
From MySQL to MRS Hudi
This section describes how to configure the parameters of a real-time processing migration job for synchronizing data from one or more MySQL instances to an MRS Hudi database.
- DDL supports new columns.
- Hudi destination configuration
- You can configure the rule for mapping source and destination database names and table names so that you can rename Hudi databases and tables.
- You can migrate Hudi tables to HDFS and OBS at the same time.
- Automatic table creation is supported for Hudi.
- You can add simple additional fields to Hudi tables.
- You can configure the partition information for Hudi tables, including defining Hudi tables without partition, with time partitions, or with custom partition.
- You can define global Hudi table configuration as required or define the configuration of a single Hudi table.
- Out-of-the-box default configurations for built-in Hudi tables, such as compaction behavior and table types
- Soft deletion of data
Notes and Constraints
- Ensure that only one migration job is writing data to the same Hudi table in the same period. Otherwise, data writing conflicts may occur, causing job failures.
- The minimum permissions including SELECT, SHOW DATABASES, REPLICATION SLAVE, and REPLICATION CLIENT must be configured for the source MySQL database through the following SQL statement:
GRANT SELECT, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'Username'@'%';
Entire DB Scenario
- Configure source parameters.
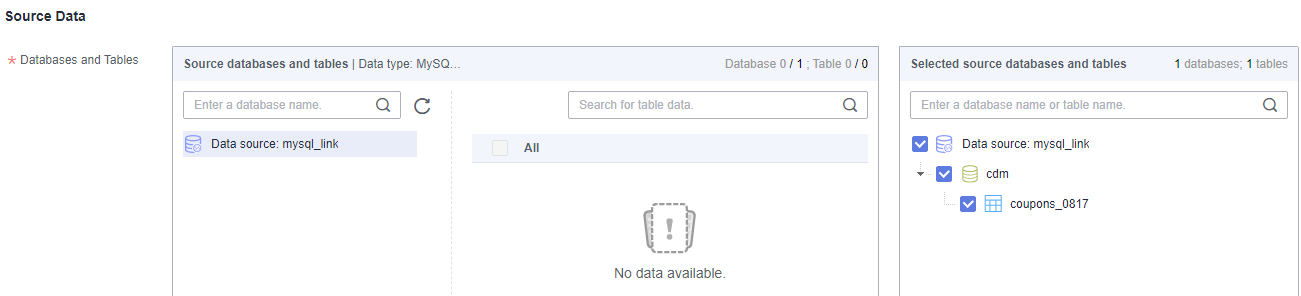
Both databases and tables can be customized. You can select one database and one table, or multiple databases and tables.
- Configure destination parameters.
Figure 2 Configuring destination parameters
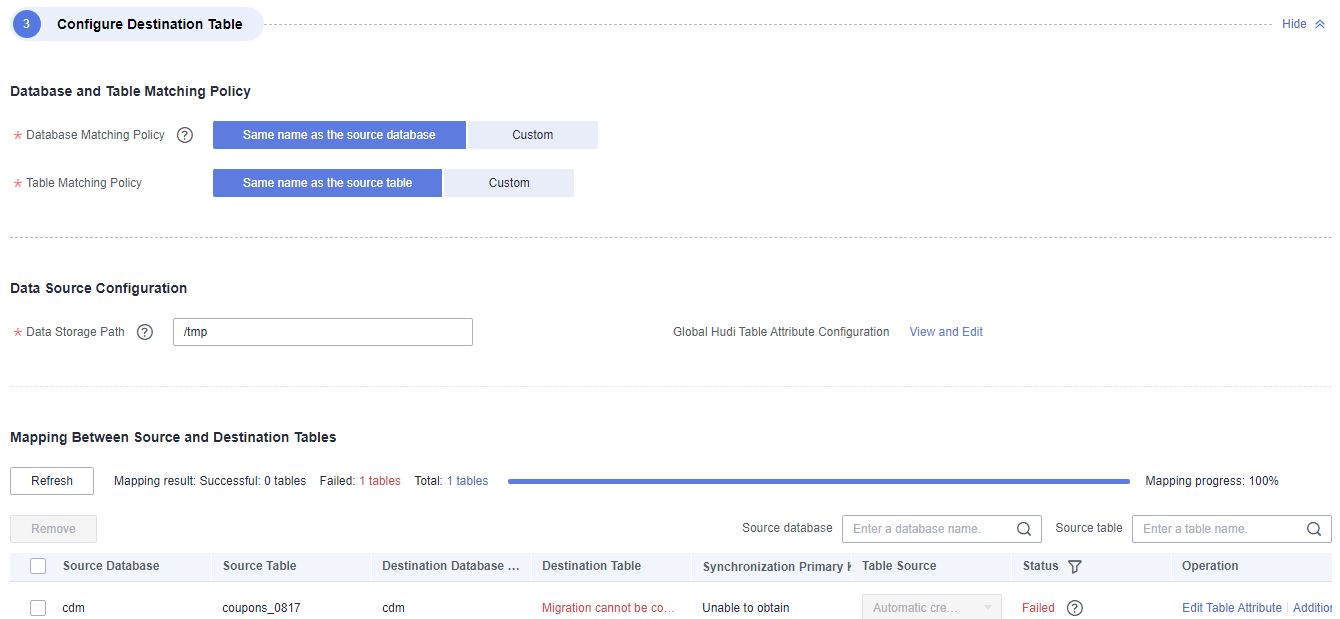
- Database and Table Matching Policy:
- Database Matching Policy: Configure a matching policy for the destination database so that data can be migrated to the destination database as planned.
You need to create the corresponding database in advance. Otherwise, automatic table creation may fail.
- Same name as the source database: Data will be migrated to the destination database with the same name as the source database.
- Custom: You can specify the destination database name or use #{source_db_name} to add a custom field to the source database name to change it to the name of the destination database of the Hudi table.
