
Configuring Bot Protection Rules to Defend Against Bot Behavior
You can configure BOT protection rules to protect against search engines, scanners, script tools, and other crawlers, and use JavaScript to create custom anti-crawler protection rules.
Prerequisites
A protected website has been added. For details, see Adding a Website to EdgeSec.
Constraints
- Cookies must be enabled and JavaScript supported by any browser used to access a website protected by anti-crawler protection rules.
- It takes several minutes for a new rule to take effect. After the rule takes effect, protection events triggered by the rule will be displayed on the Events page.
- If your service is connected to CDN, exercise caution when using this function.
CDN caching may impact Anti-Crawler performance and page accessibility.
BOT Management Functions
BOT management supports the following functions based on the detection sequence:
Known bot detection is the first step. It compares the user agent (UA) keywords carried in user requests with the UA signature database in bot protection. If a request is from a known bot (known client), the request will be handled based on the configured protective action.
Based on the open-source UA signature intelligence on the Internet and the UA signature library for anti-crawler protection, EdgeSec can detect 10 types of known bots.
|
Type |
Description |
|---|---|
|
Web Search Engine Bots |
Search engines use web crawlers to aggregate and index online content (such as web pages, images, and other file types). They provide search results in real time. |
|
Web Scanners |
Virus/Vulnerability scanners detect viruses or vulnerabilities caused by configuration errors or programming defects in network assets. Typical scanners include Nmap, sqlmap, and WPSec. |
|
Web Scrapers |
Popular crawler tools or services on the Internet. They are often used to capture any web page and extract content to meet user requirements. Scrapy, pyspider, and Prerender are typical ones. |
|
Site Monitoring or Web Development Bots |
These bots help web developers monitor the performance of their sites. Apart from DNS resolution errors and other issues, they also check link and domain availability, connection speeds, and web page load times from different geographical locations. |
|
SEO or BIOR Marketing Bots |
SEO helps websites or web pages rank higher in search engine results. SEO companies often use bots to analyze website content, audience, and competitiveness for online advertising and marketing. |
|
News, Social Media or Blog Bots |
News and social media platforms offer users trending news and interaction. Companies also use these platforms to engage with consumers about their products or services as part of their marketing efforts. They may use bots to collect data from these platforms for insights. |
|
Website Screenshot Creator |
Some companies use bots to provide website screenshot services. It can take complete long-screen screenshots of online content such as posts on websites and social networks, news, and posts on forums and blogs. |
|
Academic or Research Bots |
Universities and companies use bots to collect data from a range of websites for academic or research purposes. This data collection involves reference searches, semantic analysis, and specialized search engines. |
|
RSS Feed Reader Bots |
Universities and companies use bots to collect data from a range of websites for academic or research purposes. This data collection involves reference searches, semantic analysis, and specialized search engines. |
|
Web Archiver Bots |
Wikipedia and other organizations use bots to regularly crawl and archive valuable online information and content copies from the web. These archives are similar to search engine results, but older. They are mainly used for research. |
Signature-based request detection is the second step. This approach identifies the HTTP request header features in user requests, matches mainstream development frameworks and HTTP libraries, stimulates known bots, and uses automated programs to detect bots. If a request matches a bot signature, the request will be handled based on the configured protective action.
|
Type |
Description |
|---|---|
|
HTTP request header detection |
Abnormal request header |
|
Development framework and HTTP library |
Popular development frameworks and HTTP libraries include Apache HttpComponents, OKHttp, Python requests, and Go HTTP client. |
|
Other |
|
Bot behavior detection is the third step. EdgeSec uses an AI protection engine to analyze and automatically learn requests, and then handles the attack behavior based on the configured behavior detection score and protective action.
You can set three score ranges for bot behavior detection. Score range: 0 to 100. A score closer to 0 indicates that the request feature is more like a normal request, and a score closer to 100 indicates that the request feature is more like a bot.
How JavaScript Anti-Crawler Protection Works
Figure 1 shows how JavaScript anti-crawler detection works, which includes JavaScript challenges (step 1 and step 2) and JavaScript authentication (step 3).

