
编译并调测Flink应用
操作场景
在程序代码完成开发后,建议您上传至Linux客户端环境中运行应用。使用Scala或Java语言开发的应用程序在Flink客户端的运行步骤是一样的。

基于YARN集群的Flink应用程序不支持在Windows环境下运行,只支持在Linux环境下运行。
操作步骤
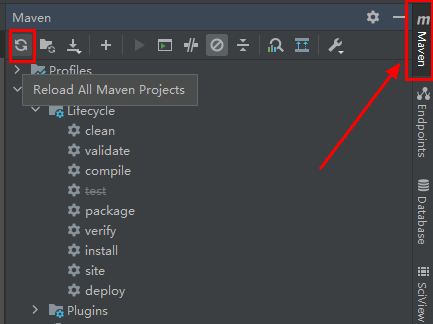
- 在IntelliJ IDEA中,单击IDEA右边Maven窗口的“Reload All Maven Projects”,进行Maven项目依赖import。
图1 Reload projects
- 编译运行程序。
编译方式有以下两种:
- 方法一:
- 选择“Maven > 样例工程名称 > Lifecycle > clean”,双击“clean”运行maven的clean命令。
- 选择“Maven > 样例工程名称 > Lifecycle > install”,双击“install”运行maven的install命令。
图2 maven工具clean和install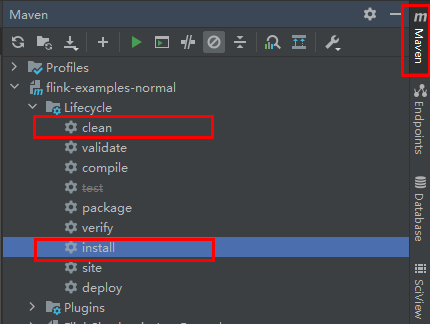
- 方法二:在IDEA的下方Terminal窗口进入“pom.xml”所在目录,手动输入mvn clean install命令进行编译。
图3 idea terminal输入"mvn clean install"

- 方法一:
- 编译完成,打印“BUILD SUCCESS”,生成target目录,获取target目录下的jar包。
图4 编译完成

- 将3中生成的Jar包(如FlinkStreamJavaExample.jar)复制到Linux环境的Flink运行环境下(即Flink客户端),如“/opt/client”。然后在该目录下创建“conf”目录,将需要的配置文件复制至“conf”目录,具体操作请参考准备运行环境,运行Flink应用程序。
在Linux环境中运行Flink应用程序,需要先启动Flink集群。在Flink客户端下执行yarn session命令,启动flink集群。执行命令例如:
bin/yarn-session.sh -jm 1024 -tm 4096
- 执行yarn-session.sh之前,应预先将Flink应用程序的运行依赖包复制到客户端目录{client_install_home}/Flink/flink/lib下,应用程序运行依赖包请参考样例工程运行依赖包参考信息。
- 不同的样例工程使用的依赖包可能会有冲突,在运行新的样例工程时需删除旧的样例工程复制至客户端目录{client_install_home}/Flink/flink/lib下的依赖包。
- 执行yarn-session.sh之前,请在客户端安装目录执行source bigdata_env命令。
- yarn-session.sh命令需进入“/Flink客户端安装目录/Flink/flink”目录执行,例如“/opt/client/Flink/flink”。
- 在Flink任务运行过程中禁止重启HDFS服务或者重启所有DataNode实例,否则可能会导致任务失败,并可能导致应用部分临时数据无法清空。
- 请确保Jar包和配置文件的用户权限与Flink客户端一致,例如都是omm用户,且权限为755。
- MRS 3.2.1及以后版本使用-tm指定taskmanager内存不能小于4096MB。
- 运行DataStream(Scala和Java)样例程序。
在终端另开一个窗口,进入Flink客户端目录,调用bin/flink run脚本运行代码。
- Java
bin/flink run --class com.huawei.bigdata.flink.examples.FlinkStreamJavaExample /opt/client/FlinkStreamJavaExample.jar --filePath /opt/log1.txt,/opt/log2.txt --windowTime 2
- Scala
bin/flink run --class com.huawei.bigdata.flink.examples.FlinkStreamScalaExample /opt/client/FlinkStreamScalaExample.jar --filePath /opt/log1.txt,/opt/log2.txt --windowTime 2
“log1.txt”、“log2.txt”需放在每个部署了Yarn NodeManager实例的节点上,权限为755。
表1 参数说明 参数名称
说明
<filePath>
指本地文件系统中文件路径,每个节点都需要放一份/opt/log1.txt和/opt/log2.txt。可以默认,也可以设置。
<windowTime>
指窗口时间大小,以分钟为单位。可以默认,也可以设置。
- Java
- 运行向Kafka生产并消费数据样例程序(Scala和Java语言)。
bin/flink run --class com.huawei.bigdata.flink.examples.WriteIntoKafka /opt/client/FlinkKafkaJavaExample.jar <topic> <bootstrap.servers> [security.protocol] [sasl.kerberos.service.name] [ssl.truststore.location] [ssl.truststore.password]
消费数据的执行命令启动程序。bin/flink run --class com.huawei.bigdata.flink.examples.ReadFromKafka /opt/client/FlinkKafkaJavaExample.jar <topic> <bootstrap.servers> [security.protocol] [sasl.kerberos.service.name] [ssl.truststore.location] [ssl.truststore.password]
表2 参数说明 参数名称
说明
是否必须配置
topic
表示Kafka主题名。
是
bootstrap.server
表示broker集群ip/port列表。
是
security.protocol
运行参数可以配置为PLAINTEXT(可不配置)/SASL_PLAINTEXT/SSL/SASL_SSL四种协议,分别对应FusionInsight Kafka集群的21005/21007/21008/21009端口。
- 如果配置了SASL,则必须配置sasl.kerberos.service.name为kafka,并在conf/flink-conf.yaml中配置security.kerberos.login相关配置项。
- 如果配置了SSL,则必须配置ssl.truststore.location和ssl.truststore.password,前者表示truststore的位置,后者表示truststore密码。
否
说明:- 该参数未配置时为非安全Kafka。
- 如果需要配置SSL,truststore.jks文件生成方式可参考“Kafka开发指南 > 客户端SSL加密功能使用说明”章节。
四种类型实际命令示例,以ReadFromKafka为例,集群域名为“HADOOP.COM”:
- 命令1:
bin/flink run --class com.huawei.bigdata.flink.examples.ReadFromKafka /opt/client/FlinkKafkaJavaExample.jar --topic topic1 --bootstrap.servers 10.96.101.32:9092
- 命令2:
bin/flink run --class com.huawei.bigdata.flink.examples.ReadFromKafka /opt/client/FlinkKafkaJavaExample.jar --topic topic1 --bootstrap.servers 10.96.101.32:21005 --security.protocol PLAINTEXT --sasl.kerberos.service.name kafka --kerberos.domain.name hadoop.hadoop.com
- 命令3:
bin/flink run --class com.huawei.bigdata.flink.examples.ReadFromKafka /opt/client/FlinkKafkaJavaExample.jar --topic topic1 --bootstrap.servers 10.96.101.32:9093 --security.protocol SSL --ssl.truststore.location /home/truststore.jks --ssl.truststore.password xxx
- 命令4:
bin/flink run --class com.huawei.bigdata.flink.examples.ReadFromKafka /opt/client/FlinkKafkaJavaExample.jar --topic topic1 --bootstrap.servers 10.96.101.32:21005 --security.protocol PLAINTEXT --sasl.kerberos.service.name kafka --ssl.truststore.location config/truststore.jks --ssl.truststore.password xxx --kerberos.domain.name hadoop.hadoop.com
- 运行异步Checkpoint机制样例程序(Scala和Java语言)。
为了丰富样例代码,Java版本使用了Processing Time作为数据流的时间戳,而Scala版本使用Event Time作为数据流的时间戳。具体执行命令参考如下:
将Checkpoint的快照信息保存到HDFS。- Java
bin/flink run --class com.huawei.bigdata.flink.examples.FlinkProcessingTimeAPIMain /opt/client/FlinkCheckpointJavaExample.jar --chkPath hdfs://hacluster/flink/checkpoint/
- Scala
bin/flink run --class com.huawei.bigdata.flink.examples.FlinkEventTimeAPIChkMain /opt/client/FlinkCheckpointScalaExample.jar --chkPath hdfs://hacluster/flink/checkpoint/
- Checkpoint源文件路径:flink/checkpoint/fd5f5b3d08628d83038a30302b611/chk-X/4f854bf4-ea54-4595-a9d9-9b9080779ffe
fd5f5b3d08628d83038a30302b611 //以jobID命名的第二层目录。
