
Typical Deployment Architecture for Internal Tools or OBT Applications (99% Availability)
Internal tools are proprietary and used internally. If these tools fail, they may cause disruptions in related operations and bring inconvenience to operators, but their RTO and RPO can be long. OBT applications handle experimental customer tasks and can be disabled if needed. These tools and applications do not require high availability—a 99% uptime standard (up to 3.65 days of downtime per year) is sufficient.
The service interruption time includes the interruption time due to faults and the interruption time caused by upgrades, configuration, and maintenance. Assume that the interruption time is as follows:
- Fault-caused interruptions: Assume that there are four fault-caused interruptions each year. It takes 1 hour to decide on the emergency recovery for each interruption and 2 hours to re-deploy and configure the application workload and recover the related data. Thus, the total yearly interruption time is 12 hours.
- Change-caused interruptions: Assume that an application is updated offline for six times every year, and each update takes 4 hours. Then the yearly update time is 24 hours.
As estimated above, the application system will be unavailable for 36 hours each year, which meets the availability design requirements.
An internal tool usually consists of two main parts: a stateless application layer at the frontend and a database at the backend. The frontend stateless application layer can be composed of ECS or CCE instances (ECS is used as an example here); while the backend typically uses RDS for MySQL, depending on the service type. To meet the availability requirement, the recommended solution is as follows:
|
Item |
Solution |
|---|---|
|
Redundancy |
Deploy ECS and RDS in single-node mode. |
|
Backup |
Enable automated backup for RDS databases. When a data fault occurs, the latest backup can be used to restore data, meeting availability requirements. |
|
DR |
DR deployment is not supported. If faults occur at a site, applications need to be re-deployed and backup data needs to be restored again. |
|
Monitoring metrics and alarms |
Use basic monitoring to check whether each application can return messages normally. |
|
Auto scaling |
Provide runbooks for troubleshooting common issues, facilitating manual scaling when required, such as performing a scale-out when the capacity becomes insufficient. |
|
Change error prevention |
Update software offline, stop applications during installation and restart, and deploy and roll back applications as instructed by runbooks. |
|
Emergency recovery |
Assign an application system owner, who can be contacted for emergency recovery. |
The typical deployment architecture is as follows:
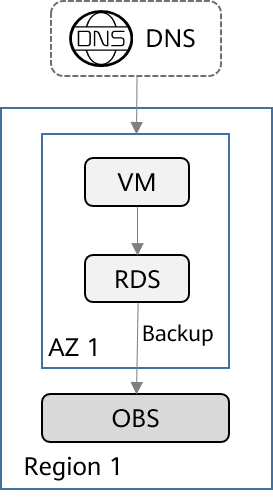
This architecture has the following features:
- The application system is deployed in a single AZ of a single region.
- The RDS database data is automatically backed up to OBS periodically to ensure that data can be quickly restored in the case of data loss.
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



