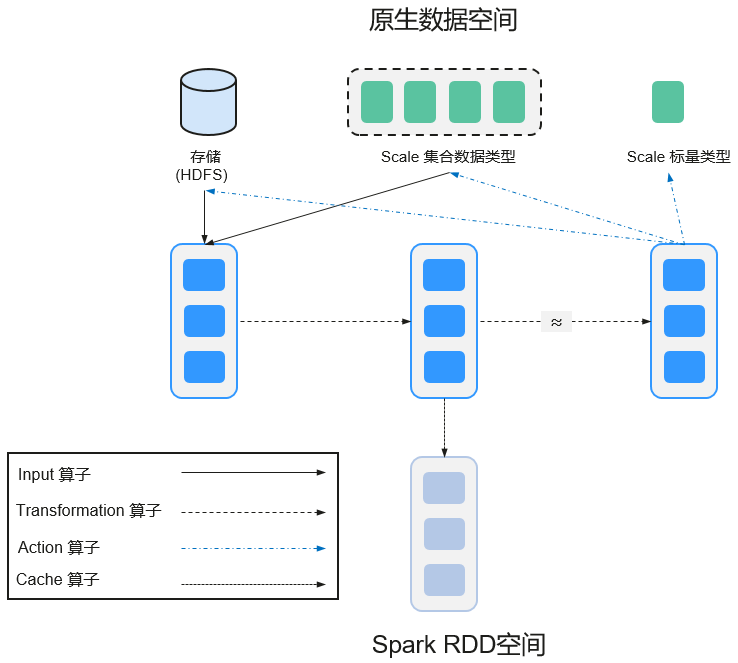
对RDD的操作包含Transformation(返回值还是一个RDD)和Action(返回值不是一个RDD)两种。RDD的操作流程如图2所示。其中Transformation操作是Lazy的,也就是说从一个RDD转换生成另一个RDD的操作不是马上执行,Spark在遇到Transformations操作时只会记录需要这样的操作,并不会去执行,需要等到有Actions操作的时候才会真正启动计算过程进行计算。Actions操作会返回结果或把RDD数据写到存储系统中。Actions是触发Spark启动计算的动因。
RDD看起来与Scala集合类型没有太大差别,但数据和运行模型大相迥异。
val file = sc.textFile("hdfs://...") val errors = file.filter(_.contains("ERROR")) errors.cache() errors.count()- textFile算子从HDFS读取日志文件,返回file(作为RDD)。
- filter算子筛出带“ERROR”的行,赋给errors(新RDD)。filter算子是一个Transformation操作。
- cache算子缓存下来以备未来使用。
- count算子返回errors的行数。count算子是一个Action操作。
Transformation操作可以分为如下几种类型:- 视RDD的元素为简单元素。
输入输出一对多,且结果RDD的分区结构不变,如flatMap(map后由一个元素变为一个包含多个元素的序列,然后展平为一个个的元素)。
输入输出一对一,但结果RDD的分区结构发生了变化,如union(两个RDD合为一个,分区数变为两个RDD分区数之和)、coalesce(分区减少)。
从输入中选择部分元素的算子,如filter、distinct(去除重复元素)、subtract(本RDD有、其他RDD无的元素留下来)和sample(采样)。
- 视RDD的元素为Key-Value对。
对单个RDD做一对一运算,如mapValues(保持源RDD的分区方式,这与map不同);
对单个RDD重排,如sort、partitionBy(实现一致性的分区划分,这个对数据本地性优化很重要);
对单个RDD基于key进行重组和reduce,如groupByKey、reduceByKey;
对两个RDD基于key进行join和重组,如join、cogroup。
后三种操作都涉及重排,称为shuffle类操作。
Action操作可以分为如下几种:
- 生成标量,如count(返回RDD中元素的个数)、reduce、fold/aggregate(返回几个标量)、take(返回前几个元素)。
- 生成Scala集合类型,如collect(把RDD中的所有元素导入Scala集合类型)、lookup(查找对应key的所有值)。
- 写入存储,如与前文textFile对应的saveAsTextFile。
- 还有一个检查点算子checkpoint。当Lineage特别长时(这在图计算中时常发生),出错时重新执行整个序列要很长时间,可以主动调用checkpoint把当前数据写入稳定存储,作为检查点。
- Shuffle
Shuffle是MapReduce框架中的一个特定的phase,介于Map phase和Reduce phase之间,当Map的输出结果要被Reduce使用时,每一条输出结果需要按key哈希,并且分发到对应的Reducer上去,这个过程就是shuffle。由于shuffle涉及到了磁盘的读写和网络的传输,因此shuffle性能的高低直接影响到了整个程序的运行效率。
下图清晰地描述了MapReduce算法的整个流程。
图3 算法流程
概念上shuffle就是一个沟通数据连接的桥梁,实际上shuffle这一部分是如何实现的呢,下面就以Spark为例讲解shuffle在Spark中的实现。
Shuffle操作将一个Spark的Job分成多个Stage,前面的stages会包括一个或多个ShuffleMapTasks,最后一个stage会包括一个或多个ResultTask。
- Spark Application的结构
Spark Application的结构可分为两部分:初始化SparkContext和主体程序。
- 初始化SparkContext:构建Spark Application的运行环境。
new SparkContext(master, appName, [SparkHome], [jars])
参数介绍:
master:连接字符串,连接方式有local、yarn-cluster、yarn-client等。
appName:构建的Application名称。
SparkHome:集群中安装Spark的目录。
jars:应用程序代码和依赖包。
- 主体程序:处理数据
提交Application的描述请参见:https://archive.apache.org/dist/spark/docs/3.3.1/submitting-applications.html。
- 初始化SparkContext:构建Spark Application的运行环境。
- Spark shell命令
Spark基本shell命令,支持提交Spark应用。命令为:
./bin/spark-submit \ --class <main-class> \ --master <master-url> \ ... # other options <application-jar> \ [application-arguments]
参数解释:
--class:Spark应用的类名。
--master:Spark用于所连接的master,如yarn-client,yarn-cluster等。
application-jar:Spark应用的jar包的路径。
application-arguments:提交Spark应用的所需要的参数(可以为空)。
- Spark JobHistory Server
用于监控正在运行的或者历史的Spark作业在Spark框架各个阶段的细节以及提供日志显示,帮助用户更细粒度地去开发、配置和调优作业。
Spark SQL常用概念
DataSet
DataSet是一个由特定域的对象组成的强类型集合,可通过功能或关系操作并行转换其中的对象。 每个Dataset还有一个非类型视图,即由多个列组成的DataSet,称为DataFrame。
DataFrame是一个由多个列组成的结构化的分布式数据集合,等同于关系数据库中的一张表,或者是R/Python中的data frame。DataFrame是Spark SQL中的最基本的概念,可以通过多种方式创建,例如结构化的数据集、Hive表、外部数据库或者是RDD。
Spark Streaming常用概念
Dstream
DStream(又称Discretized Stream)是Spark Streaming提供的抽象概念。
DStream表示一个连续的数据流,是从数据源获取或者通过输入流转换生成的数据流。从本质上说,一个DStream表示一系列连续的RDD。RDD是一个只读的、可分区的分布式数据集。
DStream中的每个RDD包含了一个区间的数据。如图4所示。

应用到DStream上的所有算子会被转译成下层RDD的算子操作,如图5所示。这些下层的RDD转换会通过Spark引擎进行计算。DStream算子隐藏大部分的操作细节,并且提供了方便的High-level API给开发者使用。

Structured Streaming常用概念
- Input Source
输入数据源,数据源需要支持根据offset重放数据,不同的数据源有不同的容错性。
- Sink
数据输出,Sink要支持幂等性写入操作,不同的sink有不同的容错性。
- outputMode
结果输出模式,当前支持3种输出模:
- Complete Mode:整个更新的结果集都会写入外部存储。整张表的写入操作将由外部存储系统的连接器完成。
- Append Mode:当时间间隔触发时,只有在Result Table中新增加的数据行会被写入外部存储。这种方式只适用于结果集中已经存在的内容不希望发生改变的情况下,如果已经存在的数据会被更新,不适合适用此种方式。
- Update Mode:当时间间隔触发时,只有在Result Table中被更新的数据才会被写入外部存储系统。注意,和Complete Mode方式的不同之处是不更新的结果集不会写入外部存储。
- Trigger
输出触发器,当前支持以下几种trigger:
- 默认:以微批模式执行,每个批次完成后自动执行下个批次。
- 固定间隔:固定时间间隔执行。
- 一次执行:只执行一次query,完成后退出。
- 连续模式:实验特性,可实现低至1ms延迟的流处理(推荐100ms)。
Structured Streaming支持微批模式和连续模式。微批模式不能保证对数据的低延迟处理,但是在相同时间下有更大的吞吐量;连续模式适合毫秒级的数据处理延迟,当前暂时还属于实验特性。
在当前版本中,若需要使用流流Join功能,则output模式只能选择append模式。






