
Selecting a Distribution Table
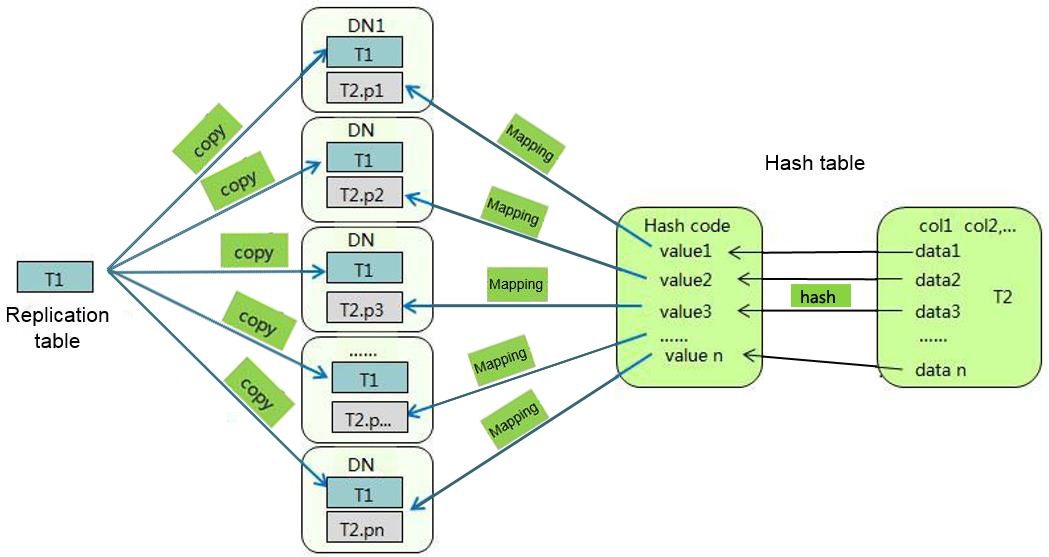
In a replication table, full data is stored on each DN in an instance. It is suitable for the tables containing a small volume of data. Full data in a table is stored on each DN to avoid data redistribution during the join operation. This reduces network costs and plan segments (each having a thread), but generates much redundant data. Generally, small dimension tables are defined as replication tables.
In a hash table, hash values are generated for one or more columns. You can obtain the storage location of a tuple based on the mapping between DNs and the hash values. In a hash table, I/O resources on each node can be used during data read/write, which improves the read/write speed of a table. Generally, tables containing a large amount data are defined as hash tables.
Range distribution and list distribution are user-defined distribution policies. Values in a distribution column are within a certain range or fall into a specific value range of the corresponding target DN. The two distribution modes facilitate flexible data management which, however, requires users equipped with certain data abstraction capability.
Policy |
Description |
Scenario |
|---|---|---|
Hash |
Table data is distributed on all DNs in an instance. |
Fact tables containing a large amount of data |
Replication |
Full data in a table is stored on every DN in an instance. |
Small tables and dimension tables |
Range |
Table data is mapped to specified columns based on the range and distributed to the corresponding DNs. |
Users need to customize distribution rules. |
List |
Table data is mapped to specified columns based on specific values and distributed to corresponding DNs. |
Users need to customize distribution rules. |
As shown in Figure 1, T1 is a replication table and T2 is a hash table.
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot






