
Help Center/ Cloud Adoption Framework/ Cloud Adoption Framework and Practices/ Adoption Implementation/ Big Data Migration/ Switchover
Updated on 2025-05-07 GMT+08:00
Switchover
Big data switchover refers to the transition of big data applications from a source environment to a target environment. Detailed information regarding switchover drills and formal switchover procedures can be found in Cutover. This section outlines three key switchover approaches for big data applications to provide comprehensive guidance during the transition process.
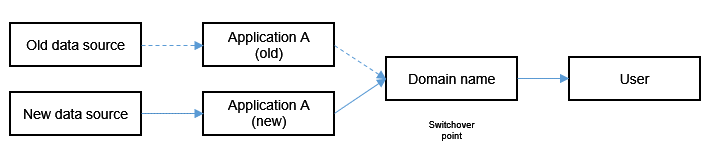
- Parallel running scenario: In a parallel running scenario, the big data application is deployed and actively running in both the source and target environments simultaneously. The switchover point in this approach is the domain name. During the service switchover, the transition is executed by simply redirecting the domain name resolution to point to the new application instance in the target environment, thereby shifting service traffic. Figure 1 Parallel running scenario
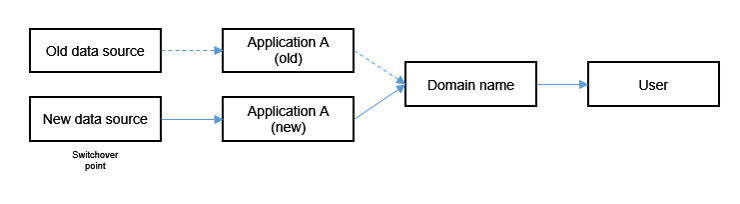
- Data push scenario: This scenario is applicable when the data source actively pushes data to the big data application. The switchover point here is the data source itself. The switchover process involves halting the data push from the original data source, configuring and initiating the data push from the new data source, and updating the application's data source configuration to point from the old data source to the new one. Figure 2 Data push scenario
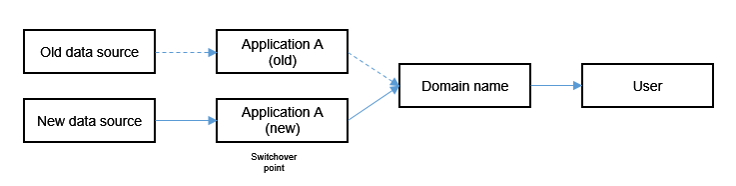
- Data extraction scenario: This scenario applies when the big data application actively extracts data from a designated data source. The switchover point is the application itself. The switchover procedure entails stopping the application's data extraction from the original data source, configuring and starting the application to extract data from the new data source, and reconfiguring the application's data source connection to point from the old data source to the new one. Figure 3 Data extraction scenario
Parent topic: Big Data Migration
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
The system is busy. Please try again later.
For any further questions, feel free to contact us through the chatbot.
Chatbot



