
ALTER TABLE PARTITION
Function
ALTER TABLE PARTITION is used to modify table partitions, including adding, deleting, splitting, merging partitions, migrating data from ordinary tables to partitioned tables, and modifying partition attributes.
A partitioned table is a logical table that is divided into segments, called partitions whose data is stored on different physical blocks.
Common partitioning strategies define data ranges based on one or more columns. Each partition stores data within a range. These columns are called partition keys.
Currently, DWS row-store and column-store tables support range partitioning and list partitioning.
- Range partitioning
A table is partitioned into ranges defined by a key column or set of columns, with no overlap between the ranges of values assigned to different partitions. Each range has a dedicated partition for data storage.
- Core feature: Data is distributed by consecutive intervals. It is used in scenarios where data is ordered and retrieved by range.
- Scenario: Partition keys increase linearly or have continuous intervals. Data query is usually performed around a certain range, and new data naturally falls into a new range. For example, data about orders is partitioned by time range, and data about user levels is partitioned by value range.
- Range partitioning maps data to partitions based on ranges of values of the partitioning key that you establish for each partition. This is the most commonly used partitioning policy. Currently, range partitioning only allows the use of the range partitioning policy.
- List partitioning
List partitioning allocates records to partitions based on the key values in each partition. The key values do not overlap in different partitions. Each set of key values gets its own partition for storing related data. List partitioning is supported only by clusters of version 8.1.3 or later.
- Core feature: Data is divided based on discrete enumerated values, which are used as fixed classification category or high-frequency filter criteria.
- Scenario: Partition key values are fixed and discrete. Data query is usually based on a certain category, and key values do not increase irregularly. For example, the user information table is partitioned by province, and each province corresponds to a partition.
- In list partitioning, data is mapped to a created partition based on the partition key value. If the data can be mapped to, it is inserted into the specific partition. If it cannot be mapped to, error messages are returned.
Precautions
- The name of the partition to be added cannot be the same as that of an existing partition in the partitioned table.
- For a range partitioned table, the boundary value of the added partition must be the same type as the partition key of the partitioned table. The key value of the added partition must exceed the upper limit of the last partition.
- For a list partitioned table, if the DEFAULT partition has been defined, no new partition can be added.
- Unless otherwise specified, the syntax of range partitioned tables is the same as that of column-store partitioned tables.
- If the number of partitions in the target partitioned table has reached the maximum (32767), partitions cannot be added.
- If a partitioned table has only one partition, the partition cannot be deleted.
- When you run the DROP PARTITION command to delete a partition, the data in the partition is also deleted.
- Use PARTITION FOR() to choose partitions. The number of specified values in the brackets should be the same as the column number in customized partition, and they must be consistent.
- The Value partitioned table does not support the Alter Partition operation.
- For OBS hot and cold tables:
- They do not support specifying the partition table's tablespace as the OBS tablespace for MOVE, EXCHANGE, MERGE, and SPLIT operations.
- When an ALTER statement is executed, the data in the cold partition should stay in the cold partition, and the data in the hot partition should remain in the hot partition. It is not allowed to move cold partition data to the local tablespace.
- Only the default tablespace is supported for cold partitions.
- Cold and hot partitions cannot be merged.
- Cold partition switching is not supported during the EXCHANGE operation.

- Avoid performing ALTER TABLE, ALTER TABLE PARTITION, DROP PARTITION, and TRUNCATE operations during peak hours to prevent long SQL statements from blocking these operations or SQL services.
- For more information about development and design specifications, see Development and Design Proposal.
Syntax
1 2 | ALTER TABLE [ IF EXISTS ] { table_name [*] | ONLY table_name | ONLY ( table_name )} action [, ... ]; |
action indicates the following clauses for maintaining partitions. For the partition continuity when multiple clauses are used for partition maintenance, DWS does DROP PARTITION and then ADD PARTITION, and finally runs the rest clauses in sequence.
