
GPU Pod监控指标采集及Grafana仪表盘搭建
应用场景
2.1.30、2.7.46及以上版本的CCE AI套件(NVIDIA GPU)插件中新增GPU Pod监控指标,包括gpu_pod_core_percentage_total、gpu_pod_core_percentage_used、gpu_pod_memory_total和gpu_pod_memory_used4个指标,能够全面监控整卡GPU负载和GPU虚拟化负载的GPU算力和显存使用情况。您可以基于GPU Pod监控指标构建不同维度(如Pod维度、节点维度等)的监控看板,以便及时了解集群相关信息。更多GPU监控指标信息,请参见GPU监控指标说明。
当前云原生监控插件暂不支持自动采集这些指标。若需在Grafana仪表盘中查看,需手动配置云原生监控插件采集相关数据,并构建相应的仪表盘。本文将以Pod维度为例,介绍如何进行GPU Pod监控指标的采集以及相关仪表盘的搭建。
前提条件
- 集群中已有正常运行的NVIDIA GPU节点。
- 集群中已安装CCE AI 套件 (NVIDIA GPU),且版本在2.1.30、2.7.46及以上,具体安装步骤请参见CCE AI套件(NVIDIA GPU)。
- 集群中已安装云原生监控插件和Grafana插件,并且Grafana插件已启用“公网访问”,具体安装步骤请参见云原生监控插件和安装Grafana。
- 如果您需使用AOM数据源,请在云原生监控插件中启用“监控数据上报至AOM服务”,并在Grafana插件中启用“数据源对接AOM”,同时确保两者选择的AOM实例一致。
- 如果您需使用Prometheus数据源,请在云原生监控插件中开启“本地存储模式”。
操作流程
| 操作步骤 | 步骤说明 | 费用说明 |
|---|---|---|
| 当前云原生监控插件暂不支持自动采集GPU Pod监控指标。如果您需要通过监控中心查看GPU Pod监控指标,需要手动配置云原生监控插件以采集相关指标。 | 如果云原生监控插件开启“监控数据上报至AOM服务”,则将GPU Pod监控指标上传至AOM会涉及一定费用,具体请参见价格详情。 | |
| 在Grafana可视化界面中配置GPU Pod监控仪表盘时,需使用AOM数据源或Prometheus数据源,此时需要确保数据源与Grafana的连通性。 | 不涉及费用。 | |
| 以Pod维度为例,构建GPU Pod监控仪表盘。 | 不涉及费用。 |
步骤一:采集GPU Pod监控指标
当前云原生监控插件暂不支持自动采集GPU Pod监控指标。如果您需要通过监控中心查看GPU Pod监控指标,需要手动配置云原生监控插件以采集相关指标。
- 登录CCE控制台,单击集群名称进入集群。
- 在左侧导航栏中,单击“集群 > 配置中心”。在右侧页面中,切换至“监控运维配置”页签。在“监控配置 > 采集配置 > 系统预置采集”中,单击“立即开启”,并在出现的对话框中单击“确定”。如果您已经开启“ 系统预置采集”,则此步骤可以跳过。

系统预置采集用于预置云原生监控插件的采集策略。开启系统预置采集功能后,系统预置的ServiceMonitor和PodMonitor将被删除,您手动创建的采集配置不会受到影响。开启后,您可以更轻松地对系统预置的采集任务进行配置。
图1 开启系统预置采集
- 开启后,云原生监控插件自动升级,请在当前页面的“监控配置 > 指标配置”中单击“立即刷新”获取数据。刷新后,在“监控配置 > 采集配置 > 系统预置采集”中,单击“管理”。 在弹出的“采集配置”页面中单击搜索框,选择“任务名称”,在下拉框中单击“nvidia-gpu-device-plugin”。在查询结果的“指标采集列”,单击“编辑白名单”。图2 编辑白名单

- 在“指标采集白名单”页面左上角,单击“添加指标”。依次添加需要采集的四个指标:gpu_pod_core_percentage_total,gpu_pod_core_percentage_used,gpu_pod_memory_total和gpu_pod_memory_used。添加完成过后,请关闭当前页面。
步骤二:配置Grafana数据源
Grafana支持配置AOM数据源或Prometheus数据源:
- 使用AOM数据源:Grafana将自动生成“prometheus-aom”数据源,需确保其与Grafana的连通性正常。
- 使用Prometheus数据源:可直接使用Grafana自带的“prometheus”数据源,此时也需确保该数据源与Grafana的连通性正常。
如果需要AOM数据源,请确保当前集群中的云原生监控插件已开启“监控数据上报至AOM服务”,Grafana插件已启用“数据源对接AOM”,并且两个插件对接同一个AOM实例。Grafana插件开启“数据源对接AOM”后,Grafana可视化界面将自动生成“prometheus-aom”数据源。请确保该数据源的连通性,连通测试通过即可正常使用AOM数据源。
- 在集群左侧导航栏中,单击“集群 > 插件”。在右侧插件列表中,在Grafana插件模块单击“访问”,进入Grafana可视化界面。
- 首次访问Grafana可视化界面,需要输入用户名和密码,默认用户名与密码均为admin。输入用户名和密码后,您需要根据界面提示重置密码。
- 在Grafana可视化界面左上角单击
 ,单击“Connections”左侧的
,单击“Connections”左侧的 ,单击“Data sources”,进入Data sources界面。
,单击“Data sources”,进入Data sources界面。 - 在数据源列表中,单击“prometheus-aom”。在“prometheus-aom”数据源页面底部单击“Save&test”,测试数据源是否连通。若提示“Successfully queried the Prometheus API”,则说明连通测试通过。 图3 连通测试通过

