
Developing a Python Job
This section describes how to develop and execute a Python job using DataArts Factory.
Preparing the Environment
- An ECS named ecs-dgc has been created.
In this example, the ECS uses the CentOS 8.0 64bit with ARM (40 GB) public image and the Python environment. You can log in to the ECS and run the python command to check the Python environment.

- You have enabled the DataArts Migration incremental package and created a CDM cluster named cdm-dlfpyhthon. The cluster provides an agent for the DataArts Factory module to communicate with the ECS.
- Ensure that the ECS can communicate with the CDM cluster, which depends on the following conditions:
- If the CDM cluster and the ECS are in the same region, VPC, subnet, and security group, they can communicate with each other by default. If they are in the same VPC but in different subnets or security groups, you must configure routing rules and security group rules. For details about how to configure routing rules, see Configuring Routing Rules. For details about how to configure security group rules, see Configuring Security Group Rules.
- If the CDM cluster and the ECS are in different regions, a public network or a dedicated connection is required for enabling communication between the CDM cluster and the cloud service. If the Internet is used for communication, ensure that an EIP has been bound to the CDM cluster, the host where the data source is located can access the Internet, and the port has been enabled in the firewall rules.
- The ECS and the CDM cluster belong to the same enterprise project. If they do not, you can modify the enterprise project of the workspace.
Constraints
- Python nodes support script parameters and job parameters.
- This section uses Python3 as an example.
Creating an ECS Data Connection
Before developing a Python script, you need to create a connection to the ECS.
- Log in to the DataArts Studio console by following the instructions in Accessing the DataArts Studio Instance Console.
- On the DataArts Studio console, locate a workspace and click Management Center.
- On the displayed Manage Data Connections page, click Create Data Connection.
- Configure parameters by referring to Table 1 and create a data connection named ecs.
Table 1 Host Connection parameters Parameter
Mandatory
Description
Data Connection Type
Yes
Host Connection is selected by default and cannot be changed.
Name
Yes
Name of the data connection to create. Data connection names can contain a maximum of 100 characters. They can contain only letters, digits, underscores (_), and hyphens (-).
Tag
No
Attribute of the data connection to create. Tags make management easier.NOTE:The tag name can contain only letters, digits, and underscores (_) and cannot start with an underscore (_) or contain more than 100 characters.
Applicable Modules
Yes
Select the modules for which this connection is available.
Basic and Network Connectivity Configuration
Host Address
Yes
IP address of the Linux host
For details, see Viewing Details About an ECS.
Agent
Yes
CDM cluster used as an agent. If no CDM cluster is available, create one first by referring to Creating a CDM Cluster.
NOTE:-
If a CDM cluster functions as the agent for a data connection in Management Center, the cluster supports a maximum of 200 concurrent active threads. If multiple data connections share an agent, a maximum of 200 SQL, Shell, and Python scripts submitted through the connections can run concurrently. Excess tasks will be queued. You are advised to plan multiple agents based on the workload.
- When scheduling shell or Python scripts, the agent accesses the ECS. If shell and Python scripts are scheduled frequently, the ECS adds the private IP address of the agent to the blocklist. To ensure normal job scheduling, you are advised to use the root user of the ECS to add the private IP address bound to the agent (CDM cluster) to the /etc/hosts.allow file.
For details about how to obtain the private IP address of the CDM cluster, see Viewing and Modifying CDM Cluster Configurations.
Port
Yes
SSH port number of the host.
By default, port 22 is used to log in to a Linux host. If the port number has been changed, you can obtain the new port number from the port field in the /etc/ssh/sshd_config file.
KMS Key
Yes
KMS key used to encrypt and decrypt data source authentication information. Select a default or custom key.NOTE:- When you use KMS for encryption through DataArts Studio or KPS for the first time, the default key dlf/default or kps/default is automatically generated. For more information about default keys, see What Is a Default Master Key?.
- Only symmetric keys are supported. Asymmetric keys are not supported.
Data Source Authentication and Other Function Configuration
Username
Yes
Username for logging in to the host
Login Mode
Yes
Mode for logging in to the host
- Key Pair
- Password
Key Pair
Yes
This parameter is available only when Login Mode is set to Key Pair.
If Key Pair is the login mode of the host, you need to obtain the private key file, upload it to OBS, and select an OBS path.
NOTE:The uploaded private key must match the public key configured on the host. For details, see Application Scenarios for Using Key Pairs.
Key Pair Password
Yes
If no password is set for the key pair, you do not need to set this parameter.
Password
Yes
This parameter is available only when Login Mode is set to Password.
If the login mode of the host is to use a password, enter a login password.
Host Connection Description
No
Descriptive information about the host connection
Figure 1 Creating a host connection
The key parameters are as follows:
- Host Address: Enter the IP address of the ECS.
- Agent: Select the CDM cluster you have obtained from the DataArts Migration incremental package.
-
- Click Test to test connectivity of the data connection. If the test fails, the data connection cannot be created.
- After the test is successful, click OK to create the data connection.
Developing a Python Script
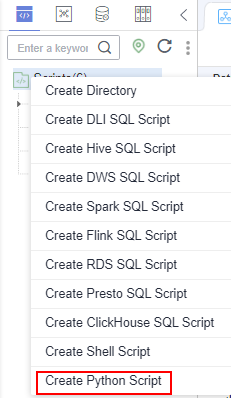
- Choose DataArts Factory > Develop Script and create a Python script named python_test. Figure 2 Creating a Python script
- Select a Python version (for example, Python 3) and host connection, and set input parameters as needed.
The parameters will be transferred to the Python script when the script is executed. The parameters are separated by spaces, for example, Microsoft Oracle. The parameters must be referenced by the Python script. Otherwise, the parameters are invalid.
- Edit Python statements in the editor. This example defines a string template for saving company information and uses the template to output information about different companies.
import sys Company_Name1=sys.argv[1] Company_Name2=sys.argv[2] template='No.:{:0>9s} \t CompanyName: {:s} \t Website: https://www.{:s}.com' context1=template.format('1',Company_Name1,Company_Name1.lower()) context2=template.format('2',Company_Name2,Company_Name2.lower()) print(context1) print(context2) - The script development area in Figure 3 is a temporary debugging area. After you close the script tab, the development area will be cleared.
- Connection: Select the data connection created in Creating an ECS Data Connection.
- Click Save and then Submit.
- Click Execute to execute the Python statements.
- View the script execution result. Figure 4 Viewing the script execution result


Referencing the Python Script in a Job
- Create a job.
- Select a Python node and configure the node properties. Select the created Python script and set the node parameters. Set Script Parameters.
The parameters will be transferred to the Python statement when the statement is executed. The parameters are separated by spaces, for example, Microsoft Oracle. The parameters must be referenced by the Python statement. Otherwise, the parameters are invalid.
Figure 5 Configuring properties of the Python node
- Click Test and view the job running result. Figure 6 Checking the job execution result

- Click Save. The job configuration is complete.
- Click Submit. After a version is submitted, the job can be scheduled.
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.




