
Conceptos básicos
CCE proporciona clústeres Kubernetes con gran capacidad de escalamiento, de alto rendimiento y de clase empresarial; además es compatible con contenedores Docker. Con CCE, puede implementar, gestionar y escalar fácilmente aplicaciones en contenedores en la nube.
La consola de gráfica de CCE permite las experiencias de usuario E2E. Además, CCE es compatible con las API nativas de Kubernetes y kubectl. Antes de usar CCE, se recomienda que comprenda los conceptos básicos relacionados.
Clúster
Un clúster es un grupo de uno o más servidores en la nube (también conocidos como nodos) en la misma subred. Tiene todos los recursos en la nube (incluyendo VPC y recursos informáticos) necesarios para ejecutar contenedores.
Nodo
Un nodo es un servidor en la nube (máquina virtual o física) que ejecuta una instancia de Docker Engine. Los contenedores se implementan, ejecutan y administran en nodos. El agente de nodo (kubelet) se ejecuta en cada nodo para gestionar instancias de contenedor en el nodo. Se puede escalar el número de nodos de un clúster.
Grupo de nodos
Un grupo de nodos contiene un nodo o un grupo de nodos con una configuración idéntica en un clúster.
Virtual Private Cloud (VPC)
Una VPC es una red virtual aislada lógicamente que facilita la gestión y la configuración de redes internas de forma segura. Los recursos de la misma VPC pueden comunicarse entre sí, pero aquellos de diferentes VPC no pueden comunicarse entre sí de forma predeterminada. Las VPC proporcionan las mismas funciones de red que las redes físicas y también servicios de red avanzados, como direcciones IP elásticas y grupos de seguridad.
Grupo de seguridad
Un grupo de seguridad es un conjunto de reglas de control de acceso para los ECS que tengan los mismos requisitos de protección de seguridad y que sean de confianza recíproca en una VPC. Después de crear un grupo de seguridad, se pueden crear diferentes reglas de acceso para que el grupo de seguridad proteja los ECS que se agreguen a este grupo de seguridad.
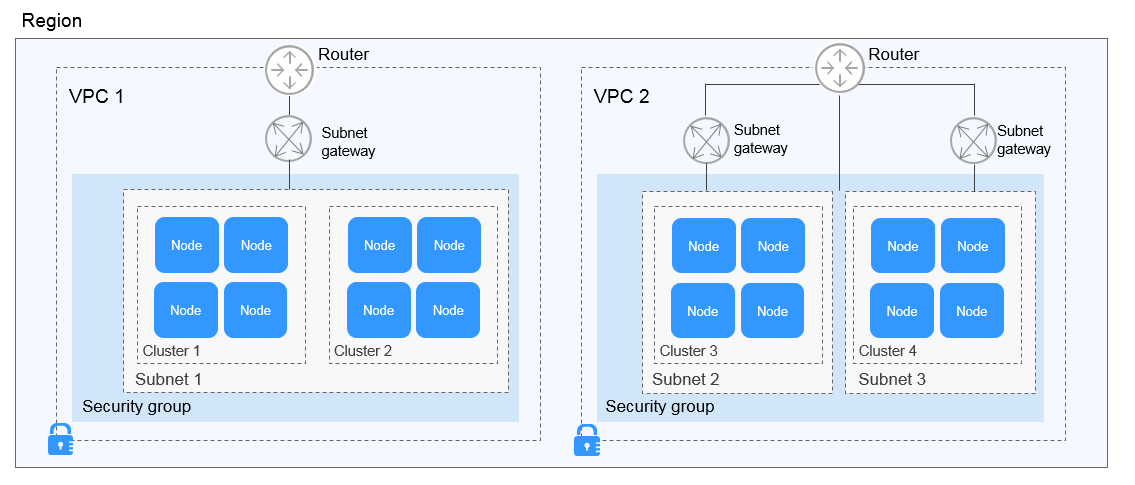
Relación entre clústeres, VPC, grupos de seguridad y nodos
- Se crean los diferentes clústeres en las diferentes VPC.
- Se crean los diferentes clústeres en la misma subred.
- Se crean los diferentes clústeres en las diferentes subredes.