- MODIFY PARTITION: Setting Whether a Partitioned Index Is Available
- REBUILD PARTITION syntax: Rebuilding a Partitioned Index
- EXCHANGE PARTITION: Moving the Data from an Ordinary Table to a Specified Partition
- ROW MOVEMENT: Setting the Row Movement Switch of a Partitioned Table
- MERGE PARTITIONS: Merging Partitions Into One
- SPLIT PARTITION: Splitting One Partition into Multiple Ones
- ADD PARTITION Sub-syntax: Adding One or More Partitions to a Specified Partitioned Table
- DROP PARTITION Sub-syntax: Deleting a Specified Partition or Multiple Partitions from a Partitioned Table
- TRUNCATE PARTITION: Clearing Data in a Table Partition
ALTER TABLE PARTITION Main Clause Parameters
| Parameter | Description | Value Range |
|---|---|---|
| table_name | Specifies the name of the partitioned table to be modified. | Name of an existing partitioned table. |
| action [, ... ] | Specifies clauses for maintaining partitions. For the partition continuity when multiple clauses are used for partition maintenance, DWS does DROP PARTITION and then ADD PARTITION, and finally runs the rest clauses in sequence. | For details, see the following clauses. |
| partition_name | Specifies the name of the partition to be modified. | Name of an existing partition. |
| partition_value | Specifies the key value of a partition. The value specified by PARTITION FOR ( partition_value [, ...] ) can uniquely identify a partition. | Value range of the partition key of the partition to be renamed. |
MODIFY PARTITION: Setting Whether a Partitioned Index Is Available
1 2 | ALTER TABLE [ IF EXISTS ] { table_name [*] | ONLY table_name | ONLY ( table_name )} MODIFY PARTITION partition_name { UNUSABLE LOCAL INDEXES | REBUILD UNUSABLE LOCAL INDEXES } |
| Parameter | Description | Value Range |
|---|---|---|
| partition_name | Specifies the name of the partition to be modified. | Name of an existing partition. |
| UNUSABLE LOCAL INDEXES | Sets all the indexes unusable in the partition. | - |
| REBUILD UNUSABLE LOCAL INDEXES | Rebuilds all the indexes in the partition. | - |
REBUILD PARTITION syntax: Rebuilding a Partitioned Index
REBUILD PARTITION can rebuild indexes in a partitioned table. It is mainly used to restore the unusable partitioned indexes caused by abnormal operations (such as a large number of partition data changes and index damage) or optimize the partitioned index performance. Compared with rebuilding indexes in an entire table, rebuilding indexes in a partitioned table takes less resources and shorter time.
Typical application scenarios
- Repairing invalid partitioned indexes: After a partition executes a large number of DML operations (such as batch deletion and update) or is interrupted unexpectedly, the partitioned indexes may become unusable. In this case, you need to rebuild the indexes.
- Performance optimization: For a partitioned table that has been running for a long time, indexes may have fragments. Rebuilding the indexes can optimize the index structure and improve the query efficiency.
- Partition data exchange: After partition data is exchanged using EXCHANGE PARTITION, indexes may need to be rebuilt to ensure consistency.
This syntax is supported only by clusters of version 8.3.0.100 or later.
1 2 | ALTER TABLE [ IF EXISTS ] { table_name [*] | ONLY table_name | ONLY ( table_name )} REBUILD PARTITION partition_name [ WITHOUT UNUSABLE ] |
| Parameter | Description | Value Range |
|---|---|---|
| WITHOUT UNUSABLE | Ignores indexes in the UNUSABLE state when indexes on a partition are rebuilt. | - |
EXCHANGE PARTITION: Moving the Data from an Ordinary Table to a Specified Partition
EXCHANGE PARTITION is a key operation for efficiently managing partitioned tables in DWS. It can exchange metadata between a partition in a partitioned table and an ordinary table, instead of physically moving data. This means that the ownership of data blocks can be quickly switched, avoiding large-scale I/O operations and greatly improving performance.
Application scenarios:
- Batch data loading: It can load pre-processed data to a temporary table and then replace the data in the target partition, reducing the write pressure on the production table during peak hours.
- Historical data archiving: It can exchange partitions that are not frequently accessed to independent tables, facilitating migration to low-cost storage.
- Partition data repair: It can exchange the data of a faulty partition to a temporary table for correction and then exchange the data back to the partitioned table, reducing lock contention during the repair.
- Data migration: It can exchange the data of a specific partition across tables or databases to avoid inserting data one by one.
