
What Is DWS?
DWS is an online data analysis and processing database built on the Huawei Cloud infrastructure and platform. It offers scalable, ready-to-use, and fully managed analytical database services, and is compatible with ANSI/ISO SQL-92, SQL-99, and SQL:2003 syntax. Additionally, DWS is interoperable with other database ecosystems such as PostgreSQL, Oracle, Teradata, and MySQL. This makes it a competitive option for petabyte-scale big data analytics across diverse industries.
Logical Cluster Architecture
Figure 1 shows the logical architecture of a DWS cluster. For details about the instance, see Table 1.

|
Name |
Function |
Description |
|---|---|---|
|
Cluster Manager (CM) |
Cluster Manager. It manages and monitors the running status of functional units and physical resources in the distributed system, ensuring system stability. |
The CM consists of CM Agent, OM Monitor, and CM Server.
CM Servers are deployed in primary/standby pairs to ensure system high availability. CM Agent connects to the primary CM Server. If the primary CM Server is faulty, the standby CM Server is promoted to primary to prevent a single point of failure (SPOF). |
|
Global Transaction Manager (GTM) |
Generates and maintains the globally unique information, such as the transaction ID, transaction snapshot, and timestamp. |
The cluster includes only one pair of GTMs: one primary GTM and one standby GTM. |
|
Workload Manager (WLM) |
Workload Manager. It controls allocation of system resources to prevent service congestion and system crash resulting from excessive workload. |
You do not need to specify names of hosts where WLMs are to be deployed, because the installation program automatically installs a WLM on each host. |
|
Coordinator (CN) |
A CN receives access requests from applications, and returns execution results to the client; splits tasks and allocates task fragments to different DNs for parallel processing. |
CNs in a cluster have equivalent roles and return the same result for the same DML statement. Load balancers can be added between CNs and applications to ensure that CNs are transparent to applications. If a CN is faulty, the load balancer automatically connects the application to the other CN. For details, see section "Associating and Disassociating ELB". CNs need to connect to each other in the distributed transaction architecture. To reduce heavy load caused by excessive threads on GTMs, no more than 10 CNs should be configured in a cluster. DWS handles the global resource load in a cluster using the Central Coordinator (CCN) for adaptive dynamic load management. When the cluster is started for the first time, the CM selects the CN with the smallest ID as the CCN. If the CCN is faulty, CM replaces it with a new one. |
|
Datanode (DN) |
A DN stores data in row-store, column-store, or hybrid mode, executes data query tasks, and returns execution results to CNs. |
There are multiple DNs in the cluster. Each DN stores part of data. DWS provides DN high availability: active DN, standby DN, and secondary DN. The working principles of the three are as follows:
The secondary DN serves exclusively as a backup, never ascending to active or standby status in case of faults. It conserves storage by only holding Xlog data transferred from the new active DN and data replicated during original active DN failures. This efficient approach saves one-third of the storage space compared to conventional tri-backup methods. |
|
Storage |
Functions as the server's local storage resources to store data permanently. |
- |
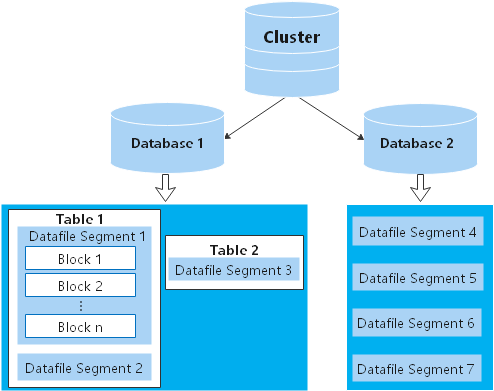
DNs in a cluster store data on disks. Figure 2 describes the objects on each DN and the relationships among them logically.
- A database manages various data objects and is isolated from other databases.
- A datafile segment stores data in only one table. A table containing more than 1 GB of data is stored in multiple data file segments.
- A table belongs only to one database.
- A block is the basic unit of database management, with a default size of 8 KB.
Data can be distributed in replication, round-robin, or hash mode. You can specify the distribution mode during table creation.
Storage-Compute Coupled Architecture
DWS employs the shared-nothing architecture and the massively parallel processing (MPP) engine, and consists of numerous independent logical nodes that do not share the system resources such as CPUs, memory, and storage. In such a system architecture, service data is separately stored on numerous nodes. Data analysis tasks are executed in parallel on the nodes where data is stored. The massively parallel data processing significantly improves response speed.

- Application layer
Data loading tools, Extract-Transform-Load (ETL) tools, Business Intelligence (BI) tools, and data mining and analysis tools can be integrated with DWS through standard interfaces. DWS is compatible with the PostgreSQL ecosystem, and the SQL syntax is compatible with Oracle and Teradata. Applications can be smoothly migrated to DWS with only a few changes.
- API
Applications can connect to DWS through standard JDBC and ODBC.
- DWS
A data warehouse cluster contains nodes with the same flavor in the same subnet. These nodes jointly provide services. Datanodes (DNs) in a cluster store data on disks. CNs, or Coordinators, receive access requests from the clients and return the execution results. They also split and distribute tasks to the Datanodes (DNs) for parallel execution.
- Automatic data backup
Cluster snapshots can be automatically backed up to the EB-level Object Storage Service (OBS), which facilitates periodic backup of the cluster during off-peak hours, ensuring data recovery after a cluster exception occurs.
A snapshot is a complete backup of DWS at a specified time point. It records all configuration data and service data of the cluster at the specified moment.
- Tool chain
The parallel data loading tool General Data Service (GDS), SQL syntax migration tool Database Schema Convertor (DSC), and SQL development tool Data Studio are provided. The cluster O&M can be monitored on a console.
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