- Table Matching Policy: Configure a matching policy for the destination table so that data can be migrated to the destination table as planned.
You do not need to create the corresponding data table in advance. A table will be automatically created.
- Same name as the source table: Data will be migrated to the destination table with the same name as the source table.
- Custom: You can specify the destination table name or use the built-in parameter #{source_table_name} to add a prefix or suffix to the source table name to change it to the name of the destination Hudi table.
- Database Matching Policy: Configure a matching policy for the destination database so that data can be migrated to the destination database as planned.
- Data Source Configuration:
- Data Storage Path: basic path for storing Hudi data. This path takes effect only for automatically created tables. A subdirectory is created in the basic path for each destination table. HDFS and OBS paths are supported.
- OBS format: obs://{Bucket name}
- HDFS format: /tmp
- Global Configuration of Hudi Table Attributes: Click View and Edit to configure the global configuration of Hudi table attributes.
The attributes configured here apply to all Hudi tables. For details about Hudi configuration items, visit the Hudi official website.
If an attribute is configured for a specific table, the attribute value set here will be overwritten.
- Mapping Between Source and Destination Tables
Figure 3 Configuring the mapping between source and destination tables

- The primary key must be set for Hudi tables. If the source table has no primary key, you must manually select the primary key during field mapping.
- Edit table attributes: Click Edit Table Attributes in the Operation column to configure Hudi table attributes, including the table type, partition type, and custom attributes.
Table Type: MERGE_ON_READ or COPY_ON_WRITE
Partition Type: No partition, Time partition, or Custom partition
For Time partition, you need to specify a source table name and select a time conversion format.
For example, you can specify the source table name src_col_1 and select a time conversion format, for example, day(yyyyMMdd), month(yyyyMM), or year(yyyy). During automatic table creation, a cdc_partition_key field is created in the Hudi table by default. The system formats the value of the source field src_col_1 based on the configured time conversion format and writes the value to cdc_partition_key.
