
- What's New
- