
Help Center>
GaussDB>
User Guide>
Performance Tuning>
Optimization Cases>
Case: Selecting an Appropriate Distribution Key
Updated on 2024-01-26 GMT+08:00
Case: Selecting an Appropriate Distribution Key
Symptom
Tables are defined as follows:
1 2 |
CREATE TABLE t1 (a int, b int); CREATE TABLE t2 (a int, b int); |
The following query is executed:
1
|
SELECT * FROM t1, t2 WHERE t1.a = t2.b; |
Optimization Analysis
If a is the distribution key of t1 and t2:
1 2 |
CREATE TABLE t1 (a int, b int) DISTRIBUTE BY HASH (a); CREATE TABLE t2 (a int, b int) DISTRIBUTE BY HASH (a); |
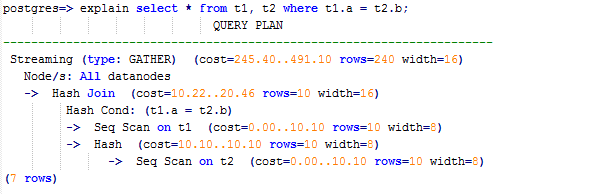
Then Streaming exists in the execution plan and the data volume is heavy among DNs, as shown in Figure 1.

If a is the distribution key of t1 and b is the distribution key of t2:
1 2 |
CREATE TABLE t1 (a int, b int) DISTRIBUTE BY HASH (a); CREATE TABLE t2 (a int, b int) DISTRIBUTE BY HASH (b); |
Then Streaming does not exist in the execution plan, and the data volume among DNs is decreasing and the query performance is increasing, as shown in Figure 2.
Parent topic: Optimization Cases
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
The system is busy. Please try again later.
For any further questions, feel free to contact us through the chatbot.
Chatbot






