
更新时间:2025-05-29 GMT+08:00
IMPDP TABLE PREPARE
功能描述
导入表的准备阶段。
语法格式
IMPDP TABLE PREPARE SOURCE = 'directory' OWNER = user;
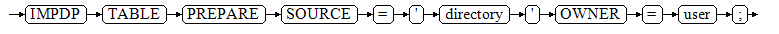
参数说明
- directory:导入的表的数据源目录。
- user:导入后表的属主。
示例
--IMPDP TABLE PREPARE语法用于细粒度备份恢复,由备份恢复工具调用,用户直接调用可能提示目录不存在等报错,不推荐用户直接调用该SQL。
gaussdb=# IMPDP TABLE PREPARE SOURCE = '/data1/impdp/table0' OWNER=admin;
父主题: I




