
pg_cron
Introduction
The pg_cron extension is a cron-based job scheduler. It uses the same syntax as regular cron, but it allows you to schedule PostgreSQL commands directly from the database. For more information, see the official pg_cron documentation.
Supported Versions
This extension is available to the latest minor versions of RDS for PostgreSQL 12 and later versions. You can run the following SQL statement to check whether your DB instance supports this extension:
SELECT * FROM pg_available_extension_versions WHERE name = 'pg_cron';
If this extension is not supported, upgrade the minor version of your DB instance or upgrade the major version using dump and restore.
To see more extensions supported by RDS for PostgreSQL, go to Supported Extensions.
Features
The standard cron syntax is used, in which the asterisk (*) means "run every time period", and a specific number means "but only at this time".
┌───────────── min (0 - 59) │ ┌────────────── hour (0 - 23) │ │ ┌─────────────── day of month (1 - 31) │ │ │ ┌──────────────── month (1 - 12) │ │ │ │ ┌───────────────── day of week (0 - 6) (0 to 6 are Sunday to │ │ │ │ │ Saturday, or use names; 7 is also Sunday) │ │ │ │ │ │ │ │ │ │
For example, the syntax for 9:30 a.m. (GMT) every Saturday is as follows:
30 9 * * 6
Precautions
- pg_cron requires a daemon process. Therefore, before starting a database, you need to add pg_cron to the shared_preload_libraries parameter value.
- Scheduled jobs do not run on the standby instance. However, if the standby instance is promoted to primary, scheduled jobs automatically start.
- Scheduled jobs are executed with the permissions of the job creator.
- Scheduled jobs are executed using the GMT time.
- An instance can run multiple jobs concurrently, but one job can only run once at a given time.
- If a job needs to wait for the completion of the previous scheduled job, it will enter the wait queue and will be started as soon as possible after the previous job completes.
- Before using this extension, you need to change the value of cron.database_name to the name of the database where scheduled jobs are created. This parameter can only be set to one database name instead of multiple names.
Installing the Extension
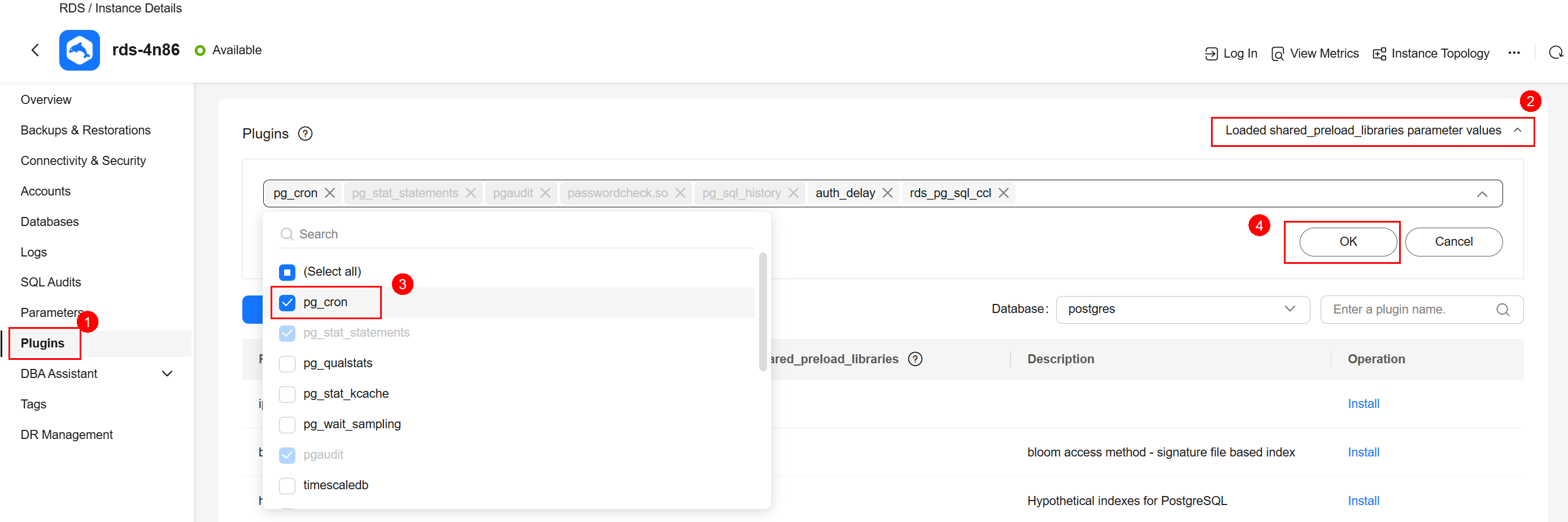
- In the instance list, click the target instance name to go to the Summary page.