chk-X // "X"为checkpoint编号,第三层目录。
4f854bf4-ea54-4595-a9d9-9b9080779ffe //checkpoint源文件。
- Flink在集群模式下checkpoint将文件放到HDFS,本地路径只支持Flink的local模式,便于调测。
- Java
- 运行Pipeline样例程序。
- Java
- 启动发布者Job
bin/flink run -p 2 --class com.huawei.bigdata.flink.examples.TestPipelineNettySink /opt/client/FlinkPipelineJavaExample.jar
- 启动订阅者Job1
bin/flink run --class com.huawei.bigdata.flink.examples.TestPipelineNettySource1 /opt/client/FlinkPipelineJavaExample.jar
- 启动订阅者Job2
bin/flink run --class com.huawei.bigdata.flink.examples.TestPipelineNettySource2 /opt/client/FlinkPipelineJavaExample.jar
- 启动发布者Job
- Scala
- 启动发布者Job
bin/flink run -p 2 --class com.huawei.bigdata.flink.examples.TestPipeline_NettySink /opt/client/FlinkPipelineScalaExample.jar
- 启动订阅者Job1
bin/flink run --class com.huawei.bigdata.flink.examples.TestPipeline_NettySource1 /opt/client/FlinkPipelineScalaExample.jar
- 启动订阅者Job2
bin/flink run --class com.huawei.bigdata.flink.examples.TestPipeline_NettySource2 /opt/client/FlinkPipelineScalaExample.jar
- 启动发布者Job
- Java
- 运行Stream SQL Join样例程序。
- Java
- 启动程序向Kafka生产,Kafka配置可参考运行向Kafka生产并消费数据样例程序
bin/flink run --class com.huawei.bigdata.flink.examples.WriteIntoKafka /opt/client/FlinkStreamSqlJoinExample.jar --topic topic-test --bootstrap.servers xxx.xxx.xxx.xxx:9092
- 在集群内任一节点启动netcat命令,等待应用程序连接。
netcat -l -p 9000
若回显提示“command not found”,请用户自行安装netcat工具后再次执行。
- 启动程序接受Socket数据,并执行联合查询。
bin/flink run --class com.huawei.bigdata.flink.examples.SqlJoinWithSocket /opt/client/FlinkStreamSqlJoinExample.jar --topic topic-test --bootstrap.servers xxx.xxx.xxx.xxx:9092 --hostname xxx.xxx.xxx.xxx --port 9000
- 启动程序向Kafka生产,Kafka配置可参考运行向Kafka生产并消费数据样例程序
- Scala(适用于MRS 3.3.0及以后版本)
- 启动程序向Kafka生产。Kafka配置可参考运行向Kafka生产并消费数据样例程序。
bin/flink run --class com.huawei.bigdata.flink.examples.WriteIntoKafka /opt/client/FlinkStreamSqlJoinScalaExample.jar --topic topic-test --bootstrap.servers xxx.xxx.xxx.xxx:9092 - 在集群内任一节点启动netcat命令,等待应用程序连接。
netcat -l -p 9000
- 启动程序接受Socket数据,并执行联合查询。
bin/flink run --class com.huawei.bigdata.flink.examples.SqlJoinWithSocket /opt/client/FlinkStreamSqlJoinScalaExample.jar --topic topic-test --bootstrap.servers xxx.xxx.xxx.xxx:9092 --hostname xxx.xxx.xxx.xxx --port 9000
- 启动程序向Kafka生产。Kafka配置可参考运行向Kafka生产并消费数据样例程序。
- Java
- 运行Flink HBase样例程序(MRS 3.2.0及以后版本)
- yarn-session方式
- 启动Flink集群。
./bin/yarn-session.sh -jm 1024 -tm 1024
- 运行Flink程序,并输入参数。