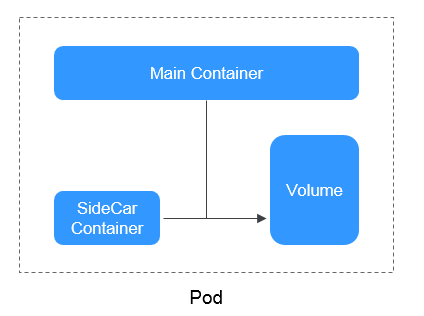
Pod
Un pod es la unidad más pequeña y sencilla del modelo de objetos de Kubernetes que cree o implemente. Un pod encapsula un contenedor de aplicación (o, en algunos casos, varios contenedores), recursos de almacenamiento, una dirección IP de red única y opciones que rigen la ejecución de los contenedores.
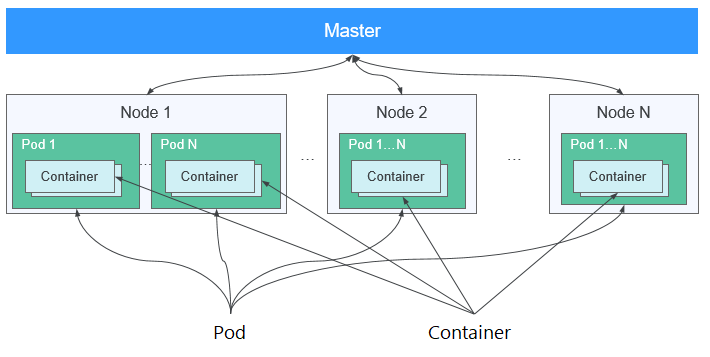
Contenedor
Un contenedor es una instancia en ejecución de una imagen Docker. Se pueden ejecutar varios contenedores en un nodo. Los contenedores son en realidad procesos de software. A diferencia de los procesos de software tradicionales, los contenedores tienen un espacio de nombres separado y no se ejecutan directamente en un host.
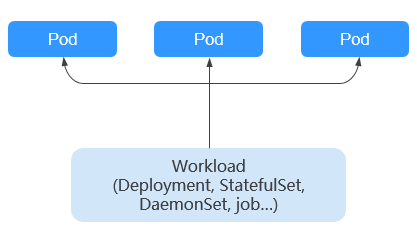
Carga de trabajo
Una carga de trabajo es una aplicación que se ejecuta en Kubernetes. No importa cuántos componentes haya en su carga de trabajo, puede ejecutarlo en un grupo de pods de Kubernetes. Una carga de trabajo es un modelo abstracto de un grupo de pods en Kubernetes. Las cargas de trabajo clasificadas en Kubernetes incluyen Deployments, StatefulSets, DaemonSets, trabajos y trabajos cron.
- Deployment: Los pods son completamente independientes entre sí y funcionalmente idénticos. Cuentan con ajuste automático y actualización de balanceo. Los ejemplos típicos incluyen Nginx y WordPress.
- StatefulSet: Los pods no son completamente independientes entre sí. Tienen un almacenamiento estable y persistente y cuentan con una implementación y eliminación ordenadas. Ejemplos típicos incluyen MySQL-HA y etcd.
- DaemonSet: Un DaemonSet asegura que todos o algunos nodos ejecuten un pod. Es aplicable a los pods que se ejecutan en cada nodo. Los ejemplos típicos incluyen Ceph, Fluentd y Prometheus Node Exporter.
- Job: es una tarea de una sola vez que se ejecuta hasta su finalización. Se puede ejecutar inmediatamente después de ser creado. Antes de crear una carga de trabajo, puede ejecutar un trabajo para cargar una imagen en el repositorio de imágenes.
- Cron job: Ejecuta un trabajo periódicamente en un horario determinado. Puede realizar la sincronización de tiempo para todos los nodos activos en un punto de tiempo fijo.
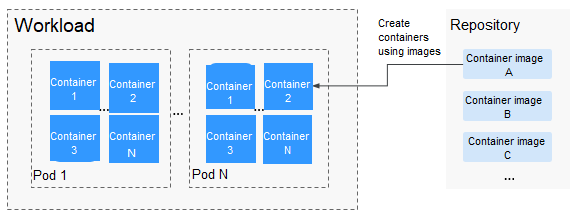
Imagen
Docker crea un estándar de la industria para aplicaciones de envasado en contenedores. Las imágenes de Docker son como plantillas que incluyen todo lo necesario para ejecutar contenedores y se utilizan para crear contenedores de Docker. En otras palabras, la imagen de Docker es un sistema de archivos especial que incluye todo lo necesario para ejecutar contenedores: programas, bibliotecas, recursos y archivos de configuración. También contiene parámetros de configuración (como volúmenes anónimos, variables de entorno y usuarios) requeridos dentro del tiempo de ejecución de un contenedor. Una imagen no contiene ningún dato dinámico. Su contenido permanece sin cambios después de ser construido. Al implementar aplicaciones en contenedores, puede usar imágenes de Docker Hub, SoftWare Repository for Container (SWR) y sus registros de imágenes privados. Por ejemplo, una imagen de Docker puede contener un sistema operativo Ubuntu completo, en el que solo se instalan los programas y dependencias necesarios.