- Choose Plugins and add pg_cron to the shared_preload_libraries parameter values.
Figure 1 Plugins
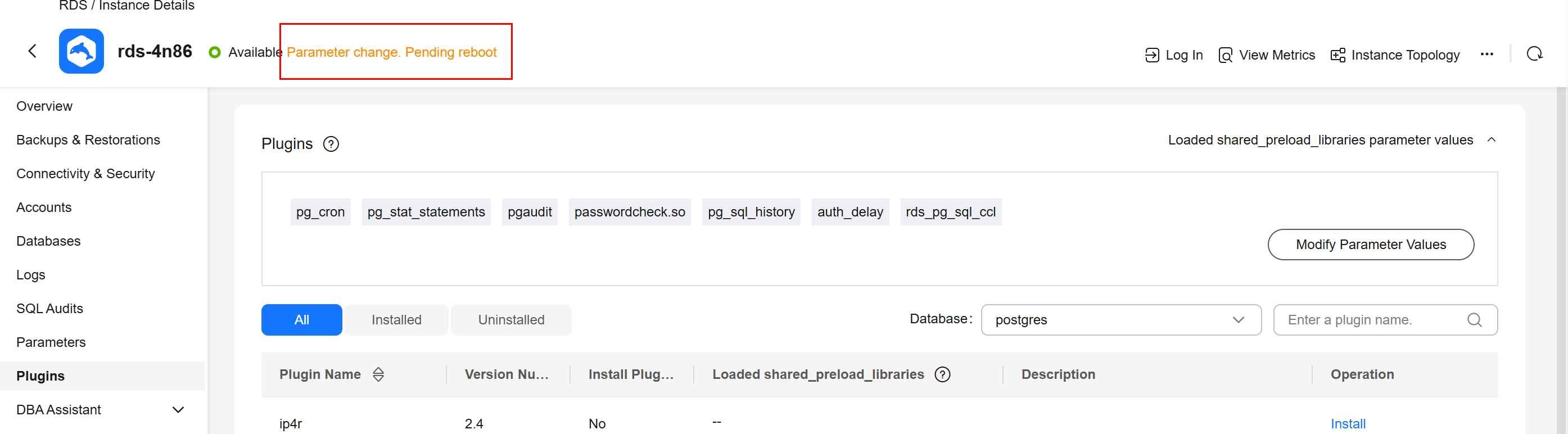
- Reboot the DB instance for the modification to be applied.
Figure 2 Extension added
- If the extension is not to be installed in the default database postgres, modify the cron.database_name parameter.
The value of cron.database_name must be changed to the name of the database