Syntax:
1 2 3 4 | ALTER TABLE [ IF EXISTS ] { table_name [*] | ONLY table_name | ONLY ( table_name )} EXCHANGE PARTITION { ( partition_name ) | FOR ( partition_value [, ...] ) } WITH TABLE {[ ONLY ] ordinary_table_name | ordinary_table_name * | ONLY ( ordinary_table_name )} [ { WITH | WITHOUT } VALIDATION ] [ VERBOSE ] |
| Parameter | Description | Value Range |
|---|---|---|
| partition_value | Specifies the key value of a partition. The value specified by PARTITION FOR ( partition_value [, ...] ) can uniquely identify a partition. | Value range of the partition key of the partition to be renamed. |
| ordinary_table_name | Specifies the name of the ordinary table whose data is to be migrated. | Name of an existing common table. |
| { WITH | WITHOUT } VALIDATION | Checks whether the ordinary table data meets the specified partition key range of the partition to be exchanged. The default value is WITH. The check is time consuming, especially when the data volume is large. Therefore, use WITHOUT when you are sure that the current ordinary table data meets the partition key range of the partition to be exchanged. |
|
| VERBOSE | When VALIDATION is WITH, if the ordinary table contains data that is out of the partition key range, insert the data to the correct partition. If there is no correct partition where the data can be route to, an error is reported. CAUTION: Only when VALIDATION is WITH, VERBOSE can be specified. | - |
The ordinary table and the partitioned table whose data is to be exchanged must meet the following requirements:
- The number of columns of the ordinary table is the same as that of the partitioned table, and their information should be consistent, including the column name, data type, constraint, collation, storage parameter, compression, and data type of a deleted column.
- The compression information of the ordinary table and partitioned table should be consistent.
- The distribution column information of the ordinary table and the partitioned table should be consistent.
- The number and information of indexes of the ordinary table and the partitioned table should be consistent.
- The number and information of constraints of the ordinary table and the partitioned table should be consistent.
- The ordinary table cannot be a temporary table or unlogged table.
- Exchanging partitions between an ordinary table and a partitioned table requires them to be in the same logical cluster or node group to avoid slow data insertion. Otherwise, the exchange operation becomes a slow data copy process, especially with large tables.
- In online scale-out and redistribution scenarios, the exchange partition statement may interfere with the redistribution of ordinary tables and partitioned tables (if there are lock conflicts between the partition exchange and redistribution statement). Usually, the redistribution of ordinary tables and partitioned tables is retried twice after being interrupted, but if a table is exchanged too often, the redistribution may fail for multiple times. If the redistribution process of an ordinary table is interrupted by the partition exchange operation, the data has been replaced with the data in the original partitioned table during the redistribution retry. In this case, full redistribution will be performed again.
- If other columns following the last valid column in the partitioned table are deleted and the deleted columns are not considered, the partitioned table can be exchanged with the ordinary table as long as the columns of the two tables are the same.
- The table-level parameter colversion must be consistent between the column-store ordinary table and the column-store partitioned table. The colversion 2.0 and colversion 1.0 cannot be exchanged.
When the exchange is done, the data and tablespace of the ordinary table and partitioned table are exchanged. In this case, statistics about the ordinary table and the partitioned table become unreliable. Both tables should be analyzed again.
ROW MOVEMENT: Setting the Row Movement Switch of a Partitioned Table
1 2 | ALTER TABLE [ IF EXISTS ] { table_name [*] | ONLY table_name | ONLY ( table_name )} { ENABLE | DISABLE } ROW MOVEMENT |
| Parameter | Description | Value Range |
|---|---|---|
| ENABLE/DISABLE ROW MOVEMENT | Specifies whether to relocate a row within a table. If the new value of a partition key in a row belongs to another partition, an error message is displayed or the row is moved to the corresponding partition.
The default value is DISABLE. CAUTION: To enable cross-partition update, you need to enable row movement. However, if SELECT FOR UPDATE is executed concurrently to query the partitioned table, the query results may be inconsistent. Therefore, exercise caution when performing this operation. | The date column (partition key) of a partitioned table is partitioned by quarter into p_2023q1 and p_2023q2. The value 2023-02-15 of a row belongs to the partition p_2023q1 in the first quarter. After the value is updated to 2023-05-15, you can configure ROW MOVEMENT to determine whether to move the data in this row.
For details, see Examples: Enabling and Disabling ROW MOVEMENT. |
MERGE PARTITIONS: Merging Partitions Into One
1 2 | ALTER TABLE [ IF EXISTS ] { table_name [*] | ONLY table_name | ONLY ( table_name )} MERGE PARTITIONS { partition_name } [, ...] INTO PARTITION partition_name |
- The partition before the keyword INTO is called the source partition, and the partition after the INTO is called the target partition.
- The number of source partitions cannot be less than 2.
- The source partition name must be unique.
- The source partition cannot have unusable indexes. Otherwise, an error will be reported.
- The target partition name must either be the same as the name of the last source partition or different from all partition names of the table.
- The boundaries of the target partition are the union of the boundaries of all the source partitions.
- For a range partitioned table, all source partitions must have contiguous boundaries.
- For list partitioning, if the source partition contains a DEFAULT partition, the boundary of the target partition is also DEFAULT.
SPLIT PARTITION: Splitting One Partition into Multiple Ones
split_clause specifies range partitioning.
1 2 | ALTER TABLE [ IF EXISTS ] { table_name [*] | ONLY table_name | ONLY ( table_name )} SPLIT PARTITION { partition_name | FOR ( partition_value [, ...] ) } { split_point_clause | no_split_point_clause } |
- split_point_clause:
1AT ( partition_value ) INTO ( PARTITION partition_name , PARTITION partition_name )

The size of split point should be in the range of splitting partition key. The split point can only split one partition into two.
- no_split_point_clause:
1INTO { ( partition_less_than_item [, ...] ) | ( partition_start_end_item [, ...] ) }
- The first new partition key specified by partition_less_than_item must be larger than that of the former partition (if any), and the last partition key specified by partition_less_than_item must be equal to that of the splitting partition.
- The start point (if any) of the first new partition specified by partition_start_end_item must be equal to the partition key (if any) of the previous partition. The end point (if any) of the last partition specified by partition_start_end_item must be equal to the partition key of the splitting partition.
- partition_less_than_item supports a maximum of four partition keys and partition_start_end_item supports only one partition key. For details about the supported data types, see the PARTITION BY RANGE(partition_key) parameter in Table 2.
- partition_less_than_item and partition_start_end_item cannot be used in the same statement. There is no restriction on different SPLIT statements.
- partition_less_than_item:
1 2
PARTITION partition_name VALUES LESS THAN ( { partition_value | MAXVALUE } [, ...] )
- partition_start_end_item (For details about the restrictions, see the partition_start_end_item parameter in Table 2).
1 2 3 4 5 6
PARTITION partition_name { {START(partition_value) END (partition_value) EVERY (interval_value)} | {START(partition_value) END ({partition_value | MAXVALUE})} | {START(partition_value)} | {END({partition_value | MAXVALUE})} }
1 2 | ALTER TABLE [ IF EXISTS ] { table_name [*] | ONLY table_name | ONLY ( table_name )} SPLIT PARTITION { partition_name | FOR ( partition_value [, ...] ) } { split_values_clause | split_no_values_clause } |
- split_values_clause specifies a split point.
1VALUES ( { (partition_value) [, ...] | DEFAULT } ) INTO ( PARTITION partition_name , PARTITION partition_name )
- If the source partition is not a DEFAULT partition, the boundary specified by the cut point is a non-null true subset of the source partition boundary. If the source partition is a DEFAULT partition, the boundary specified by the cut point cannot overlap with the boundaries of other non-DEFAULT partitions.
- The boundary specified by the split point is the boundary of the first partition after the keyword INTO. The difference between the boundary of the source partition and the specified boundary of the split point is the boundary of the second partition.
- If the source partition is the DEFAULT partition, the boundary of the second partition is still DEFAULT.
- split_no_values_clause specifies no split point is specified.
1INTO ( list_partition_item [, ....], PARTITION partition_name )
- The syntax of list_partition_item is the same as that of specifying the partition when creating a list partitioned table, except that the boundary value in the partition definition cannot be DEFAULT.
- Except for the last partition, the boundaries of other partitions must be explicitly defined. The defined boundary cannot be DEFAULT and must be a non-empty proper subset of the source partition boundary. The boundary of the last partition is the difference set between the source partition boundary and other partition boundaries, and the boundary of the last partition is empty (that is, the difference set cannot be empty).
- If the source partition is a DEFAULT partition, the boundary of the last partition is DEFAULT.
