
Uso de um cluster de RegionlessDB para DR multiativa remota
Cenários
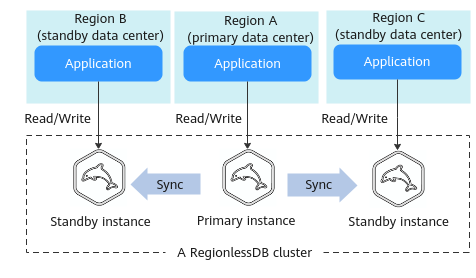
Se suas cargas de trabalho forem implementadas em várias regiões, você poderá criar um cluster de RegionlessDB para acessar bancos de dados da região mais próxima. Conforme mostrado em Figura 1, um cluster de RegionlessDB contém uma instância primária e duas instâncias em espera. As solicitações de leitura são enviadas para uma instância em espera na região mais próxima, e as solicitações de gravação são encaminhadas automaticamente da região mais próxima para a instância primária. Depois que os dados são gravados na instância primária, os dados são sincronizados com todas as instâncias em espera, reduzindo a latência da rede entre regiões.
Restrições
Para mais detalhes, consulte Restrições.
Procedimento
Etapa 1: criar um cluster de RegionlessDB
- Faça logon no console de gerenciamento.
- Clique em
 no canto superior esquerdo e selecione uma região e um projeto.
no canto superior esquerdo e selecione uma região e um projeto. - Clique em
 no canto superior esquerdo da página e escolha Databases > TaurusDB.
no canto superior esquerdo da página e escolha Databases > TaurusDB. - Na página RegionlessDB, clique em Create RegionlessDB no canto superior direito. Figura 2 Criação de um cluster de RegionlessDB

- Na caixa de diálogo Create RegionlessDB, configure RegionlessDB Name, Primary Instance Region e Primary Instance. Figura 3 Configuração das informações do cluster de RegionlessDB

Tabela 1 Descrição do parâmetro Parâmetro
Descrição
RegionlessDB Name
O nome deve começar com uma letra e consistir de 4 a 64 caracteres. Somente letras (diferenciando maiúsculas de minúsculas), dígitos, hifens (-) e sublinhados (_) são permitidos.
Primary Instance Region
Selecione uma região onde a instância primária está localizada.
Primary Instance
Selecione uma instância de BD existente como a instância principal do cluster de RegionlessDB.
- Clique em OK.
- Depois que a instância primária for criada, visualize-a e gerencie-a.
Durante o processo de criação, o status da instância é Creating. Para ver o progresso detalhado e o resultado da criação, vá para a página Task Center. Depois que o status da instância primária for Available, você poderá usá-la.
Etapa 2: adicionar uma instância em espera
- Na página RegionlessDB, localize o cluster de RegionlessDB.
- Clique em Add Standby Instance na coluna Operation. Figura 4 Adição de uma instância em espera

- Na página exibida, configure os parâmetros relacionados.
Tabela 2 Informações básicas Parâmetro
Descrição
Region
Região onde a instância em espera é implementada.
AVISO:Produtos em diferentes regiões não podem se comunicar uns com os outros por meio de uma rede privada. Depois que uma instância de banco de dados for comprada, a região não poderá ser alterada.
Creation Method
Criar novo
DB Instance Name
O nome deve começar com uma letra e consistir de 4 a 64 caracteres. Somente letras, dígitos, hifens (-) e sublinhados (_) são permitidos.
DB Engine
TaurusDB
DB Engine Version
MySQL 8.0
Kernel Version
Versão do kernel da instância em espera. A versão do kernel deve ser 2.0.46.231000 ou posterior.
Para obter detalhes sobre as atualizações em cada versão secundária do kernel, consulte Histórico de lançamento da versão do kernel de TaurusDB.
NOTA:Para configurar a versão do kernel, entre em contato com o atendimento ao cliente.
DB Instance Type
Apenas Cluster pode ser selecionado. Há de 2 a 10 réplicas de leitura em uma instância de cluster no cluster de RegionlessDB.
Storage Type
Compartilhado
AZ Type
Uma AZ é uma região física em que os recursos têm suas próprias redes e fontes de alimentação independentes. As AZs são fisicamente isoladas, mas interconectadas por meio de uma rede interna. Algumas regiões oferecem suporte à implementação de AZ única e várias AZs e outras oferecem suporte apenas à implementação de AZ única.
- Single AZ: o nó primário e as réplicas de leitura são implementados na mesma AZ.
- Multi-AZ: o nó primário e as réplicas de leitura são implementados em diferentes AZs para garantir alta confiabilidade.
Time Zone
Você precisa selecionar um fuso horário para sua instância com base na região que hospeda sua instância. O fuso horário é selecionado durante a criação da instância e não pode ser alterado após a criação da instância.
Instance Specifications
Para obter detalhes sobre as especificações suportadas por TaurusDB, consulte Especificações de instância.
TaurusDB é um banco de dados nativo da nuvem que usa o armazenamento compartilhado. Para garantir a estabilidade da carga de trabalho em alta pressão de leitura/gravação, o sistema controla os picos de leitura/gravação das instâncias de BD com base nas especificações da instância. Para obter detalhes sobre como selecionar especificações, consulte Livro branco sobre desempenho.
CPU Architecture
A arquitetura da CPU pode ser x86 ou Kunpeng. Em uma arquitetura de CPU, você precisa selecionar as vCPUs e a memória da instância.
Nodes
Todos os nós da instância em espera são réplicas de leitura. Você pode solicitar no máximo 10 réplicas de leitura por vez para uma instância de pagamento por uso.
Depois que uma instância é criada, você pode adicionar réplicas de leitura conforme necessário. Até 15 réplicas de leitura podem ser criadas para uma instância em espera em um cluster.
Storage
O armazenamento será ampliado dinamicamente com base na quantidade de dados que precisam ser armazenados e é cobrado por hora com base no pagamento conforme o uso.
VPC
- Uma rede virtual dedicada na qual sua instância de TaurusDB está localizada. Ele isola redes para diferentes cargas de trabalho. Você pode selecionar uma VPC existente ou criar uma VPC. Para obter detalhes sobre como criar uma VPC, consulte Criação de uma VPC.
Se nenhuma VPC estiver disponível, TaurusDB aloca uma VPC para você por padrão.
AVISO:- Certifique-se de que a VPC selecionada para a instância em espera esteja conectada à VPC selecionada para a instância primária por meio de uma VPN.
- Depois que uma instância de TaurusDB é criada, a VPC não pode ser alterada.
- Uma sub-rede fornece recursos de rede dedicados que são logicamente isolados de outras redes para a segurança da rede.
Um endereço IP privado é atribuído automaticamente quando você cria uma instância de banco de dados. Você também pode inserir um endereço IP privado ocioso no bloco CIDR da sub-rede.
Security Group
Ele pode aumentar a segurança controlando o acesso ao TaurusDB de outros serviços. Ao selecionar um grupo de segurança, você deve garantir que ele permita que o cliente acesse instâncias.
Se nenhum grupo de segurança estiver disponível ou tiver sido criado, o TaurusDB aloca um grupo de segurança para você por padrão.
NOTA:- Para garantir a conexão e o acesso subsequentes ao banco de dados, você precisa permitir que todos os endereços IP acessem sua instância de BD pela porta 3306 e pelo ICMP.
- Configure regras de grupo de segurança de rede privada para garantir que as instâncias primárias e em espera em um cluster possam se comunicar umas com as outras.
Parameter Template
Contém valores de configuração do mecanismo que podem ser aplicados a uma ou mais instâncias. Você pode modificar os parâmetros da instância conforme necessário depois que a instância for criada.
AVISO:Se você usar um modelo de parâmetro personalizado ao criar uma instância de banco de dados, os seguintes parâmetros relacionados à especificação no modelo personalizado não serão aplicados. Em vez disso, os valores padrão são usados.
innodb_buffer_pool_size
innodb_log_buffer_size
max_connections
innodb_buffer_pool_instances
innodb_page_cleaners
innodb_parallel_read_threads
innodb_read_io_threads
innodb_write_io_threads
threadpool_size
Depois que uma instância de BD é criada, você pode ajustar seus parâmetros conforme necessário. Para obter detalhes, consulte Modificação de parâmetros em um modelo de parâmetro.