where pg_cron is to be used. For example, if you want to install the extension in the test_db database, change the value of cron.database_name to test_db.Figure 3 Changing the parameter value
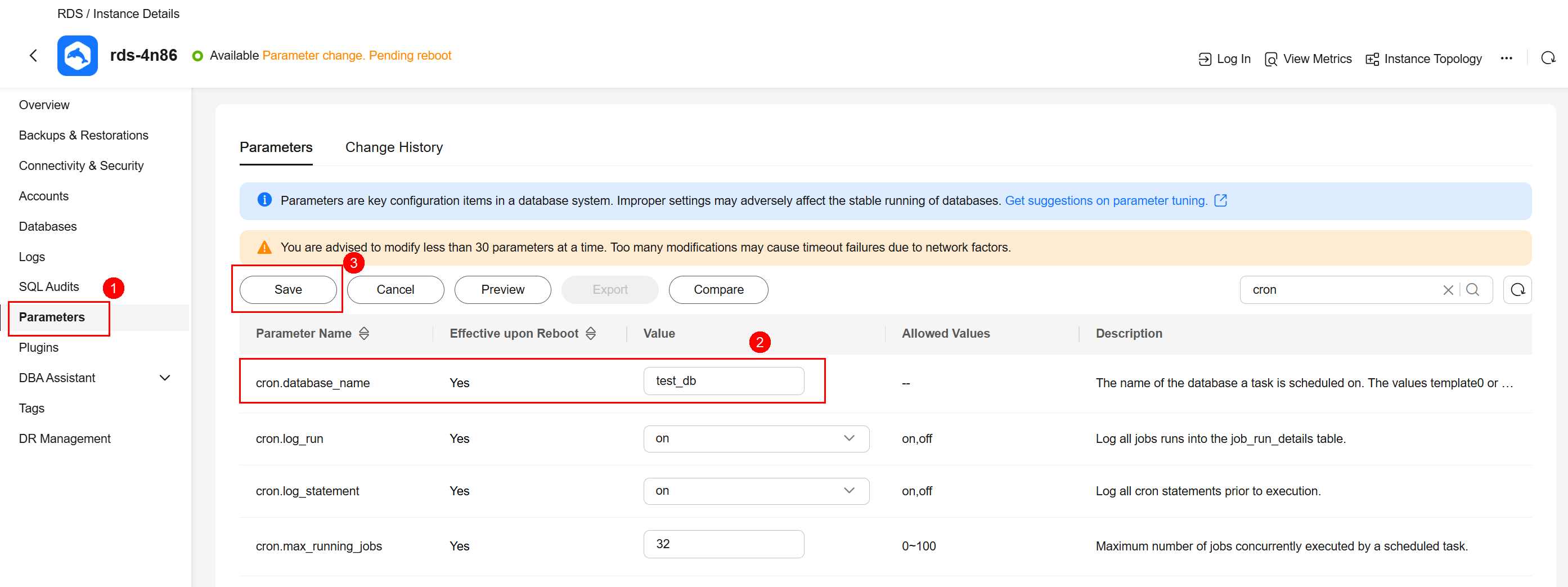

After modifying cron.database_name, reboot the instance for the modification to be applied.
- Install the pg_cron extension.
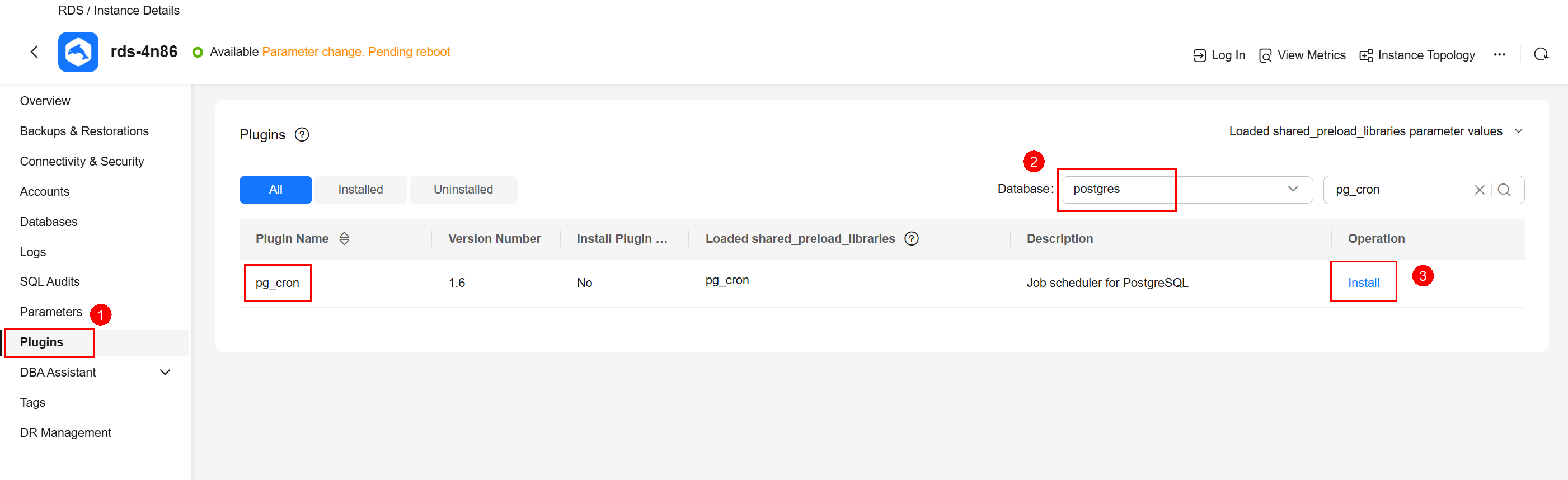
Basic Usage
Create jobs.