使用Prometheus数据源时,需确保已开启云原生监控插件的“本地存储模式”。Grafana自带的“prometheus”数据源可以直接对接本地存储模式的Prometheus数据源,请确保数据源的连通性,连通性测试通过后即可正常使用。
- 在集群左侧导航栏中,单击“集群 > 插件”。在右侧插件列表中,查找Grafana插件并在该插件模块中单击“访问”,进入Grafana可视化界面。
- 首次访问Grafana可视化界面,需要输入用户名和密码,默认用户名与密码均为admin。输入用户名和密码后,您需要根据界面提示重置密码。
- 在Grafana可视化界面左上角单击,单击“Connections”左侧的 ,单击“Data sources”,进入Data sources界面。
- 在数据源列表中,单击“prometheus”。在“prometheus”数据源页面底部单击“Save&test”,测试数据源是否连通。若提示“Successfully queried the Prometheus API”,则说明连通测试通过。 图4 连通测试通过

步骤三:配置Grafana Dashboard
Grafana Dashboard是一个用于集中监控和可视化数据的仪表盘工具,支持多种数据源,您可以通过图表、图形和告警功能实时掌握系统状态和业务指标。基于GPU Pod监控指标,Grafana可以搭建Pod维度、GPU卡维度、节点维度以及集群维度的监控仪表盘。本文以Pod维度为例,向您介绍如何配置Grafana Dashboard。其他维度的PromQL语句已在PromQL语句中给出,您可以参考以下步骤配置相关仪表盘。
- 新建一个Grafana Dashboard,用于展示GPU Pod监控指标。
- 在Grafana可视化界面单击
 ,打开左侧菜单栏。单击“Dashboards”。在“Dashboards”页面右上角,单击“New”,下拉菜单中单击“New dashboard”。 图5 创建New dashboard
,打开左侧菜单栏。单击“Dashboards”。在“Dashboards”页面右上角,单击“New”,下拉菜单中单击“New dashboard”。 图5 创建New dashboard
- 在“New dashboard”页面右上角,单击
 ,对Dashboard进行命名操作。在“Title”中输入“GPU Pod Dashboard”,在右上角单击“Save dashboard”。在弹出的“Save dashboard”页面中单击“Save”。本文将Dashboard命名为“GPU Pod Dashboard”,您可以自定义。 图6 对仪表盘重命名
,对Dashboard进行命名操作。在“Title”中输入“GPU Pod Dashboard”,在右上角单击“Save dashboard”。在弹出的“Save dashboard”页面中单击“Save”。本文将Dashboard命名为“GPU Pod Dashboard”,您可以自定义。 图6 对仪表盘重命名
- 在Grafana可视化界面单击
- 在Grafana Dashboard中配置变量。 Grafana变量是Grafana中一项强大的功能,可用于创建动态、可配置和模板化的仪表板。 变量值可以在仪表板中动态更改,从而修改仪表板的查询和面板,无需为每个服务或指标都创建单独的仪表板。表1提供了本文中需要配置的变量信息,本步骤将以“instance”为例,向您介绍如何在Grafana Dashboard中配置变量。您可以参考“instance”的示例依次增加表1中变量。
表1 变量信息 变量名
说明
PromQL语句
instance
表示dp的Pod实例名称,用于筛选出GPU节点。
label_values(up{job=~".*nvidia-gpu-device-plugin.*"},instance)
gpu_index
表示GPU卡编号,如0、1、2。
label_values(cce_gpu_temperature{instance=~"$instance"}, gpu_index)
namespace
表示GPU负载所在的命名空间。
label_values(gpu_pod_memory_used{instance=~"$instance",gpu_index=~"$gpu_index"}, namespace)
pod
表示GPU负载中Pod的名称。
label_values(gpu_pod_memory_used{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace"}, pod)
- 在“New dashboard”页面右上角,单击
 。在“Settings”页面,切换至“Variables”页签,单击“Add variable”,增加变量。 图7 增加变量
。在“Settings”页面,切换至“Variables”页签,单击“Add variable”,增加变量。 图7 增加变量
- 配置“Select variable type”和“General”相关信息,具体请参见图8和表2。
表2 配置Select variable type和General信息 参数
示例
说明
Select variable type
Query
用于选择变量类型,由于表1中的变量值需要通过数据源查询获取,因此选择Query类型。
Name
instance
用于设置变量名。
- 配置“Query options”信息,具体请参见图9和表3。
表3 配置Query options信息 参数
示例
说明
Query type
Classic query
用于选择数据的查询方式和展示形式。
本示例中选择Classic query。Classic query是一种基于文本输入的查询方式,可以直接编写查询语句(如 PromQL)来获取数据。
Classic Query
label_values(up{job=~".*nvidia-gpu-device-plugin.*"},instance)
