
Spark on Hudi Performance Tuning
Optimizing Spark Shuffle for Faster Hudi Write
- Setting spark.shuffle.readHostLocalDisk=true allows reading shuffle data from local disks, thereby reducing network transmission overhead.
- Setting spark.io.encryption.enabled=false disables the function of writing encrypted disks during shuffle, thereby improving shuffle efficiency.
- Setting spark.shuffle.service.enabled=true starts the shuffle service and enhance task shuffle stability.
Parameter
Default Value
New Value
--conf spark.shuffle.readHostLocalDisk
false
true
--conf spark.io.encryption.enabled
true
false
--conf spark.shuffle.service.enabled
false
true
Adjusting Spark Scheduling Parameters to Shorten the Spark Scheduling Delay in the OBS
- Enabling OBS storage allows you to optimize Spark scheduling efficiency by disabling Spark's locality.
Parameter
Default Value
New Value
--conf spark.locality.wait
3s
0s
--conf spark.locality.wait.process
3s
0s
--conf spark.locality.wait.node
3s
0s
--conf spark.locality.wait.rack
3s
0s
Optimizing Shuffle Parallelism for Faster Spark Data Processing
The following figure shows the shuffle concurrency.
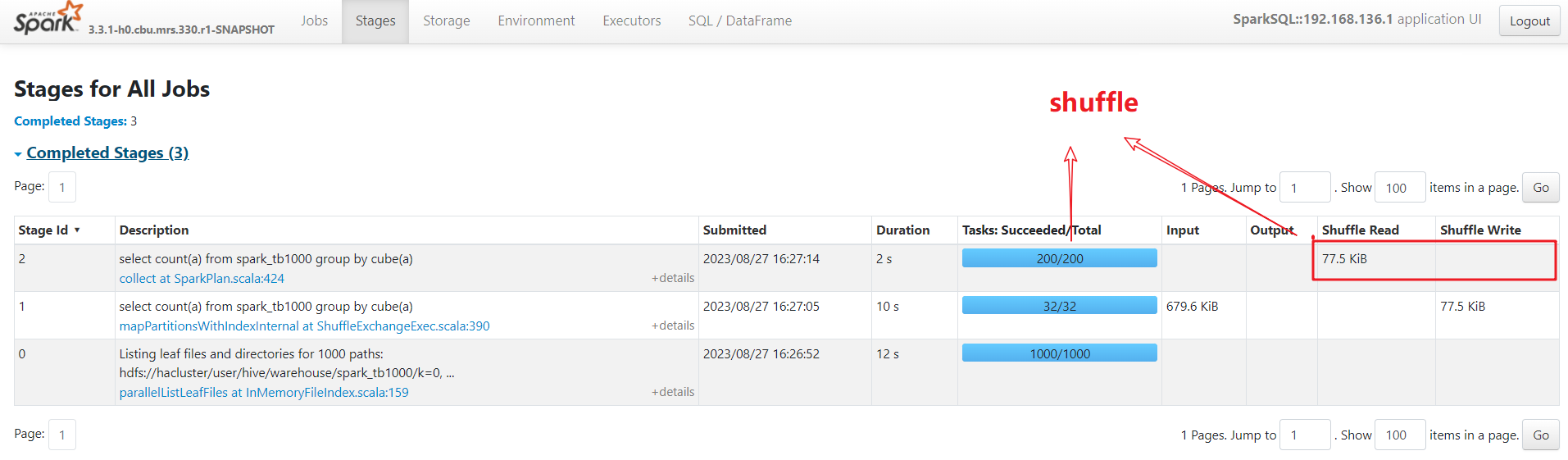
The default shuffle concurrency is 200 for cluster, and it can be set for jobs respectively. If a bottleneck stage (long execution time) is identified and the number of cores assigned to the current job exceeds the present concurrency level, it indicates insufficient concurrency. Use the following configurations to optimize.
|
Scenario |
Parameter |
Default Value |
New Value |
|---|---|---|---|
|
Jar job |
spark.default.parallelism |
200 |
Set the value to 2 times the actual available resources. |
|
SQL Job |
spark.sql.shuffle.partitions |
200 |
Set the value to 2 times the actual available resources. |
|
Hudi import job |
hoodie.upsert.shuffle.parallelism |
200 |
Set the parameter to twice the actual available resources for non-bucket tables |

In dynamic resource scheduling (spark.dynamicAllocation.enabled = true), resources are evaluated based on spark.dynamicAllocation.maxExecutors.
Enabling Bucket Trimming to Accelerate Primary Key Point Query for Bucket Tables
Example:
To perform a point query, the primary key ID is often used as the search condition, such as "SELECT xxx WHERE id = idx...".
When creating a table, you can add the specified property to enhance query performance. Under the default configuration, the property value is primaryKey.
hoodie.bucket.index.hash.field=id
Using BulkInsert for Quick Data Ingestion During Hudi Table initialization
Example:
set hoodie.combine.before.insert=true; --Deduplicate before importing. This is not need if there is no duplicate. set hoodie.datasource.write.operation = bulk_insert; --Specify the bulk insert. set hoodie.bulkinsert.shuffle.parallelism = 4; --Specify the parallelism degree for bulk_insert write, which is equal to the number of partition Parquet files saved after the write operation is complete. insert into dsrTable select * from srcTabble
Enabling Log Column Tailoring to Accelerate the MOR Table
Reading an MOR table involves merging logs and Parquet files, resulting in less than ideal performance. Log column trimming can be enabled to reduce I/O read overhead during merging.
Use the following setting before running a query with Spark SQL:
set hoodie.enable.log.column.prune=true;
Optimizing Other Parameters During Spark Processing of Hudi Tables
- Set spark.sql.enableToString=false to reduce memory usage during Spark's parsing of complex SQL statements and improve parsing efficiency.
- Setting spark.speculation=false disables speculative execution. Enabling this parameter incurs additional CPU usage, and Hudi does not support the parameter. Enabling this parameter when writing to Hudi may lead to file corruption with a certain probability.
Parameter
Default Value
New Value
--conf spark.sql.enableToString
true
false
--conf spark.speculation
false
false
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