ADD PARTITION Sub-syntax: Adding One or More Partitions to a Specified Partitioned Table
1 2 | ALTER TABLE [ IF EXISTS ] { table_name [*] | ONLY table_name | ONLY ( table_name )} ADD { partition_less_than_item... | partition_start_end_item } |
- The partition_less_than_item syntax can only be used for range partitioned tables. Otherwise, an error will be reported.
- The syntax of partition_less_than_item is the same as the syntax specifying partitions in creating a range partitioned table.
- If the boundary value of the last partition is a MAXVALUE, new partitions cannot be added. Otherwise, an error will be reported.
add_clause specifies list partitioning.
1 2 | ALTER TABLE [ IF EXISTS ] { table_name [*] | ONLY table_name | ONLY ( table_name )} ADD list_partition_item |
- The list_partition_item syntax can only be used for a list partitioned table. Otherwise, an error will be reported.
- The list_partition_item syntax is the same as the syntax for specifying partitions when creating a list partitioned table.
- If the current partitioned table contains DEFAULT partitions, no new partitions can be added. Otherwise, an error will be reported.
DROP PARTITION Sub-syntax: Deleting a Specified Partition or Multiple Partitions from a Partitioned Table
1 2 | ALTER TABLE [ IF EXISTS ] { table_name [*] | ONLY table_name | ONLY ( table_name )} DROP PARTITION { partition_name | FOR ( partition_value [, ...] ) } |
1 2 | ALTER TABLE [ IF EXISTS ] { table_name [*] | ONLY table_name | ONLY ( table_name )} DROP PARTITION { partition_name [, ... ] } |
TRUNCATE PARTITION: Clearing Data in a Table Partition
1 2 | ALTER TABLE [ IF EXISTS ] { table_name [*] | ONLY table_name | ONLY ( table_name )} TRUNCATE PARTITION { partition_name | FOR ( partition_value [, ...] ) }; |
- partition_value indicates the partition key value. Multiple partition key values can be specified. Use commas (,) to separate multiple partition key values.
- When the PARTITION FOR clause is used, the entire partition where partition_value is located is cleared.
Syntax for Modifying a Partition Name
1 2 | ALTER TABLE [ IF EXISTS ] { table_name [*] | ONLY table_name | ONLY ( table_name )} RENAME PARTITION { partition_name | FOR ( partition_value [, ...] ) } TO partition_new_name; |
| Parameter | Description | Value Range |
|---|---|---|
| partition_new_name | Specifies the new name of the partition. | A string compliant with the identifier naming rules. |
Example: Create a Range Partitioned Table customer_address
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | DROP TABLE IF EXISTS customer_address; CREATE TABLE customer_address ( ca_address_sk INTEGER NOT NULL , ca_address_id CHARACTER(16) NOT NULL , ca_street_number CHARACTER(10) , ca_street_name CHARACTER varying(60) , ca_street_type CHARACTER(15) , ca_suite_number CHARACTER(10) ) DISTRIBUTE BY HASH (ca_address_sk) PARTITION BY RANGE(ca_address_sk) ( PARTITION P1 VALUES LESS THAN(100), PARTITION P2 VALUES LESS THAN(200), PARTITION P3 VALUES LESS THAN(300) ); |
Example: Create a List Partitioned Table
1 2 3 4 5 6 7 8 9 10 11 12 | DROP TABLE IF EXISTS data_list; CREATE TABLE data_list( id int, time int, salary decimal(12,2) )PARTITION BY LIST (time)( PARTITION P1 VALUES (202209), PARTITION P2 VALUES (202210,202208), PARTITION P3 VALUES (202211), PARTITION P4 VALUES (202212), PARTITION P5 VALUES (202301) ); |
Example: Use MODIFY PARTITION to Set Whether a Partitioned Index Is Usable
Create the local index student_grade_index for the partitioned table customer_address and set partition index names.
1 2 3 4 5 6 | CREATE INDEX customer_address_index ON customer_address(ca_address_id) LOCAL ( PARTITION P1_index, PARTITION P2_index, PARTITION P3_index ); |
Rebuild all indexes on partition P1 in the partitioned table customer_address.
1 | ALTER TABLE customer_address MODIFY PARTITION P1 REBUILD UNUSABLE LOCAL INDEXES; |
Set all indexes in partition P3 of the partitioned table customer_address to be unusable.
1 | ALTER TABLE customer_address MODIFY PARTITION P3 UNUSABLE LOCAL INDEXES; |
Example: Use REBUILD PARTITION to Rebuild a Partitioned Index into Which Data Has Been Inserted
- Creates a partitioned table.