请输入Prometheus查询语句。
本示例的查询语句表示:从Prometheus中筛选出job标签包含nvidia-gpu-device-plugin的up指标,提取这些指标的instance标签值。
Sort
Alphabetical (asc)
用于选择变量值的排序方式,您可以根据需要进行选择。
本示例中选择Alphabetical (asc),表示按字母顺序升序排序。
Refresh
On time range change
用于控制变量值的更新时间,决定变量值何时从数据源重新获取并更新,您可以根据需要进行选择。
本示例中选择On time range change,表示当Dashboard的时间窗发生变化时,变量的值会重新从数据源获取。
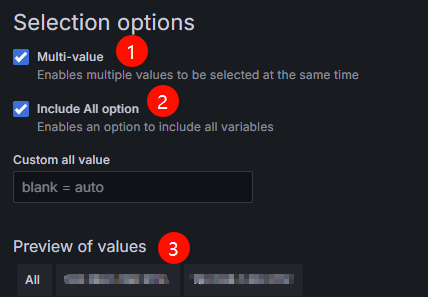
- 配置“Selection options”信息,具体请参见图10和表4
表4 配置Selection options信息 参数
示例
说明
Multi-value
勾选
启用后,允许用户同时选择变量的多个值。
Include All option
勾选
启用后,变量下拉菜单中会添加“All”选项,允许一键选择所有值。
Preview of values
-
表示instance的变量值,即dp的Pod实例名称
请按照以上步骤,依次添加表1中变量。变量配置完成后,变量右侧
 会提示该变量暂未被引用。后续在配置监控面板中,将会引用此处配置的4个变量。
会提示该变量暂未被引用。后续在配置监控面板中,将会引用此处配置的4个变量。 - 在右上角单击“Save dashboard”。在弹出的“Save dashboard”页面中,单击“Save”,保存配置的变量信息。
- 在“New dashboard”页面右上角,单击
- 配置Grafana监控面板。
本文以4个监控面板为例,展示不同类型监控面板搭建过程,具体请参见表5。您可以根据需求选择搭建不同的监控面板,具体请参见表6。
表5 监控面板信息 监控面板名称
说明
监控面板类型
Pod总数
表示集群中非共享模式的所有GPU负载的Pod数量总和。
数据面板(Stat)
Pod详情
以表格形式汇总Pod的名称、显存分配量和显存使用量等信息。
表格面板(Table)
Pod显存分配量
表示GPU负载中Pod实际分配到的显存量。
柱状图面板(Bar gauge)
Pod显存分配量使用率
表示GPU负载中Pod实际分配量的使用率。
仪表盘面板(Gauge)
数据面板示例--Pod总数
- 在当前页面左上方路径中,单击“GPU Pod Dashboard”,右侧单击“Add”,并在下拉菜单中单击“Visualization”,创建一个新面板。
- 在“Edit panel”页面左下方“Query”页签中,“Data source”选择步骤二:配置Grafana数据源中配置的数据源。单击“A”左侧
 ,在展开内容的右侧单击“Code”,并在“Metrics browser”中输入对应的PromQL语句,用于收集数据。具体的PromQL语句请参见表6。 图11 填写PromQL语句
,在展开内容的右侧单击“Code”,并在“Metrics browser”中输入对应的PromQL语句,用于收集数据。具体的PromQL语句请参见表6。 图11 填写PromQL语句
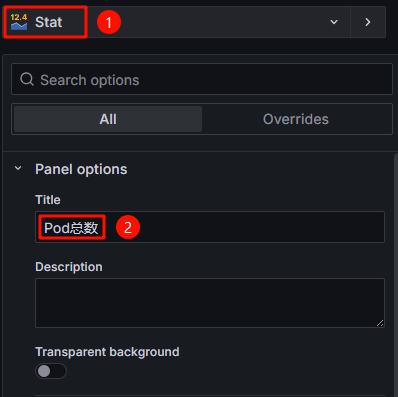
- 在右上方切换面板类型至“Stat”,并在“Panel options > Title”中设置面板标题,本示例标题设置为“Pod总数”,您可以根据需求自定义。 图12 设置面板类型和标题
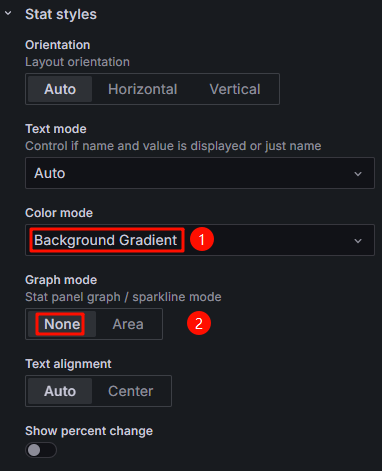
- 在“Stat styles”中设置颜色模式和图形模式。本示例中将“Color mode”为“Background Gradient”,设置“Graph mode”为“None”,您可以根据需求自定义。 图13 设置Stat styles
- 在右上角单击“Save”,在弹出的“Save dashboard”页面中再次单击“Save”,保存面板配置。在右上角单击“Apply”,返回Dashboard页面,此时“Pod总数”面板已创建。图14 Pod总数面板中数字显示为3,则说明当前集群有3个Pod。
表格面板示例--Pod详情
- 右侧单击“Add”,并在下拉菜单中单击“Visualization”,创建一个新面板。
- 在“Edit panel”页面右上方切换面板类型至“Table”,并在“Panel options > Title”中设置面板标题,本示例标题设置为“Pod详情”,您可以根据需求自定义。
- 在左下方“Query”页签中,在下方单击2次“Add query”。并在“A”、“B”、“C”的“Metrics browser”中依次输入3条的PromQL语句,具体PromQL语句请参见表6。 图15 填写PromQL语句

在“A”、“B”、“C”的“Options”中将“Format”都设置为“Table”,“Type”都设置为“Instant”,从而使查询结果以表格形式呈现,并仅获取当前时间点的数据。
图16 修改查询结果的呈现方式和查询模式
- 切换至“Transform data”页签,单击“Add transformation”。在右侧弹窗中,选择“Merge series/tables”,该操作用于合并增加的3条PromQL语句。 图17 选择Merge series/tables

- 在“Transform data”页签下方,单击“Add another transformation”,选择“Organize fields by name”,用于设置表头。同时,“Organize fields by name”支持隐藏列、调整列顺序、设置列名,具体示例请参见图19,您可以自定义。 图18 选择Organize fields by name

