
Scaling In an MRS Cluster
You can reduce the number of core or task nodes to scale in a cluster based on service requirements so that MRS delivers better storage and computing capabilities at lower O&M costs.
Only pay-per-use clusters can be scaled in. For details about how to scale in a yearly/monthly node, see Unsubscribing from a Specified Node in a Yearly/Monthly MRS Cluster.
Background
A cluster can have three types of nodes, master, core, and task nodes. Currently, only core and task nodes can be removed. To scale in a cluster, you only need to adjust the number of nodes on the MRS console. MRS then automatically selects the nodes to be removed.
The policies for MRS to automatically select nodes are as follows:
- MRS does not select the nodes with basic components installed, such as ZooKeeper, DBService, KrbServer, and LdapServer, because these basic components are the basis for the cluster to run.
- Core nodes store cluster service data. When scaling in a cluster, ensure that all data on the core nodes to be removed has been migrated to other nodes. You can perform follow-up scale-in operations only after all component services are decommissioned, for example, removing nodes from Manager and deleting ECSs. When selecting core nodes, MRS preferentially selects the nodes with a small amount of data and healthy instances to be decommissioned to prevent decommissioning failures. For example, if DataNodes are installed on core nodes in an analysis cluster, MRS preferentially selects the nodes with small data volume and good health status during scale-in.
When core nodes are removed, their data is migrated to other nodes. If the user business has cached the data storage path, the client will automatically update the path, which may increase the service processing latency temporarily. Cluster scale-in may slow the response of the first access to some HBase on HDFS data. You can restart HBase or disable or enable related tables to resolve this issue.
- Task nodes are computing nodes and do not store cluster data. Data migration is not involved in removing task nodes. Therefore, when selecting task nodes, MRS preferentially selects nodes whose health status is faulty, unknown, or subhealthy. On the Components tab of the MRS console, click a service and then the Instances tab to view the health status of the node instances.
Scale-In Verification Policy
To prevent component decommissioning failures, components provide different decommissioning constraints. Scale-in is allowed only when the constraints of all installed components are met. Table 1 describes the scale-in verification policies.
|
Component |
Constraint |
|---|---|
|
HDFS/DataNode |
The number of available nodes after the scale-in is greater than or equal to the number of HDFS copies and the total HDFS data volume does not exceed 80% of the total HDFS cluster capacity. This ensures that the remaining space is sufficient for storing existing data after the scale-in and reserves some space for future use.
NOTE:
To ensure data reliability, one backup is automatically generated for each file saved in HDFS, that is, two copies are generated in total. |
|
HBase/RegionServer |
The total available memory of RegionServers on all nodes except the nodes to be removed is greater than 1.2 times of the memory which is currently used by RegionServers on these nodes. This ensures that the node to which the region on a decommissioned node is migrated has sufficient memory to bear the region of the decommissioned node. |
|
Storm/ Supervisor |
After the scale-in, ensure that the number of slots in the cluster is sufficient for running the submitted tasks. This prevents no sufficient resources being available for running the stream processing tasks after the scale-in. |
|
Flume/FlumeServer |
If FlumeServer is installed on a node and Flume tasks have been configured for the node, the node cannot be deleted. This prevents the deployed service program from being deleted by mistake. |
|
ClickHouse/ClickHouseServer |
For details, see Constraints on ClickHouseServer Scale-in. This ensures that data on the decommissioned nodes is migrated to in-use nodes. |
|
Kudu/KuduTserver |
Rule: When you decommission a Kudu Tserver, all other Kudu instance nodes in the cluster must be normal for the process to succeed. Cause: During the decommissioning of a KuduTserver, a rebalance command is executed to migrate the tablets from the decommissioned instance to other KuduTserver nodes in the cluster. If any other KuduTserver nodes are in an abnormal state, the rebalance command will fail, resulting in decommissioning failure. |
Scaling In a Cluster by Specifying the Node Quantity
- Log in to the MRS console.
- On the Active Clusters page, select a running cluster and click its name to switch to the cluster details page.
- Click the Nodes tab. In the Operation column of the node group, click Scale In to go to the Scale In page.
This operation can be performed only when the cluster and all nodes in it are running.
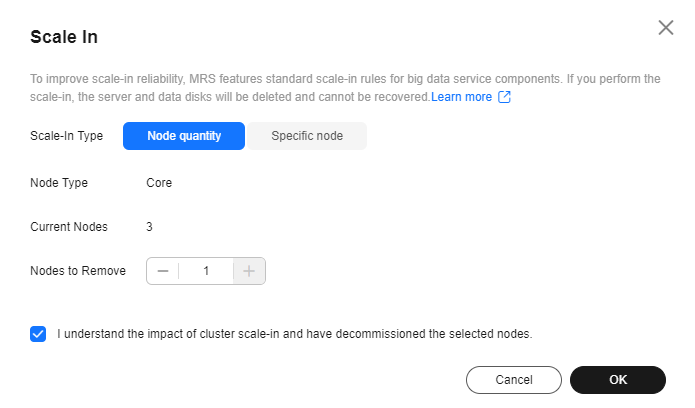
- Set Scale-In Type to Node quantity.
- Set Scale-In Nodes and click OK.
- Before scaling in the cluster, check whether its security group configuration is correct. Ensure that an inbound security group rule contains a rule in which Protocol & Port is set to All, and Source is set to a trusted accessible IP address range.
- If damaged data blocks exist in HDFS, the cluster may fail to be scaled in. Contact Huawei Cloud technical support.
- A dialog box displayed in the upper right corner of the page indicates that the task of removing the node is submitted successfully.
The cluster scale-in process is explained as follows:
- During scale-in: The cluster status is Scaling In. The submitted jobs will be executed, and you can submit new jobs. You are not allowed to continue to scale in or delete the cluster. You are advised not to restart the cluster or modify the cluster configuration.
- Successful scale-in: The cluster status is Running. The resources used after the cluster scale-in are billed.
- Failed scale-in: The cluster status is Running. You can execute jobs or scale-in the cluster again.
After the cluster is scaled in, you can view the node information of the cluster on the Nodes page.
Scaling In a Cluster by Removing Nodes that Are No Longer Needed
Delete a node when it is no longer needed. Before deleting a node, decommission the role instance of the component and back up the node's data. For details about how to remove ClickHouseServer nodes, see Scaling In ClickHouseServer Nodes.
- Log in to the MRS management console.
- Click the name of the cluster to go to its details page.
- Click the Nodes tab.
- Locate the row that contains the target node group and click Scale In in the Operation column to go to the Scale In page.
- Set Scale-In Type to Specific node and select the node to be removed.
Nodes in the Stopped, Lost, Unknown, Isolated, or Faulty status can be specified for scale-in. If the node cannot be selected, click Stop ECS to go to the ECS console to stop the node. On the cluster details page of the MRS console, click the Alarms tab and check whether any service fault alarms are generated after the node is stopped. If no such an alarm is generated, go back to the Scale In page and select the corresponding node for scale-in. If such an alarm is generated, clear the alarm before the scale-in.
This operation may cause data loss. Decommission nodes before scale-in. For details, see Decommissioning and Recommissioning an MRS Role Instance.
- Select I understand the consequences of performing the scale-in operation, Click OK.
- Click the Components tab and check whether each component is normal. If any component is abnormal, wait for 5 to 10 minutes and check the component status again. If the fault persists, contact technical support.
- Click the Alarms tab and check whether there are exception alarms. If there are exception alarms, clear them before performing other operations.
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.