1 2 3 4 5 6 7 8 9 10 11
DROP TABLE IF EXISTS sales; CREATE TABLE sales ( id INT, sale_date DATE, amount DECIMAL(10,2) ) PARTITION BY RANGE (sale_date) ( PARTITION p202310 VALUES LESS THAN ('2023-11-01'), PARTITION p202311 VALUES LESS THAN ('2023-12-01') );
- Create an index.
1CREATE INDEX idx_sale_date ON sales (sale_date) LOCAL;
- Insert partition data of October and November.
1 2 3 4 5 6 7
INSERT INTO sales PARTITION (p202310) VALUES (1, '2023-10-05', 100.50), (2, '2023-10-10', 200.75); INSERT INTO sales PARTITION (p202311) VALUES (3, '2023-11-15', 300.00);
- Rebuild indexes of the specific partition p202310.
1ALTER TABLE sales REBUILD PARTITION p202310 WITHOUT UNUSABLE;
Example: Use ADD PARTITION to Add One or More Partitions to a Specified Partitioned Table
Add a partition to the range partitioned table customer_address.
1 | ALTER TABLE customer_address ADD PARTITION P5 VALUES LESS THAN (500); |
Add the following partitions to the range partitioned table customer_address: [500, 600), [600, 700).
1 | ALTER TABLE customer_address ADD PARTITION p6 START(500) END(700) EVERY(100); |
Add the MAXVALUE partition p7 to the range partitioned table customer_address.
1 | ALTER TABLE customer_address ADD PARTITION p7 END(MAXVALUE); |
Add partition P6 to a list partitioned table.
1 | ALTER TABLE data_list ADD PARTITION P6 VALUES (202302,202303); |
Example: Use SPLIT PARTITION to Split a Partition into Multiple Partitions
Split partition P7 in the range partitioned table customer_address at 800.
1 | ALTER TABLE customer_address SPLIT PARTITION P7 AT(800) INTO (PARTITION P6a,PARTITION P6b); |
Split the partition at 400 in the range partitioned table customer_address into multiple partitions.
1 | ALTER TABLE customer_address SPLIT PARTITION FOR(400) INTO(PARTITION p_part START(300) END(500) EVERY(100)); |
Split partition P2 in the list partitioned table data_list into two partitions: p2a and p2b.
1 | ALTER TABLE data_list SPLIT PARTITION P2 VALUES(202210) INTO (PARTITION p2a,PARTITION p2b); |
Example: Use EXCHANGE PARTITION to Migrate Data from a Common Table to a Specified Partition
The following example demonstrates how to migrate data from table math_grade to partition math in partitioned table student_grade.
- Create the partitioned table student_grade.
1 2 3 4 5 6 7 8 9 10 11 12 13 14
DROP TABLE IF EXISTS student_grade; CREATE TABLE student_grade ( stu_name char(5), stu_no integer, grade integer, subject varchar(30) ) PARTITION BY LIST(subject) ( PARTITION gym VALUES('gymnastics'), PARTITION phys VALUES('physics'), PARTITION history VALUES('history'), PARTITION math VALUES('math') );
- Add data to the partitioned table student_grade.
1 2 3 4 5 6 7
INSERT INTO student_grade VALUES ('Ann', 20220101, 75, 'gymnastics'), ('Jack', 20220103, 60, 'math'), ('Anna', 20220108, 56, 'history'), ('John', 20220107, 82, 'physics'), ('Molly', 20220104, 91, 'physics'), ('Sam', 20220105, 72, 'math');
- Query the records of partition math in student_grade.
1SELECT * FROM student_grade PARTITION (math);
The query result is as follows:

- Create an ordinary table math_grade that matches the definition of the partitioned table student_grade.
1 2 3 4 5 6 7 8
DROP TABLE IF EXISTS math_grade; CREATE TABLE math_grade ( stu_name char(5), stu_no integer, grade integer, subject varchar(30) );
- Insert data to the math_grade table. The data in the student_grade partitioned table conforms to the partition rule of partition math.
1 2 3 4 5
INSERT INTO math_grade VALUES ('Ann', 20220101, 75, 'math'), ('Jack', 20220103, 60, 'math'), ('Anna', 20220108, 56, 'math'), ('John', 20220107, 82, 'math');
- Migrate data from the ordinary table math_grade to partition math in the partitioned table student_grade.