- 在右上角单击“Save”,在弹出的“Save dashboard”页面中再次单击“Save”,保存面板配置。在右上角单击“Apply”,返回Dashboard页面,此时“Pod详情”面板已创建,如图20。
柱状图面板示例--Pod显存分配量
- 右侧单击“Add”,并在下拉菜单中单击“Visualization”,创建一个新面板。
- 在“Edit panel”页面的左下方,“A”的“Metrics browser”中输入PromQL语句,具体PromQL语句请参见表6。PromQL语句输入完成后,在“Options > Legend”中选择“Custom”,后在该位置中填写“{{Pod}}”,该操作用于将图例中的标签替换为变量Pod的值。 图21 添加PromQL语句

- 在右上方切换面板类型至“Bar gauge”,并在“Panel options > Title”中设置面板标题,本示例标题设置为“Pod显存分配量”,您可以根据需求自定义。
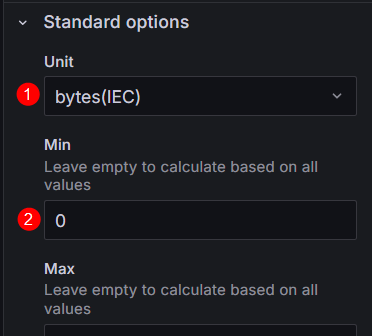
- 在下方的“Standard options”中,将“Unit”设置为“Data > bytes(IEC)”,表示将数据单位转化为GiB。并在“Min”中输入“0”,使数据呈现更加直观。 图22 配置Standard options信息
- 在右上角单击“Save”,在弹出的“Save dashboard”页面中再次单击“Save”,保存面板配置。在右上角单击“Apply”,返回Dashboard页面,此时“Pod显存分配量”面板已创建,请参见图23。
仪表盘面板示例--Pod显存分配量使用率
- 右侧单击“Add”,并在下拉菜单中单击“Visualization”,创建一个新面板。
- 在“Edit panel”页面的左下方,“A”的“Metrics browser”中输入PromQL语句,具体PromQL语句请参见表6。PromQL语句输入完成后,在“Options > Legend”中选择“Custom”,后在该位置中输入“{{Pod}}”,该操作用于将图例中的标签替换为变量Pod的值。 图24 修改图例标签

- 在右上方切换面板类型至“Gauge”,并在“Panel options > Title”中设置面板标题,本示例标题设置为“Pod显存分配量使用率”,您可以根据需求自定义。
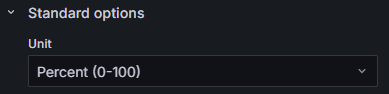
- 在下方的“Standard options”中,将“Unit”设置为“Misc > Percent(0-100)”,表示将数据单位设置为百分比,并确保值的范围在0%至100%之间。 图25 修改数据单位
- 在右上角单击“Save”,在弹出的“Save dashboard”页面中再次单击“Save”,保存面板配置。在右上角单击“Apply”,返回Dashboard页面,此时“Pod显存分配量使用率”面板已创建,请参见图26。







PromQL语句
本部分提供了不同维度下各监控面板的PromQL语句,您可以根据以下语句构建不同维度的Grafana仪表盘。
当显存/算力分配量为0时,计算显存/算力分配量使用率无意义。计算显存/算力分配量使用率时,本文提供的PromQL语句已经对显存/算力分配量为0的情况进行过滤。
| 监控面板名称 | PromQL语句 |
|---|---|
| Pod总数 | count(avg by (instance,pod,container,pod,container,namespace)(gpu_pod_memory_total{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod",pod!=""})) |
| Pod详情 | sum by (instance,pod,container,namespace)(gpu_pod_memory_total{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod",pod!=""}) /1024/1024/1024 |
| sum by (instance,pod,container,namespace)(gpu_pod_memory_used{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod",pod!=""}) /1024/1024/1024 | |
| avg by (instance,pod,container,namespace,xgpu_index) (xgpu_memory_total{pod!=""}) | |
| Pod显存分配量 | sum by (instance,pod,container,pod,container,namespace)(gpu_pod_memory_total{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod",pod!=""}) |
| Pod显存使用量 | sum by (instance,pod,container,pod,container)(gpu_pod_memory_used{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod",pod!=""}) |
| Pod显存分配量使用率 | sum by (instance,pod,container,pod,container)(gpu_pod_memory_used{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod",pod!=""})/sum by (instance,pod,container,pod,container)(gpu_pod_memory_total{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod",pod!=""}!=0) * 100 |