Enterprise Project
Disponível apenas para usuários empresariais. Se você quiser usar essa função, entre em contato com o atendimento ao cliente.
Um projeto empresarial fornece uma maneira de gerenciar recursos em nuvem e membros empresariais numa base de projeto por projeto.
Você pode selecionar um projeto empresarial na lista suspensa. O projeto padrão é default.
Tag
Este parâmetro é opcional. A adição de tags ajuda você a identificar e gerenciar melhor suas instâncias de banco de dados. Cada instância de BD pode ter até 20 tags.
Depois que uma instância de banco de dados for criada, você poderá visualizar seus detalhes de tag na guia Tags. Para obter detalhes, consulte Gerenciamento de tags.
A senha da instância e a distinção entre maiúsculas e minúsculas do nome da tabela são iguais às da instância primária. Não é necessário configurá-las separadamente.
- Clique em Next.
- Confirme as informações e clique em Submit.
- Vá para a página Instances para exibir e gerenciar a instância.
Durante o processo de criação, o status da instância é Creating. Para ver o progresso detalhado e o resultado da criação, vá para a página Task Center. Depois que o status da instância estiver Available, você poderá usar a instância.
Se houver uma grande quantidade de dados na instância primária, poderá levar muito tempo para concluir um backup completo durante a criação da instância em espera.
Etapa 3: ativar encaminhamento de gravação
Em casos normais, depois que um cluster de RegionlessDB é criado, a instância primária recebe e processa solicitações de leitura e gravação, e as instâncias em espera recebem apenas solicitações de leitura. Depois que o encaminhamento de gravação é ativado, as instâncias em espera podem receber solicitações de gravação e, em seguida, encaminhá-las para a instância primária para processamento. Depois que os dados são gravados na instância primária, os dados são sincronizados com todas as instâncias em espera. O encaminhamento de gravação simplifica o processo de gravação de dados. Você pode conectar diretamente um serviço de banco de dados por meio do endereço IP de uma instância em espera para executar operações de leitura e gravação. Além disso, a consistência é garantida e a leitura próxima não é afetada.

- O encaminhamento de gravação só está disponível quando o nível de isolamento de transação das instâncias em espera é RR.
- Na versão atual, as informações de WARNING e RECORD não podem ser exibidas quando uma instância em espera encaminha solicitações de gravação.
- Na versão atual, as solicitações SQL que estão sendo executadas não podem ser interrompidas quando uma instância em espera encaminha solicitações de gravação.
- Quando o encaminhamento de gravação está ativado, o usuário _@gdb_WriteForward@_ é criado. Não modifique ou exclua o usuário, ou o encaminhamento de gravação não pode ser executado corretamente.
- Os seguintes comandos são suportados para encaminhamento de gravação:
- SQLCOM_UPDATE
- SQLCOM_INSERT
- SQLCOM_DELETE
- SQLCOM_INSERT_SELECT
- SQLCOM_REPLACE
- SQLCOM_REPLACE_SELECT
- SQLCOM_DELETE_MULTI
- SQLCOM_UPDATE_MULTI
- SQLCOM_ROLLBACK
Se um comando não suportado for executado, as seguintes informações de erro serão exibidas.ERROR xxx (yyy): This version of MySQL doesn't yet support 'operation with write forwarding'.
operation indica o tipo de operação que não é suportado.
- Os seguintes cenários não são suportados:
- Existem instruções SELECT FOR UPDATE.
- Existem instruções de encaminhamento de gravação EXPLAIN.
- As instruções para encaminhamento de gravação contêm SET VARIABLE.
- SAVEPOINT não é suportado quando o encaminhamento de gravação está ativado.
- O encaminhamento de gravação não é suportado em transações XA.
- Atualmente, START TRANSACTION READ WRITE não é suportado. Você pode usar diretamente START TRANSACTION para testar o encaminhamento de gravação.
- Não há suporte para encaminhamento de gravação em procedimentos armazenados.
- Quando o encaminhamento de gravação está ativado, tabelas temporárias não podem ser criadas. Para criar tabelas temporárias, desative o encaminhamento de gravação temporariamente.
