
Design
For details about the deployment architecture design for big data platforms on the cloud, see Designing a Big Data Architecture. This section focuses on the design of the data migration solution and task migration solution.
Data Migration Solution Design
Big data migration encompasses three data types, as detailed in the table below.
| Category | Description |
|---|---|
| Metadata | Hive metadata or external metadata |
| Inventory data | Historical data that does not change in a short period of time |
| Incremental data | Data that is updated periodically. |
The migration methods of the three types of data are as follows:
| Data Categorization | Migration Method | |
|---|---|---|
| Metadata | Hive metadata | Export the Hive metadata from the source end and import it to Huawei Cloud MRS-Hive. |
| External metadata MySQL | Use Huawei Cloud DRS to synchronize metadata from MySQL to RDS on the cloud. | |
| Inventory data | Hive historical data is stored in HDFS. | Use Huawei Cloud CDM to migrate all historical data to Huawei Cloud MRS or Huawei Cloud OBS (decoupled storage and compute scenario). |
| HBase historical data |
| |
| Incremental data | Hive incremental data | Query the daily changed data based on the source metadata, identify the data directories to be migrated, and use Huawei Cloud CDM to migrate incremental data to the cloud. |
| HBase incremental data | Use Huawei Cloud CDM to migrate all incremental data (based on timestamps) to Huawei Cloud MRS. | |
Enterprises can select the most suitable migration solution based on the specific data types involved. CDM serves as the primary tool during the data migration phase. Big data migration is usually performed in the following sequence:

- Metadata migration
Metadata migration is the initial phase. Metadata provides descriptive information about the data, such data structures, data definitions, and data relationships. This process involves exporting the source metadata and subsequently recreating or importing it into the target system. Successful metadata migration is crucial for ensuring the target system can accurately interpret and process the migrated data.
- Historical data migration
Following the completion of metadata migration, the historical data migration phase involves transferring data accumulated over a specific past timeframe. This historical data is migrated to the target system to facilitate subsequent analysis and processing. The process typically includes exporting data from the original storage and loading it into the target system according to predefined rules and formats.
- Incremental data migration
Upon completion of historical data migration, the incremental data migration phase addresses the transfer of new data generated since the historical migration. This incremental data requires timely and accurate migration to the target system, often performed in near real-time or at scheduled intervals. Common techniques for incremental data migration include data synchronization and continuous data transmission, ensuring the target system has access to the latest information.
Data Verification Standard Design
During big data migration, achieving 100% data consistency across all data types may not always be a strict requirement. Instead, data consistency needs should be determined based on specific service requirements and the importance of the data. Consequently, appropriate data migration policies and technical measures must be implemented to guarantee data correctness and integrity according to these defined requirements.
- Verification standards based on data type: For transactional data, such as banking transaction records, stringent data consistency during migration is paramount. Post-migration, the source and target data must exhibit an exact match to prevent operational issues arising from data discrepancies. For data that is not transactional in nature, minor discrepancies after migration may be acceptable.
- Verification standards based on data importance: Data crucial to core business operations demands high data consistency during migration. This data often contains sensitive or critical information, necessitating the utmost accuracy and integrity throughout the migration process. For data that does not directly impact core services, a greater tolerance for minor data differences post-migration may be permissible.
Therefore, prior to initiating data migration, organizations must establish clear and specific verification standards for each data type and based on its importance to the business. The following template can be used as a reference:
| Data Type | Verification Standard | Table Name |
|---|---|---|
| Class X data | 100% consistency | Table A, Table B, Table C,... |
| Class Y data | Error < 0.01% | Table D, Table E, Table F,... |
| ... | Customized standard | ... |
Task Migration Solution Design
Big data tasks are classified into three types: JAR tasks, SQL tasks, and script tasks (Python and Shell). You can select a proper migration solution based on the task type.
| Task Type | Migration Solution |
|---|---|
| JAR tasks |
|
| SQL tasks |
|
| Script tasks (Python, Shell) |
|
Big data task migration is usually performed in the following sequence:

- Migrate all historical tasks.
Initiate the migration of all historical tasks by transferring both the associated data and code to the new big data platform. This involves exporting data from the legacy storage system and subsequently loading it into the new storage system. Furthermore, the original task scripts and their corresponding configuration files must be adapted and migrated to ensure compatibility with the new computing environment.
- Debug tasks.
Upon completion of the full historical task migration, a commissioning and verification phase is crucial. This includes executing the migrated jobs, meticulously checking the output results against expected outcomes, and rigorously verifying performance and stability during task execution. Any identified issues or exceptions necessitate appropriate adjustments and remediation.
- Periodically synchronize incremental tasks.
Following the successful migration and commissioning of historical tasks, the migration and synchronization of incremental tasks will commence. Incremental tasks represent new workloads that require periodic execution during the ongoing migration process.
- Run tasks in parallel.
After incremental jobs have been migrated and synchronized, a parallel execution phase is initiated across both the original and new platforms. This involves simultaneously running jobs from both the legacy and the new big data systems on the new platform. The purpose of this parallel run is to verify the consistency of results between the two systems. This verification process entails comparing job outputs, logs, and key performance indicators to definitively determine the alignment of the new system's results with those of the original system.