| Pod算力分配量 | sum by (instance,pod,container,pod,container)(gpu_pod_core_percentage_total{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod",pod!=""}) |
| Pod算力使用量 | sum by (instance,pod,container,pod,container)(gpu_pod_core_percentage_used{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod",pod!=""}) |
| Pod算力分配量使用率 | sum by (instance,pod,container,pod,container)(gpu_pod_core_percentage_used{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod",pod!=""})/sum by (instance,pod,container,pod,container)(gpu_pod_core_percentage_total{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod",pod!=""}!=0) * 100 |
| 监控面板名称 | PromQL语句 |
|---|---|
| GPU卡总数 | count(avg by (instance,gpu_index)(cce_gpu_temperature{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod"})) |
| GPU卡详情 | avg by (instance,gpu_index,gpu_id,modelName)(cce_gpu_memory_total{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod"}) /1024/1024/1024 |
| sum by (instance,gpu_index,gpu_id,modelName)(gpu_pod_memory_total{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod",pod!=""}) /1024/1024/1024 | |
| GPU卡显存分配量 | sum by (instance,gpu_index)(gpu_pod_memory_total{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod",pod!=""}) |
| GPU卡显存使用量 | sum by (instance,gpu_index)(gpu_pod_memory_used{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod",pod!=""}) |
| GPU卡显存分配量使用率 | sum by (instance,gpu_index)(gpu_pod_memory_used{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod",pod!=""})/sum by (instance,gpu_index)(gpu_pod_memory_total{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod",pod!=""}!=0) * 100 |
| GPU卡显存总量 | avg by (instance,gpu_index)(cce_gpu_memory_total{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod"}) |
| GPU卡算力分配量 | sum by (instance,gpu_index)(gpu_pod_core_percentage_total{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod",pod!=""}) |
| GPU卡算力使用量 | sum by (instance,gpu_index)(gpu_pod_core_percentage_used{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod",pod!=""}) |
| GPU卡算力分配量使用率 | sum by (instance,gpu_index)(gpu_pod_core_percentage_used{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod",pod!=""})/sum by (instance,gpu_index)(gpu_pod_core_percentage_total{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod",pod!=""}!=0) * 100 |
| GPU卡算力总量 | count by (instance, gpu_index) (avg by (instance,gpu_index)(cce_gpu_temperature{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod"})) * 100 |
| 监控面板名称 | PromQL语句 |
|---|---|