-- Job 1: Delete old data at 03:30 a.m. (GMT) every Saturday.
SELECT cron.schedule('30 3 * * 6', $$DELETE FROM events WHERE event_time < now() - interval '1 week'$$);
-- Job 2: Run the VACUUM command at 10:00 a.m. (GMT) every day. The job is named nightly-vacuum.
SELECT cron.schedule('nightly-vacuum', '0 10 * * *', 'VACUUM');
Advanced Usage (Configuring Scheduled Jobs for Databases Other Than postgres)
Prerequisites: The pg_cron extension has been installed in the postgres database, and the test_db database has been created. Configure scheduled jobs for the test_db database.
- Log in to the postgres database.
- Create scheduled jobs.
SELECT cron.schedule('create', '10 * * * *', 'create table test (a int);'); SELECT cron.schedule('insert', '15 * * * *', 'insert into test values(1);'); SELECT cron.schedule('drop', '20 * * * *', 'drop table test;');
Each scheduled job name must be unique. Otherwise, the job will be overwritten.
- Update the scheduled jobs to run them in the test_db database.
UPDATE cron.job SET database = 'test_db' WHERE jobid = 1; UPDATE cron.job SET database = 'test_db' WHERE jobid = 2; UPDATE cron.job SET database = 'test_db' WHERE jobid = 3;
To query the job IDs, run the following commands:
postgres=> select * from cron.job; jobid | schedule | command | nodename | nodeport | database | username | active | jobname -------+------------+-----------------------------+-----------+----------+-----------+----------+--------+--------- 1 | 10 * * * * | create table test (a int); | localhost | 5432 | postgres | root | t | create 2 | 15 * * * * | insert into test values(1); | localhost | 5432 | postgres | root | t | insert 3 | 20 * * * * | drop table test; | localhost | 5432 | postgres | root | t | drop - In the command output, the value of database is test_db, indicating that the jobs are executed in the test_db database.
postgres=> select * from cron.job; jobid | schedule | command | nodename | nodeport | database | username | active | jobname -------+------------+-----------------------------+-----------+----------+-----------+----------+--------+--------- 1 | 10 * * * * | create table test (a int); | localhost | 5432 | test_db | root | t | create 2 | 15 * * * * | insert into test values(1); | localhost | 5432 | test_db | root | t | insert 3 | 20 * * * * | drop table test; | localhost | 5432 | test_db | root | t | drop - Check whether the scheduled jobs have been successfully executed.
- Check the logs for successful job execution.
Figure 5 Checking logs

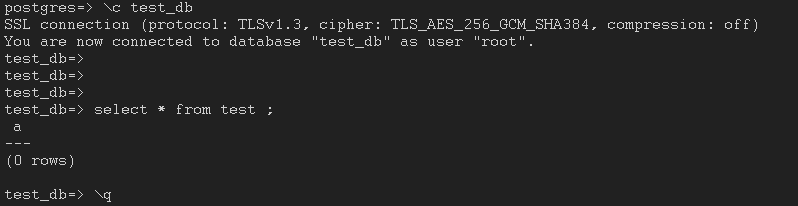
- Check whether the test table has been created in the test_db database.
Figure 6 Querying the database
- Check the logs for successful job execution.
- If you do not want to use the scheduled jobs anymore, delete them based on the result obtained in 4:
- Delete a job using the job ID.
SELECT cron.unschedule(1);
- Delete a job using the job name.
SELECT cron.unschedule('create');
- Delete a job using the job ID.
Parameters Related to the pg_cron Extension
|
Parameter |
Description |
Default Value |
Reboot Required |
|---|---|---|---|
|
cron.database_name |
The database in which scheduled job metadata is kept. |
postgres |
Yes |
|
cron.log_statement |
Whether to log all cron statements before running them. |
true |
Yes |
|
cron.log_run |
Whether to log every job that runs in the job_run_details table. |
true |
Yes |
|
cron.host |
The name of the host where scheduled jobs are to be executed. |
localhost |
Yes |
|
cron.use_background_workers |
Whether to use background work processes instead of client sessions to run jobs. |
false |
Yes |
|
cron.max_running_jobs |
The number of jobs that can run concurrently. |
5 |
Yes |
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