If JavaScript anti-crawler is enabled when a client sends a request, EdgeSec returns a piece of JavaScript code to the client.
- If the client sends a normal request to the website, triggered by the received JavaScript code, the client will automatically send the request to EdgeSec again. EdgeSec then forwards the request to the origin server. This process is called JavaScript verification.
- If the client is a crawler, it cannot be triggered by the received JavaScript code and will not send a request to EdgeSec again. The client fails JavaScript authentication.
- If a client crawler fabricates an EdgeSec authentication request and sends the request to EdgeSec, the EdgeSec will block the request. The client fails JavaScript authentication.
By collecting statistics on the number of JavaScript challenges and authentication responses, the system calculates how many requests the JavaScript anti-crawler defends. In Figure 2, the JavaScript anti-crawler has logged 18 events, 16 of which are JavaScript challenge responses, and 2 of which are JavaScript authentication responses. Others is the number of EdgeSec authentication requests fabricated by the crawler.


EdgeSec only logs JavaScript challenge and JavaScript authentication events. No other protective actions can be configured for JavaScript challenge and authentication.
Configuring a Bot Protection Rule
- Log in to the EdgeSec console.
- In the navigation pane on the left, choose . The Website Settings page is displayed.
- In the Policy column of the row containing the domain name, click the number to go to the Policies page.
Figure 3 Website list

- In the BOT Management configuration area, you can change the Status as required by referring to the Figure 4 and click Configure BOT Mitigation.
- On the Known bots, Signature-based requests, or Bot behavior detection card, configure rules.

- Click the Known BOT Detection module, click the
 icon on the left of a protection rule, select the required detection items, and toggle on the Enable/Disable switch.
Figure 5 shows the default configurations after you enable this function.
icon on the left of a protection rule, select the required detection items, and toggle on the Enable/Disable switch.