Custom partition: Select one or more source fields as partitions and separate them with commas (,).
- Edit additional field: Click Edit Additional Field in the Operation column to add custom fields to the migrated Hudi table.
Table 1 Supported additional field values Type
Example
Constant
-
Built-in variable
- Source host IP address: source.host
- Source schema name: mgr.source.schema
- Source table name: mgr.source.table
- Destination schema name: mgr.target.schema
- Destination table name: mgr.target.table
Field variable
-
UDF
- substring(#col, pos[, len]): obtains a substring of a specified length from the source column name. The substring range is [pos, pos+len).
- date_format(#col, time_format[, src_tz, dst_tz]): formats the source column name based on a specified time format. The time zone can be converted using src_tz and dst_tz.
- now([tz]): obtains the current time in a specified time zone.
- if(cond_exp, str1, str2): returns str1 if the condition expression cond_exp is met and returns str2 otherwise.
- concat(#col[, #str, ...]): concatenates multiple parameters, including source columns and strings.
- from_unixtime(#col[, time_format]): formats a Unix timestamp based on a specified time format.
- unix_timestamp(#col[, precision, time_format]): converts a time into a Unix timestamp of a specified time format and precision.
For a new table, you can add additional fields to the existing fields in the source table. You can customize the field name (for example, custom_defined_col), select the field type, and enter the field value.
You can add multiple additional fields at a time.
- Automatic table creation: Click Auto Table Creation to automatically create tables in the list based on the configured rules. After the tables are created, Existing table is displayed them.
- Data Storage Path: basic path for storing Hudi data. This path takes effect only for automatically created tables. A subdirectory is created in the basic path for each destination table. HDFS and OBS paths are supported.
- Database and Table Matching Policy:
Database/Table Partition Scenario
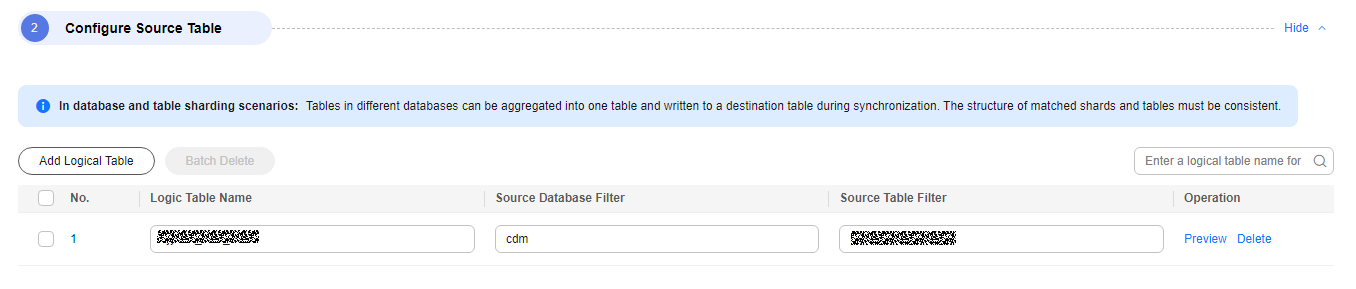
Tables in different databases can be aggregated into one table and written to a destination table during synchronization. The structure of matched shards and tables must be consistent.
- Configure source parameters.
Figure 4 Adding a logical table
You can click Preview in the Operation column to preview an added logical table.
The more source tables there are, the longer it takes to preview a logical table. The wait time can range from a few to dozens of minutes.