| GPU节点总数 | count(avg by (instance)(cce_gpu_temperature{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod"})) |
| GPU节点详情 | avg by (instance)(cce_gpu_memory_total{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod"}) /1024/1024/1024 |
| sum by (instance)(gpu_pod_memory_total{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod",pod!=""}) /1024/1024/1024 | |
| 节点显存分配量 | sum by (instance)(gpu_pod_memory_total{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod",pod!=""}) |
| 节点显存使用量 | sum by (instance)(gpu_pod_memory_used{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod",pod!=""}) |
| 节点显存分配量使用率 | sum by (instance)(gpu_pod_memory_used{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod",pod!=""})/sum by (instance)(gpu_pod_memory_total{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod",pod!=""}!=0) * 100 |
| 节点显存总量 | sum by (instance) (avg by (instance,gpu_index)(cce_gpu_memory_total{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod"})) |
| 节点算力分配量 | sum by (instance)(gpu_pod_core_percentage_total{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod",pod!=""}) |
| 节点算力使用量 | sum by (instance)(gpu_pod_core_percentage_used{pod!=""}) |
| 节点算力分配量使用率 | sum by (instance)(gpu_pod_core_percentage_used{pod!=""})/sum by (instance)(gpu_pod_core_percentage_total{pod!=""}!=0) * 100 |
| 节点算力总量 | count by (instance) (avg by (instance,gpu_index)(cce_gpu_temperature)) * 100 |
| 监控面板名称 | PromQL语句 |
|---|---|
| 集群显存分配量 | sum (gpu_pod_memory_total{pod!=""}) |
| 集群显存使用量 | sum (gpu_pod_memory_used{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod",pod!=""}) |
| 集群显存分配量使用率 | sum (gpu_pod_memory_used{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod",pod!=""})/sum (gpu_pod_memory_total{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod",pod!=""}) * 100 |
| 集群显存总量 | sum (avg by (instance,gpu_index)(cce_gpu_memory_total{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod"})) |
| 集群算力分配量 | sum (gpu_pod_core_percentage_total{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod",pod!=""}) |
| 集群算力使用量 | sum (gpu_pod_core_percentage_used{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod",pod!=""}) |
| 集群算力分配量使用率 | sum (gpu_pod_core_percentage_used{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod",pod!=""})/sum (gpu_pod_core_percentage_total{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod",pod!=""}) * 100 |
| 集群算力总量 | count(avg by (instance,gpu_index)(cce_gpu_temperature{instance=~"$instance",gpu_index=~"$gpu_index",namespace=~"$namespace",pod=~"$pod"})) * 100 |