Las imágenes se convierten en contenedores en tiempo de ejecución, es decir, los contenedores se crean a partir de imágenes. Los contenedores pueden crearse, iniciarse, detenerse, eliminarse y suspenderse.
Espacio de nombres
Un espacio de nombres es una colección abstracta de recursos y objetos. Permite que los recursos se organicen en grupos que no se superpongan. Se pueden crear varios espacios de nombres dentro de un clúster y aislarlos unos de otros. Esto permite que los espacios de nombres compartan los mismos servicios de clúster sin afectarse entre sí. Ejemplos:
- Puede implementar cargas de trabajo en un entorno de desarrollo en un espacio de nombres e implementar cargas de trabajo en un entorno de prueba en otro espacio de nombres.
- Pods, servicios, ReplicationControllers e implementaciones pertenecen a un espacio de nombres (se llama default de forma predeterminada), mientras que los nodos y PersistentVolumes no pertenecen a ningún espacio de nombres.
Servicio
Un servicio es un método abstracto que expone un grupo de aplicaciones que se ejecutan en un pod como servicios de red.
Kubernetes le proporciona un mecanismo de detección de servicios sin modificar las aplicaciones. En este mecanismo, Kubernetes proporciona a los pods sus propias direcciones IP y un único DNS para un grupo de pods, y equilibra la carga entre ellos.
Kubernetes le permite especificar un servicio de un tipo requerido. Los valores y acciones de los diferentes tipos de Servicios son los siguientes:
- ClusterIP: el servicio ClusterIP, como tipo de servicio predeterminado, se expone a través de la dirección IP interna del clúster. Si se selecciona este modo, solo se puede acceder a Servicios dentro del clúster.
- NodePort: Los servicios de NodePort están expuestos a través de la dirección IP y el puerto estático de cada nodo. Se crea automáticamente un servicio de ClusterIP, al que se enrutará un servicio de NodePort. Al enviar una solicitud a <NodeIP>:<NodePort>, puede acceder a un servicio de NodePort desde fuera de un clúster.
- LoadBalancer (ELB): LoadBalancer (ELB) Services se exponen mediante el uso de balanceadores de carga del proveedor de nube. Los balanceadores de carga externos pueden enrutar a los servicios de NodePort y ClusterIP.
- DNAT: Un gateway de DNAT traduce direcciones para nodos de clúster y permite que varios nodos de clúster compartan un EIP. Los servicios de DNAT proporcionan una mayor fiabilidad que los servicios de NodePort basados en EIP, en los que el EIP está unido a un solo nodo y una vez que el nodo está inactivo, todas las solicitudes entrantes a la carga de trabajo se distribuirán.
Equilibrio de carga de capa 7 (entrada)
Un ingreso es un conjunto de reglas de enrutamiento para las solicitudes que ingresan a un clúster. Proporciona servicios con direcciones URL, equilibrio de carga, terminación SSL y enrutamiento HTTP para el acceso externo al clúster.
Política de red
Las políticas de red proporcionan un control de red basado en políticas para aislar las aplicaciones y reducir la superficie de ataque. Una política de red utiliza selectores de etiquetas para simular redes segmentadas tradicionales y controla el tráfico entre ellas y el tráfico desde el exterior.
ConfigMap
Un ConfigMap se utiliza para almacenar datos de configuración o archivos de configuración como pares clave-valor. Las ConfigMaps son similares a los secretos, pero proporcionan un medio para trabajar con cadenas que no contienen información confidencial.
Secreto
Los secretos resuelven el problema de configuración de datos confidenciales como contraseñas, tokens y claves, y no expondrán los datos confidenciales en imágenes o especificaciones de pod. Un secreto se puede usar como un volumen o una variable de entorno.
Etiqueta
Una etiqueta es un par clave-valor y está asociado con un objeto, por ejemplo, un pod. Las etiquetas se utilizan para identificar características especiales de los objetos y son significativas para los usuarios. Sin embargo, las etiquetas no tienen un significado directo para el sistema del núcleo.