Figure 5 Previewing a logical table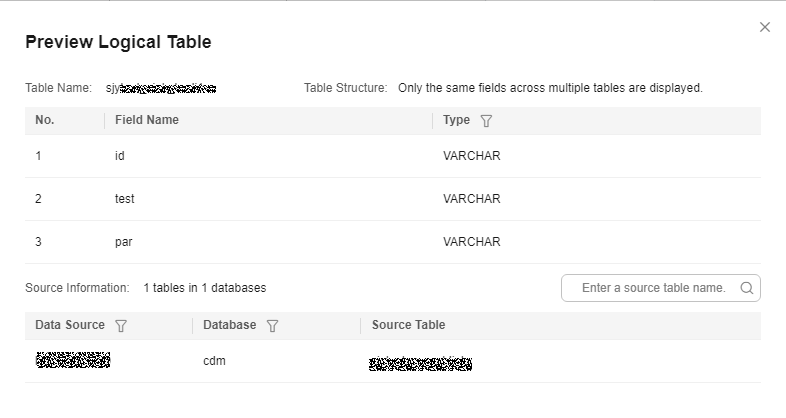
- Configure destination parameters.
- Database and Table Matching Policy:
- Destination Database Name: Enter a custom destination database name.
- Table Matching Policy: The default value is the same as the name of the source logical table and cannot be changed.
- Data Source Configuration:
- Data Storage Path: basic path for storing Hudi data. This path takes effect only for automatically created tables. A subdirectory is created in the basic path for each destination table. HDFS and OBS paths are supported. The format is OBS:obs://{Bucket name} or HDFS:/.
- Global Configuration of Hudi Table Attributes: Click View and Edit to configure the global configuration of Hudi table attributes.
The attributes configured here apply to all Hudi tables. For details about Hudi configuration items, visit the Hudi official website.
If an attribute is configured for a specific table, the attribute value set here will be overwritten.
- Mapping Between Source and Destination Tables
Figure 6 Configuring the mapping between source and destination tables
- The primary key must be set for Hudi tables. If the source table has no primary key, you must manually select the primary key during field mapping.
- Edit table attributes: Click Edit Table Attributes in the Operation column to configure Hudi table attributes, including the table type, partition type, and custom attributes.
Table Type: MERGE_ON_READ or COPY_ON_WRITE
Partition Type: No partition, Time partition, or Custom partition
For Time partition, you need to specify a source table name and select a time conversion format.
For example, you can specify the source table name src_col_1 and select a time conversion format, for example, day(yyyyMMdd), month(yyyyMM), or year(yyyy). During automatic table creation, a cdc_partition_key field is created in the Hudi table by default. The system formats the value of the source field src_col_1 based on the configured time conversion format and writes the value to cdc_partition_key.
Custom partition: Select one or more source fields as partitions and separate them with commas (,).
- Edit additional field: Click Edit Additional Field in the Operation column to add custom fields to the migrated Hudi table.
Table 2 Supported additional field values Type
Example
Constant
-
Built-in variable
- Source host IP address: source.host
- Source schema name: mgr.source.schema
- Source table name: mgr.source.table
- Destination schema name: mgr.target.schema
- Destination table name: mgr.target.table
Field variable
-
UDF
- substring(#col, pos[, len]): obtains a substring of a specified length from the source column name. The substring range is [pos, pos+len).
- date_format(#col, time_format[, src_tz, dst_tz]): formats the source column name based on a specified time format. The time zone can be converted using src_tz and dst_tz.
- now([tz]): obtains the current time in a specified time zone.
- if(cond_exp, str1, str2): returns str1 if the condition expression cond_exp is met and returns str2 otherwise.
- concat(#col[, #str, ...]): concatenates multiple parameters, including source columns and strings.
- from_unixtime(#col[, time_format]): formats a Unix timestamp based on a specified time format.
- unix_timestamp(#col[, precision, time_format]): converts a time into a Unix timestamp of a specified time format and precision.
For a new table, you can add additional fields to the existing fields in the source table. You can customize the field name (for example, custom_defined_col), select the field type, and enter the field value.
You can add multiple additional fields at a time.
- Automatic table creation: Click Auto Table Creation to automatically create tables in the list based on the configured rules. After the tables are created, Existing table is displayed them.
- Database and Table Matching Policy:
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