bin/flink run --class com.huawei.bigdata.flink.examples.WriteHBase /opt/client1/Flink/flink/FlinkHBaseJavaExample-xxx.jar --tableName xxx --confDir xxx bin/flink run --class com.huawei.bigdata.flink.examples.ReadHBase /opt/client1/Flink/flink/FlinkHBaseJavaExample-xxx.jar --tableName xxx --confDir xxx
- 启动Flink集群。
- yarn-cluster方式
bin/flink run -m yarn-cluster --class com.huawei.bigdata.flink.examples.WriteHBase /opt/client1/Flink/flink/FlinkHBaseJavaExample-xxx.jar --tableName xxx --confDir xxx bin/flink run -m yarn-cluster --class com.huawei.bigdata.flink.examples.ReadHBase /opt/client1/Flink/flink/FlinkHBaseJavaExample-xxx.jar --tableName xxx --confDir xxx
- yarn-session方式
- 运行Flink Hudi样例程序(MRS 3.2.1及以后版本)
- yarn-session方式
- 启动Flink集群。
./bin/yarn-session.sh -jm 1024 -tm 4096
- 运行Flink程序,并输入参数。
./bin/flink run --class com.huawei.bigdata.flink.examples.WriteIntoHudi /opt/test.jar --hudiTableName hudiSinkTable --hudiPath hdfs://hacluster/tmp/flinkHudi/hudiTable ./bin/flink run --class com.huawei.bigdata.flink.examples.ReadFromHudi /opt/test.jar --hudiTableName hudiSourceTable --hudiPath hdfs://hacluster/tmp/flinkHudi/hudiTable --read.start-commit xxx
- 启动Flink集群。
- yarn-cluster方式
./bin/flink run -m yarn-cluster --class com.huawei.bigdata.flink.examples.WriteIntoHudi /opt/test.jar --hudiTableName hudiSinkTable --hudiPath hdfs://hacluster/tmp/flinkHudi/hudiTable ./bin/flink run -m yarn-cluster --class com.huawei.bigdata.flink.examples.ReadFromHudi /opt/test.jar --hudiTableName hudiSourceTable --hudiPath hdfs://hacluster/tmp/flinkHudi/hudiTable --read.start-commit xxx
- yarn-session方式
- 运行RestAPI创建租户样例程序,以TestCreateTenants程序为例。
- yarn-session方式
- 启动Flink集群。
./bin/yarn-session.sh -jm 1024 -tm 4096
- 运行Flink程序,并输入参数。
./bin/flink run --class com.huawei.bigdata.flink.examples.TestCreateTenants /opt/client/FlinkRESTAPIJavaExample-xxx.jar --hostName xx-xx-xx-xx
- 启动Flink集群。
- yarn-cluster方式
./bin/flink run -m yarn-cluster -yjm 1024 -ytm 4096 --class com.huawei.bigdata.flink.examples.TestCreateTenants /opt/client/FlinkRESTAPIJavaExample-xxx.jar --hostName xx-xx-xx-xx
- yarn-session方式
- 运行Flink Jar作业提交SQL任务(适用于MRS 3.2.1及以后版本)
- yarn-session方式
- 启动Flink集群。
./bin/yarn-session.sh -jm 1024 -tm 4096
- 运行Flink程序,并输入参数。
bin/flink run -d --class com.huawei.mrs.FlinkSQLExecutor /opt/flink-sql-xxx.jar --sql ./sql/datagen2kafka.sql
- 启动Flink集群。
- yarn-cluster方式
bin/flink run -m yarn-cluster -yjm 1024 -ytm 4096 -d --class com.huawei.mrs.FlinkSQLExecutor /opt/flink-sql-xxx.jar --sql ./sql/datagen2kafka.sql
- yarn-session方式




