

更新时间:2024-04-30 GMT+08:00
模型训练
创建自动学习后,将会进行模型的训练,得到预测分析的模型。部署上线步骤将使用预测模型发布在线预测服务。
操作步骤
- 在新版自动学习页面,单击创建成功的项目名称,查看当前工作流的执行情况。
- 在“预测分析”节点中,待节点状态由“运行中”变为“运行成功”,即完成了模型的自动训练。
- 训练完成后,您可以在预测分析节点中单击
 查看训练详情,如“标签列”和“标签列数据类型”、“准确率”、“评估结果”等。
查看训练详情,如“标签列”和“标签列数据类型”、“准确率”、“评估结果”等。该示例为二分类的离散型数值,评估效果参数说明请参见表1。
不同类型标签列数据产生的评估结果说明请参见评估结果说明。
图1 模型评估报告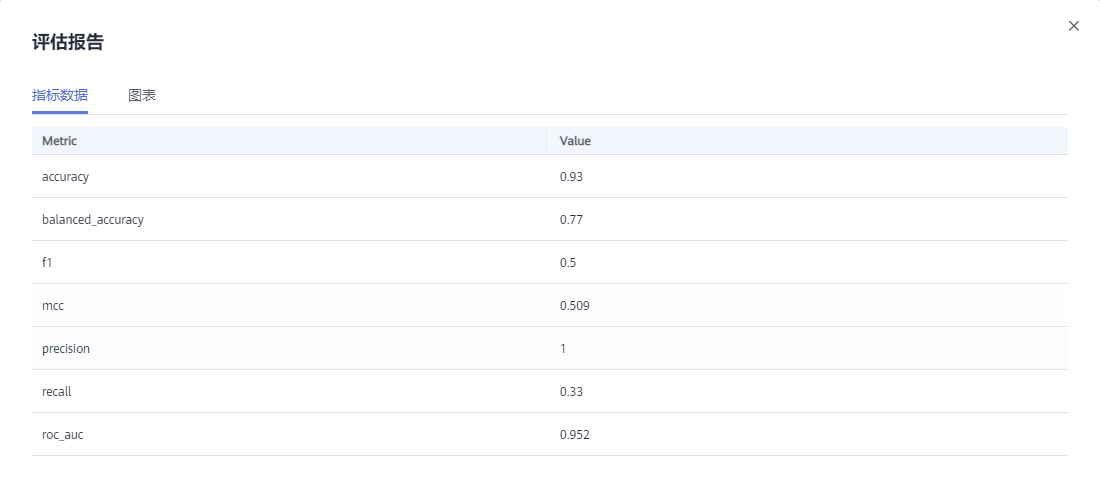

同一个自动学习项目可以训练多次,每次训练会注册一个新的AI应用一个版本。如第一次训练版本号为“0.0.1”,下一个版本为“0.0.2”。基于训练版本可以对训练模型进行管理。当训练的模型达到目标后,再执行部署上线的操作。
父主题: 预测分析