1ALTER TABLE student_grade EXCHANGE PARTITION (math) WITH TABLE math_grade;
- Query the partitioned table student_grade. The result shows that the data in the table math_grade has been exchanged with the data in partition math of the partitioned table student_grade.
1SELECT * FROM student_grade PARTITION (math);
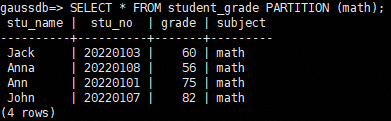
- Query the math_grade table. The result shows that the data stored in the math partition of the student_grade partitioned table has been exchanged with the math_grade table.
1SELECT * FROM math_grade;

Example: Use TRUNCATE PARTITION to Clear Data in a Table Partition
Clear the p1 partition of the customer_address table.
1 | ALTER TABLE customer_address TRUNCATE PARTITION p1; |
Examples: Enabling and Disabling ROW MOVEMENT
If ROW MOVEMENT is enabled, the data of a row is moved to a new partition when the partition key of the row is updated to a new value and the new value belongs to another partition.
If a partition key is frequently updated, enabling ROW MOVEMENT may cause extra I/O overhead. To enable it, evaluate service requirements first.
Create a table partitioned by date and enable ROW MOVEMENT.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | DROP TABLE IF EXISTS sale_data; CREATE TABLE sales_data ( sale_id INT, product_name VARCHAR(100), sale_date DATE, amount DECIMAL(10, 2) ) PARTITION BY RANGE (sale_date) ( PARTITION p_2023q1 VALUES LESS THAN ('2023-04-01'), PARTITION p_2023q2 VALUES LESS THAN ('2023-07-01'), PARTITION p_2023q3 VALUES LESS THAN ('2023-10-01'), PARTITION p_2023q4 VALUES LESS THAN ('2024-01-01') ) ENABLE ROW MOVEMENT; |
Insert test data.
1 2 3 4 | INSERT INTO sales_data (sale_id, product_name, sale_date, amount) VALUES (1, 'Product A', '2023-02-15', 1000.00), -- It belongs to p_2023q1. (2, 'Product B', '2023-05-20', 1500.00); -- It belongs to p_2023q2. |
Query the data distribution of each partition.
1 | SELECT tableoid::regclass AS partition, * FROM sales_data ORDER BY sale_id; |

Update the partition key (which is moved from p_2023q1 to p_2023q2).
1 | UPDATE sales_data SET sale_date = '2023-05-01' WHERE sale_id = 1; |
Query the data distribution of each partition again to confirm that the row has been moved.
1 | SELECT tableoid::regclass AS partition, * FROM sales_data ORDER BY sale_id; |

Disable ROW MOVEMENT.
1 | ALTER TABLE sales_data DISABLE ROW MOVEMENT; |
Modify the partition key again (which is moved from p_2023q2 back to p_2023q2).
1 | UPDATE sales_data SET sale_date = '2023-02-15' WHERE sale_id = 1; |
View the command output. It indicates that ROW MOVEMENT is disabled and the partition key cannot be updated.

Example: Use MERGE PARTITIONS to Merge Multiple Partitions into One
Merge partitions P2 and P3 in the range partitioned table customer_address into one.
1 2 | ALTER TABLE customer_address MODIFY PARTITION P3 REBUILD UNUSABLE LOCAL INDEXES; -- The example above sets the P3 index to be unusable. Execute this statement first to rebuild the index before performing MERGE. Otherwise, the following example will report an error. ALTER TABLE customer_address MERGE PARTITIONS P2, P3 INTO PARTITION P_M; |
Example: Use DROP PARTITION to Delete a Specified Partition from a Partitioned Table
Delete partitions P6a and P6b from partitioned table customer_address.
1 | ALTER TABLE customer_address DROP PARTITION P6a, P6b; |
Helpful Links
FAQs
- Practice: Creating and Managing DWS Partitioned Tables
- Practice: Case: Reconstructing Partitioned Tables
- "inserted partition key does not map to any table partition" Is Reported When Data Is Inserted into a Partitioned Table
- Error upper boundary of adding partition MUST overtop last existing partition Is Reported When a New Partition Is Added to a Range Partitioned Table
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



