
Typical Deployment Architecture for Information Management Applications (99.95% Availability)
Information management applications are proprietary and used internally. If these applications fail, they may cause disruptions in related operations and bring inconvenience to operators, but certain RTO and RPO of them are acceptable. These applications require an availability of 99.95%, that is, up to 4.38 hours of downtime per year.
Assume that the interruption time caused by faults and changes is as follows:
- Fault-caused interruptions: Assume that there are four fault-caused interruptions each year. It takes 20 minutes to decide on the emergency recovery for each interruption and 10 minutes to recover application services. Thus, the total yearly interruption time is 120 minutes.
- Change-caused interruptions: Assume that an application allows offline updates and online patching. If an application is updated offline for four times every year, and each update takes 30 minutes, then the yearly update time is 120 minutes. Note that services are not affected during online patching.
As estimated above, the application system will be unavailable for 240 minutes each year, which meets the availability design requirements.
An information management application usually consists of two main parts: a stateless application layer at the frontend and a database at the backend. The frontend stateless application layer can be composed of ECS or CCE instances (CCE is used as an example here) with ELB for load balancing; while the backend typically uses GaussDB for its high performance and reliability. Other types of databases can also be used based on service requirements. For example, DDS and some middleware, such as DCS or Kafka are also common backend options. To meet the availability requirement, the recommended solution is as follows:
|
Item |
Solution |
|---|---|
|
Redundancy |
Deploy cloud service instances in HA mode, such as ELB, CCE, DCS, Kafka, GaussDB, and DDS instances. |
|
Backup |
Enable automated backup for GaussDB and DDS databases. When a data fault occurs, the latest backup can be used to restore data, meeting availability requirements. |
|
DR |
Deploy applications across three AZs. If an AZ is faulty, services are automatically recovered. |
|
Monitoring metrics and alarms |
Monitor and check the service running status and success metrics, and an alarm is reported when a fault occurs. Monitor the load status and resource failover of cloud service instances, and an alarm is reported when the load exceeds the threshold or the status is abnormal. |
|
Auto scaling |
Resources are sufficient for internal operations, making auto scaling unnecessary. For CCE containers, use ELB for fault detection and load balancing. Ensure that GaussDB instances can be automatically scaled up or down, and the read-only nodes can be automatically added or removed on demand based on the workload monitoring statistics. |
|
Change error prevention |
Update software offline and perform patch-related operations online. In addition, each application needs to be automatically deployed and rolled back as instructed by a runbook. The software is updated every one to two months. |
|
Emergency recovery |
Develop an emergency handling mechanism and designate related personnel to quickly make decisions and recover services. Provide solutions to common application and database problems as well as upgrade and deployment failures. |
The typical deployment architecture is as follows:
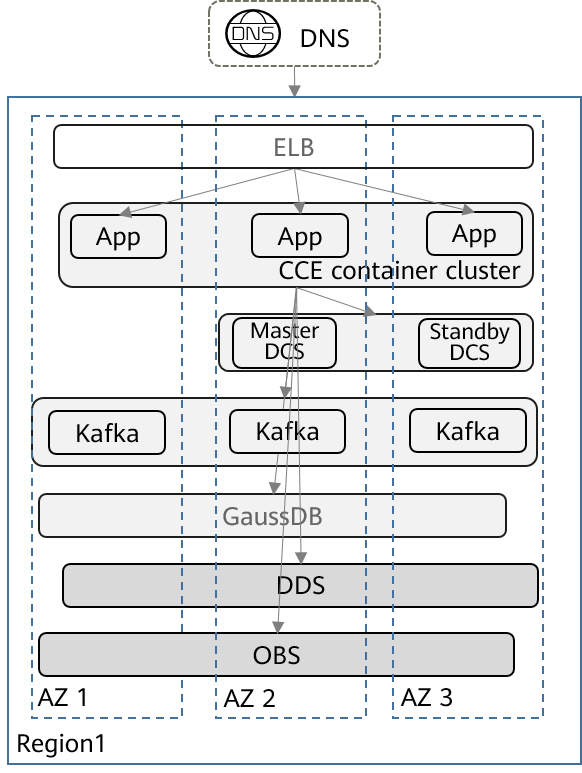
This architecture has the following features:
- The application system is layered with stateless applications and stateful databases.
- The application system is deployed across AZs in a single region of Huawei Cloud, so as to achieve active-active cross-DC deployment of the application layer on the cloud.
- Access layer (external DNS): The external DNS is used for domain name resolution and traffic load balancing. The failure of a single AZ does not affect services.
- Application layer (ELBs, application software, and containers): The stateless applications are deployed across AZs in HA mode. For these applications, ELBs are used for fault detection and load balancing, and CCE is used for workload monitoring and auto scaling.
- Middleware layer: Redis and Kafka clusters are deployed across AZs in HA mode. The failure of a single AZ does not affect services.
- Data layer: GaussDB, DDS, and OBS are deployed across three AZs in HA mode. These distributed databases ensure consistent data among different AZs. If a single AZ is faulty, services are not affected and no data is lost.
- The data in the GaussDB and DDS databases is automatically backed up in a scheduled manner to ensure data reliability.
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