Figure 5 shows the default configurations after you enable this function. - Enable or disable a specific rule and configure protective actions based on your service requirements.
The protective actions are as follows:
- Log only: EdgeSec only logs requests that match the features.
- JS Challenge: After identifying the feature, EdgeSec returns a segment of JavaScript code that can be automatically executed by a normal browser to the client. If the client properly executes the JavaScript code, EdgeSec allows all requests from the client within a period of time (30 minutes by default). During this period, no verification is required. If the client fails to execute the code, EdgeSec blocks the requests.
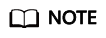
If the referer in the request is different from the current host, the JS challenge does not work.
- Block: EdgeSec blocks requests that match the features.
- Allow: EdgeSec allows requests that match the features to pass.
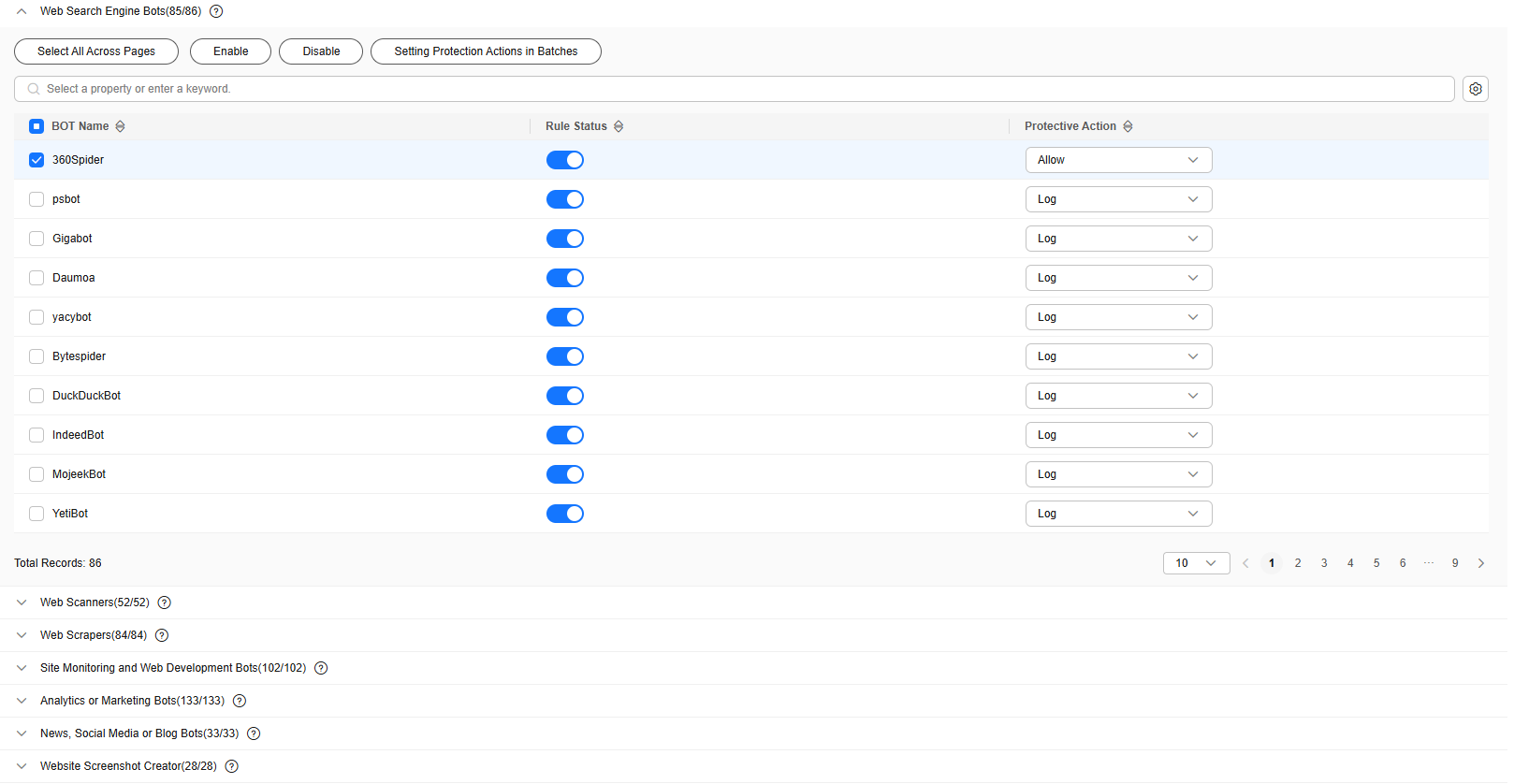
- Click the Request Feature Detection module, click the
 icon on the left of a protection rule, select the required detection items, and toggle on the Enable/Disable switch.
Figure 6 shows the default configurations after you enable this function.
icon on the left of a protection rule, select the required detection items, and toggle on the Enable/Disable switch.
Figure 6 shows the default configurations after you enable this function. - Enable or disable a specific rule and configure protective actions based on your service requirements.
The protective actions are as follows:
- Log only: EdgeSec only logs requests that match the features.
- JS Challenge: After identifying the feature, EdgeSec returns a segment of JavaScript code that can be automatically executed by a normal browser to the client. If the client properly executes the JavaScript code, EdgeSec allows all requests from the client within a period of time (30 minutes by default). During this period, no verification is required. If the client fails to execute the code, EdgeSec blocks the requests.
If the referer in the request is different from the current host, the JS challenge does not work.
- Block: EdgeSec blocks requests that match the features.
- Allow: EdgeSec allows requests that match the features to pass.