Selector de etiquetas
El selector de etiquetas es el mecanismo de agrupación principal de Kubernetes. Identifica un grupo de objetos de recurso con las mismas características o atributos a través del selector de etiquetas cliente o usuario.
Anotación
Las anotaciones se definen en pares clave-valor como lo son las etiquetas.
Las etiquetas tienen reglas de nomenclatura estrictas. Definen los metadatos de los objetos de Kubernetes y los utilizan los selectores de etiquetas.
Las anotaciones son información adicional definida por el usuario para que las herramientas externas busquen un objeto de recurso.
PersistentVolume
Un PersistentVolume (PV) es un almacenamiento de red en un clúster. Similar a un nodo, también es un recurso de clúster.
PersistentVolumeClaim
Un PV es un recurso de almacenamiento, y un PersistentVolumeClaim (PVC) es una solicitud de un PV. El PVC es similar al pod. Los pods consumen recursos de nodo y los PVC consumen recursos PV. Los pods solicitan recursos de CPU y memoria, y los PVC solicitan volúmenes de datos de un tamaño y modo de acceso específicos.
Auto Scaling - HPA
Horizontal Pod Autoscaling (HPA) es una función que implementa el ajuste horizontal de pods en Kubernetes. El mecanismo de ajuste de ReplicationController se puede utilizar para escalar sus clústeres de Kubernetes.
Afinidad y antiafinidad
Si una aplicación no está en contenedores, varios componentes de la aplicación pueden ejecutarse en la misma máquina virtual y los procesos se comunican entre sí. Sin embargo, en el caso de la contenedorización, los procesos de software se empaquetan en diferentes contenedores y cada contenedor tiene su propio ciclo de vida. Por ejemplo, el proceso de transacción se empaqueta en un contenedor mientras que el proceso de monitorización/registro y el proceso de almacenamiento local se empaquetan en otros contenedores. Si los procesos de contenedores estrechamente relacionados se ejecutan en nodos distantes, el enrutamiento entre ellos será costoso y lento.
- Afinidad: los contenedores se programan en el nodo más cercano. Por ejemplo, si la aplicación A y la aplicación B interactúan frecuentemente entre sí, es necesario usar la característica de afinidad para mantener las dos aplicaciones lo más cerca posible o incluso permitir que se ejecuten en el mismo nodo. De esta manera, no se producirá ninguna pérdida de rendimiento debido al enrutamiento lento.
- Antiafinidad: las instancias de la misma aplicación se extienden a través de diferentes nodos para lograr una mayor disponibilidad. Una vez que un nodo está inactivo, las instancias de otros nodos no se ven afectadas. Por ejemplo, si una aplicación tiene varias réplicas, es necesario utilizar la función antiafinidad para desplegar las réplicas en diferentes nodos. De esta manera, no se producirá un único punto de fallo.
Afinidad del nodo
Al seleccionar etiquetas, puede programar pods para nodos específicos.
Antiafinidad de nodos
Al seleccionar etiquetas, puede evitar que los pods se programen en nodos específicos.
Afinidad de pod
Puede implementar pods en el mismo nodo para reducir el consumo de recursos de red.
Antiafinidad de pod
Puede implementar pods en diferentes nodos para reducir el impacto de las averías del sistema. También se recomienda la implementación antiafinidad para cargas de trabajo que pueden interferir entre sí.
Cuota de recursos
Las cuotas de recursos se utilizan para limitar el uso de recursos de los usuarios.
Límite de recursos (LimitRange)
De forma predeterminada, todos los contenedores de Kubernetes no tienen límite de CPU ni de memoria. LimitRange (limits para abreviar) se utiliza para agregar un límite de recursos a un espacio de nombres, incluidas las cantidades mínimas, máximas y predeterminadas de recursos. Cuando se crea un pod, los recursos se asignan de acuerdo con los parámetros limits.
Variable de entorno
Una variable de entorno es una variable cuyo valor puede afectar a la forma en que se comportará un contenedor en ejecución. Se puede definir un máximo de 30 variables de entorno en el momento de la creación del contenedor. Puede modificar las variables de entorno incluso después de implementar las cargas de trabajo, lo que aumenta la flexibilidad en la configuración de la carga de trabajo.
La función de establecer variables de entorno en CCE es la misma que la de especificar ENV en un Dockerfile.




