
Updated on 2025-09-22 GMT+08:00
CLUSTER
Description
- Clusters a table based on an index.
- CLUSTER instructs GaussDB to cluster the table specified by the table name based on the index specified by the index name. The index must have been defined by the table name.
- When a table is clustered, it is physically reordered based on the index information. Clustering is a one-time operation. When the table is subsequently updated, the changes are not clustered. That is, no attempt is made to store new or updated rows according to their index order.
- When a table is clustered, GaussDB records which index the table was clustered by. CLUSTER table_name reclusters the clustered index that was previously recorded in the table. You can also use ALTER TABLE table_name CLUSTER on index_name to set the index of a specified table for subsequent CLUSTER operations, or use ALTER TABLE table_name SET WITHOUT CLUSTER to clear the previously clustered index of a specified table.
- If CLUSTER does not contain parameters, all tables that have been clustered in the database owned by the current user will be reprocessed. If a system administrator uses this command, all clustered tables are reclustered.
- When a table is clustered, an ACCESS EXCLUSIVE lock is requested on the table. This avoids that other operations (including read and write operations) are performed on the table before the CLUSTER operation is complete.
Precautions
- Only row-store B-tree indexes support CLUSTER.
- In the case where you are accessing single rows randomly within a table, the actual order of the data in the table is unimportant. However, if there are many accesses to some data and an index groups the data, using the CLUSTER index improves performance.
- If you use an index to query a table for a range or multiple rows, CLUSTER will also help because once the index identifies the table page for the first row that matches, all other rows that match are probably already on the same table page. This saves disk accesses and speeds up the query.
- During clustering, the system creates a temporary backup of the table created in the index sequence and a temporary backup of each index in the table. Therefore, ensure that the disk has sufficient free space during clustering, which is at least the sum of the table size and all index sizes.
- CLUSTER records which indexes have been used for clustering. Therefore, you can manually specify indexes for the first time, cluster specified tables, and set a maintenance script that will be executed periodically. You only need to run the CLUSTER command without parameters. In this way, tables that you want to periodically cluster can be automatically updated.
- The optimizer records table clustering statistics. After clustering a table, you need to execute the ANALYZE operation to ensure that the optimizer has the latest clustering information. Otherwise, the optimizer may select a non-optimal query plan.
- CLUSTER cannot be executed in transactions.
- If the GUC parameter xc_maintenance_mode is not set to on, the CLUSTER operation skips all system catalogs.
Syntax
- Cluster a table.
CLUSTER [ VERBOSE ] table_name [ USING index_name ];

- Cluster a partition.
CLUSTER [ VERBOSE ] table_name PARTITION ( partition_name ) [ USING index_name ];

- Recluster a table.
CLUSTER [ VERBOSE ];
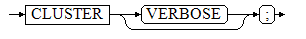
Parameters
- VERBOSE
(Optional) Enables the display of progress messages.
- table_name
Specifies the table name.
Value range: an existing table name
- [ USING index_name ]
Specifies the index name.
Value range: an existing index name
You must specify index_name when performing clustering on the table for the first time. If you do not specify index_name next time, the table will be clustered based on existing records.
- partition_name
Specifies the partition name.
Value range: an existing partition name
Examples
- Cluster the table.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
-- Create a table and insert data into the table. gaussdb=#CREATE TABLE test_c1(id int, name varchar(20)); gaussdb=#CREATE INDEX idx_test_c1_id ON test_c1(id); gaussdb=#INSERT INTO test_c1 VALUES (3,'Joe'),(1,'Jack'),(2,'Scott'); -- Query. gaussdb=#SELECT * FROM test_c1; id | name ----+------- 3 | Joe 1 | Jack 2 | Scott (3 rows) -- Perform clustering. gaussdb=#CLUSTER test_c1 USING idx_test_c1_id; -- Query. gaussdb=#SELECT * FROM test_c1; id | name ----+------- 1 | Jack 2 | Scott 3 | Joe (3 rows) -- Delete. gaussdb=#DROP TABLE test_c1;
- Recluster a table.
-- Create a table. gaussdb=#CREATE TABLE test(col1 int,CONSTRAINT pk_test PRIMARY KEY (col1)); -- An error is reported when the keyword USING is not contained in the first clustering. gaussdb=#CLUSTER test; ERROR: there is no previously clustered index for table "test" -- Perform clustering. gaussdb=#CLUSTER test USING pk_test; -- Insert data. gaussdb=#INSERT INTO test VALUES (1),(99),(10),(8); -- Recluster a table. gaussdb=#CLUSTER VERBOSE test; INFO: clustering "public.test" using index scan on "pk_test"(dn_6001 pid=3672) INFO: "test": found 0 removable, 4 nonremovable row versions in 1 pages(dn_6001 pid=3672) DETAIL: 0 dead row versions cannot be removed yet. CPU 0.00s/0.00u sec elapsed 0.01 sec. CLUSTER -- Delete. gaussdb=#DROP TABLE test;
- Cluster a partition.
-- Create a table and insert data into the table. gaussdb=#CREATE TABLE test_c2(id int, info varchar(4)) PARTITION BY RANGE (id)( PARTITION p1 VALUES LESS THAN (11), PARTITION p2 VALUES LESS THAN (21) ); gaussdb=#CREATE INDEX idx_test_c2_id1 ON test_c2(id); gaussdb=#INSERT INTO test_c2 VALUES (6,'ABBB'),(2,'ABAB'),(9,'AAAA'); gaussdb=#INSERT INTO test_c2 VALUES (11,'AAAB'),(19,'BBBA'),(16,'BABA'); -- Query. gaussdb=#SELECT * FROM test_c2; id | info ----+------ 6 | ABBB 2 | ABAB 9 | AAAA 11 | AAAB 19 | BBBA 16 | BABA (6 rows) -- Perform clustering on partition p2. gaussdb=#CLUSTER test_c2 PARTITION (p2) USING idx_test_c2_id1; -- Query. gaussdb=#SELECT * FROM test_c2; id | info ----+------ 6 | ABBB 2 | ABAB 9 | AAAA 11 | AAAB 16 | BABA 19 | BBBA (6 rows) -- Delete. gaussdb=#DROP TABLE test_c2;
Parent topic: C
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
The system is busy. Please try again later.
For any further questions, feel free to contact us through the chatbot.
Chatbot