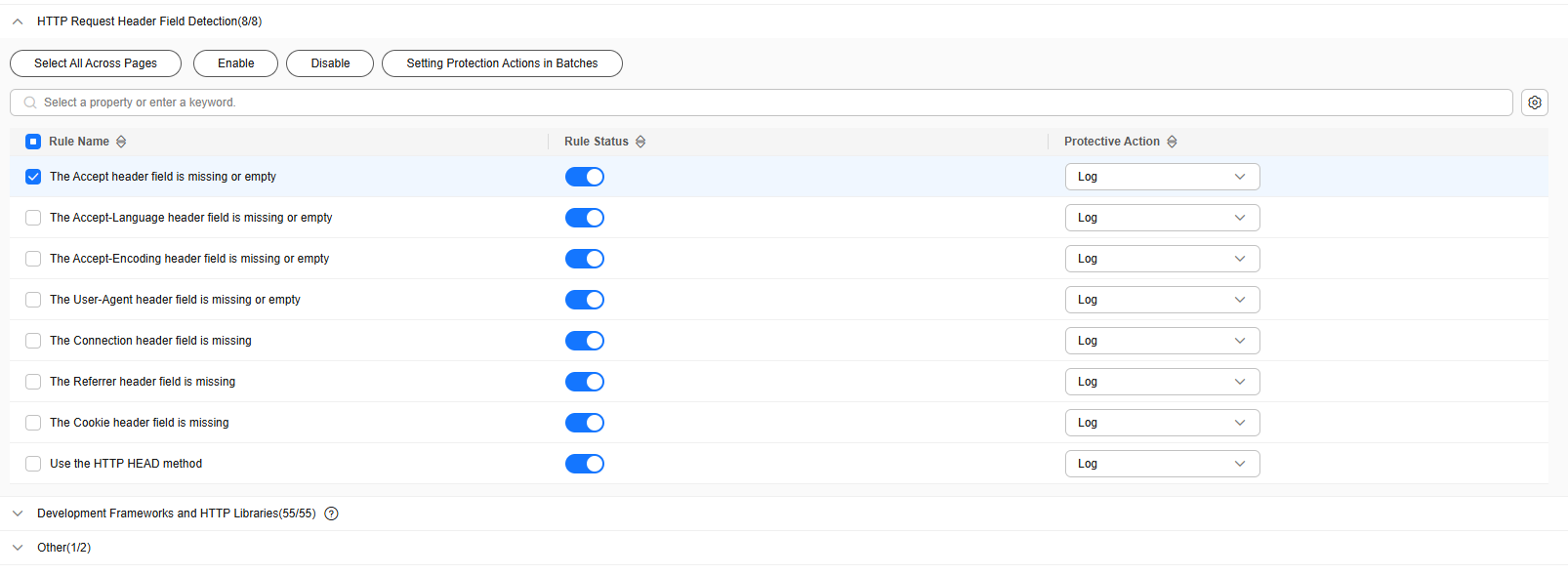
- Click the BOT behavior card and enable AI-based behavior detection.
Figure 7 shows the default configurations after you enable this function.
- Set three behavior detection score ranges based on service requirements. The score range is 0 to 100. A score closer to 0 indicates that the request feature is more like a normal request, and a score closer to 100 indicates that the request feature is more like a bot.
- Configure a protective action for each score range.
The protective actions are as follows:
- Log only: EdgeSec only logs requests that match the features.
- JS Challenge: After identifying the feature, EdgeSec returns a segment of JavaScript code that can be automatically executed by a normal browser to the client. If the client properly executes the JavaScript code, EdgeSec allows all requests from the client within a period of time (30 minutes by default). During this period, no verification is required. If the client fails to execute the code, EdgeSec blocks the requests.
If the referer in the request is different from the current host, the JS challenge does not work.
- Block: EdgeSec blocks requests that match the features.
- Allow: EdgeSec allows requests that match the features to pass.
JavaScript
- Log in to the EdgeSec console.
- In the navigation pane on the left, choose . The Website Settings page is displayed.
- In the Policy column of the row containing the domain name, click the number to go to the Policies page.
Figure 8 Website list
- In the BOT Management configuration area, you can change the Status as required by referring to the Figure 9.
- Select the JavaScript tab and configure Status and Protective Action.
JavaScript anti-crawler is disabled by default. To enable
 it, click
it, click  and click OK in the displayed dialog box.
and click OK in the displayed dialog box.A JS anti-crawler rule provides three protective actions:
- Block: After a JavaScript challenge fails, the system immediately blocks the request and records the failure.