- Para comandos que podem ser implicitamente comprometidos, se o encaminhamento de gravação não for suportado, as transações correspondentes ao nó atual e ao nó primário serão confirmadas automaticamente.
- Para o nível de consistência global, antes de acessar os dados pela primeira vez, cada transação precisa usar uma conexão no pool de sessões para obter um ponto de dados (LSN) do nó primário. Se nenhuma sessão estiver disponível, o comando para ler dados poderá falhar.
- Se houver um erro de conexão quando um usuário usar uma sessão para encaminhamento de gravação e o usuário estiver em uma transação de várias instruções, o servidor fechará proativamente as conexões com o cliente e o nó primário, garantindo que o cliente possa detectar o erro.
- As versões das instâncias primária e em espera devem ser as mais recentes.
- As operações de gravação são finalmente encaminhadas e processadas pelo nó primário. Se uma tabela temporária com o mesmo nome existir no banco de dados especificado das réplicas primária e de leitura, os dados no nó primário serão usados.
- Se houver uma alternância ou failover primário/em espera para uma instância em espera em um cluster de BD sem região, os parâmetros de encaminhamento de gravação (rds_open_write_forwarding e rds_write_forward_read_consistency) são restaurados para os valores padrão.
- Na página RegionlessDB, localize o cluster de RegionlessDB.
- Clique em Set Write Forwarding na coluna Operation para criar uma conta de encaminhamento de gravação. Figura 5 Criar uma conta de encaminhamento de gravação

O sistema cria automaticamente uma conta interna (_@gdb_WriteForward@_) para que as solicitações de gravação possam ser encaminhadas para a instância primária para processamento. Você não pode modificar ou excluir a conta interna, ou o encaminhamento de gravação será afetado.
- Na caixa de diálogo Set Write Forwarding, confirme as informações e clique em OK. Figura 6 Configurar o encaminhamento de gravação

- Na página Instances, clique no nome da instância em espera no cluster de RegionlessDB.
- No painel de navegação, escolha Parameters.
- Procure por rds_open_write_forwarding no canto superior direito da página Parameters e altere seu valor para ON.
- Clique em Save no canto superior esquerdo para ativar o encaminhamento de gravação.
- Pesquise rds_write_forward_read_consistency no canto superior direito da página Parameters e altere o nível de consistência de leitura do encaminhamento de gravação.
Você pode modificar os parâmetros para definir o intervalo de consistência de leitura. Para mais detalhes, consulte Tabela 3.
Tabela 3 Descrição do parâmetro Parâmetro
Descrição
NONE
O encaminhamento de gravação está desativado.
EVENTUAL
Os resultados das operações de gravação não são visíveis até que as operações de gravação sejam executadas na instância primária. A consulta não aguarda a conclusão da sincronização de dados entre instâncias primárias e em espera, portanto, os dados que não são atualizados podem ser lidos.
SESSION
Todas as consultas executadas por uma instância em espera com encaminhamento de gravação ativado mostram os resultados de todas as gravações de dados executadas nesta sessão. As consultas aguardam que os resultados das operações de gravação encaminhadas sejam replicados.
GLOBAL
Uma sessão pode exibir todas as alterações confirmadas de todas as sessões e instâncias em um cluster de BD sem região. A consulta pode esperar por um determinado período, que está relacionado à latência de replicação.
- Se a consistência de leitura for necessária, é aconselhável definir o nível de consistência como SESSION. O nível de consistência GLOBAL causará um grande custo extra para todas as solicitações de leitura. Por exemplo, se algum cliente for utilizado para se conectar ao TaurusDB e o nível GLOBAL for utilizado, o tempo de acesso à linha de comando do MySQL é prolongado.
- O nível de consistência de leitura no encaminhamento de gravação não pode ser alterado para SESSION em uma transação.
- Antes de ativar o encaminhamento de gravação, certifique-se de que os níveis de isolamento de transação das instâncias em espera sejam RR.
- Quando o encaminhamento de gravação está ativado, o nível de isolamento de transação da sessão atual não pode ser alterado.
- O nível de consistência de leitura não pode ser alterado em uma transação.
- Clique em Save no canto superior esquerdo.