- Switchover the applications.
Once the parallel execution phase demonstrates stable and consistent performance over a defined period, the migration of big data applications and the complete cutover of all services to the new big data platform can be performed.
- Design a big data parallel running solution. Implementing a parallel running solution is a prevalent and effective big data migration strategy. This approach involves operating both the legacy and the new platforms concurrently to facilitate continuous data and task verification. After a period of stable parallel operation, all services are transitioned to the new big data platform, as illustrated in the following figure.Figure 3 Big data parallel running solution
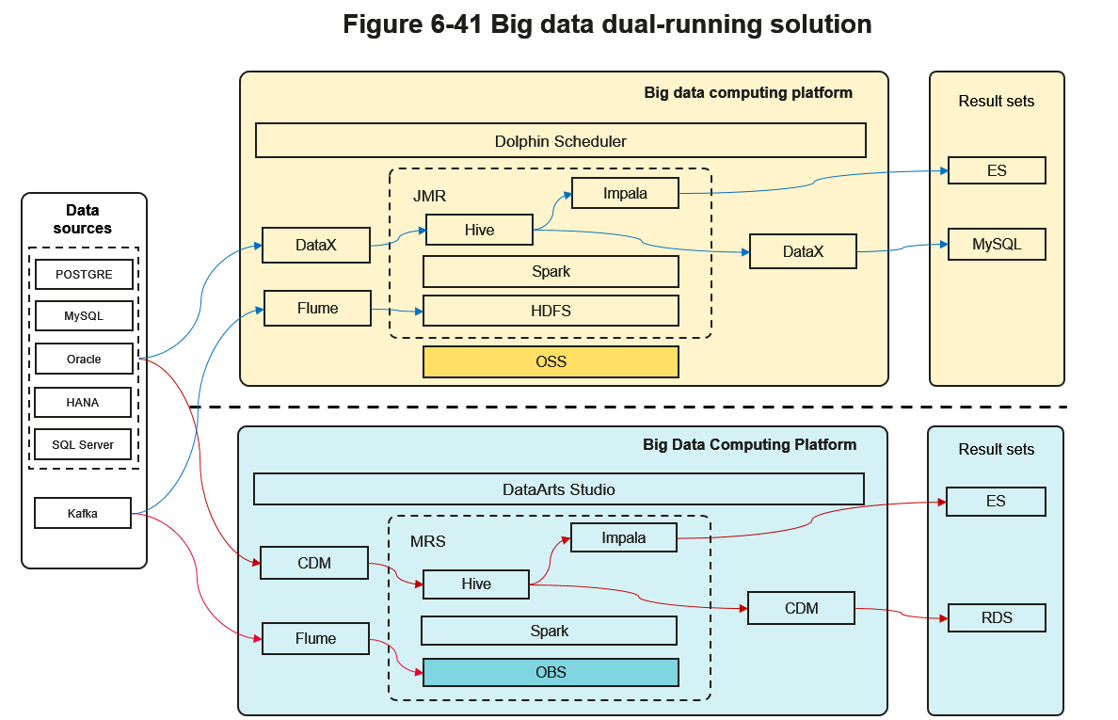
The design ideas of the parallel running solution are as follows:
- Data and task migration
Prior to establishing data source connectivity, perform a comprehensive migration of data and tasks. This includes migrating historical data from the original platform to the new big data platform, as well as transferring all associated task code, scripts, and configuration files. The selection of appropriate migration tools and methodologies should be based on specific project requirements, potentially leveraging offline data transmission utilities and dedicated big data migration tools such as CDM.
- Data source access
Establish connectivity between the target big data cluster and the same underlying data sources utilized by the original big data cluster. This ensures data source consistency between the two environments. Employ data synchronization tools, ETL (Extract, Transform, Load) tools, or custom-developed scripts to facilitate data source connection and synchronization. For offline computing tasks, data sources can be accessed via data synchronization tools like CDM, ETL tools, or custom scripts. For real-time computing tasks, consider utilizing Kafka MirrorMaker and Nginx traffic mirroring configurations to replicate real-time data streams to both platforms concurrently.
- Parallel running
Initiate the simultaneous operation of both the target and original big data clusters and their respective task scheduling platforms. During this parallel running phase, both platforms will process workloads concurrently, generating independent sets of results.
- Running stability verification
Throughout the parallel running period, continuous monitoring and verification of task execution stability and data consistency on the target big data platform are essential. This includes actively tracking task execution status and meticulously comparing task logs and output results. Any identified issues or anomalies must be addressed and rectified promptly to ensure the reliability of the new platform.
- Official service switchover
Upon thorough confirmation of the target big data cluster and task scheduling platform's stability, coupled with the verified integrity and accuracy of the migrated data and tasks, proceed with the official service switchover. This entails redirecting all service traffic and job execution to the target big data platform and decommissioning the original big data cluster and task scheduling platform.
- Data and task migration
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