- Log only: After the JavaScript challenge fails, the system only records the failure but does not block the request.
- Verification code: After the JavaScript challenge fails, a verification code is used for verification.
- Cookies must be enabled and JavaScript supported by any browser used to access a website protected by anti-crawler protection rules.
- If your service is connected to CDN, exercise caution when using the JS anti-crawler function.
CDN caching may impact JS anti-crawler performance and page accessibility.
- Configure a JavaScript-based anti-crawler rule by referring to Table 1.
Two protective actions are provided: Protect all requests and Protect specified requests.
- To protect all requests except requests that hit a specified rule
- To protect a specified request only
Set Protection Mode to Protect specified requests, click Add Rule, configure the request rule, and click Confirm.
Figure 11 Add Rule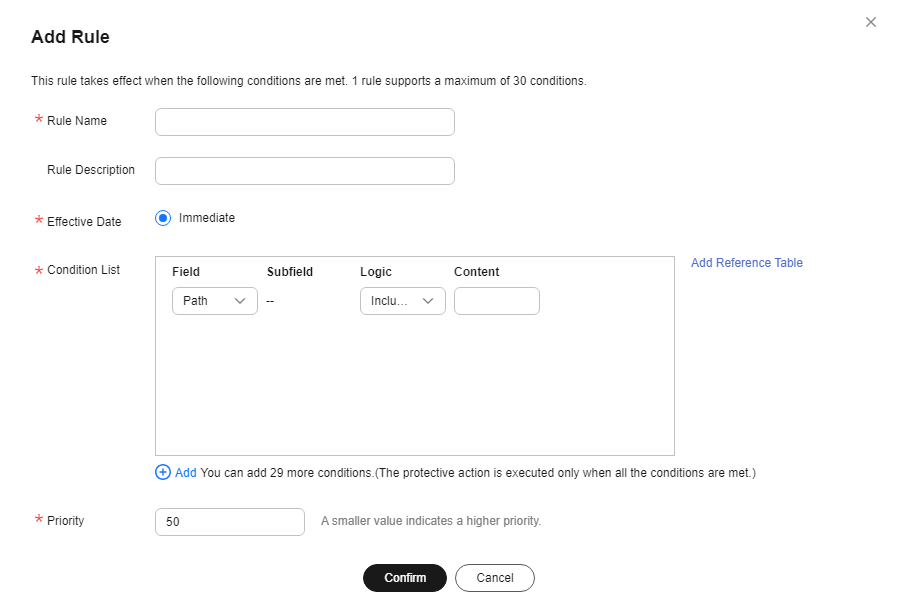
Table 1 Parameters of a JavaScript-based anti-crawler protection rule Parameter
Description
Example Value
Rule Name
Name of the rule
EdgeSec
Rule Description
A brief description of the rule. This parameter is optional.
-
Effective Date
Time the rule takes effect.
Immediate
Condition List
Parameters for configuring a condition are described as follows:
- Field: Select the field you want to protect from the drop-down list. Currently, only Path and User Agent are included.
- Subfield
- Logic: Select a logical relationship from the drop-down list.
NOTE:
When Logic is set to Include any value, Exclude any value, Equal to any value, Not equal to any value, Prefix is any value, Prefix is any of them, Suffix is any value, or Suffix is any of them, you need to select a reference table name for Content. For details about how to create a reference table, see Creating a Reference Table to Configure Protection Metrics In Batches.
- Content: Enter or select the content that matches the condition.
Path Include /admin
Priority
Rule priority. If you have added multiple rules, rules are matched by priority. The smaller the value you set, the higher the priority.
5
Other Operations
- To modify a rule, click Edit in the row containing the rule.
- To delete a rule, click Delete in the row containing the rule.
Configuration Example - Search Engine
The following shows how to allow the search engine of Baidu or Google and block the POST request of Baidu.
- Set Status of Search Engine Bot to
 by referring to the instructions in 1.
by referring to the instructions in 1. - Configure a precise protection rule by referring to Configuring Custom Precise Protection Rules.
Figure 12 Blocking POST requests

Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



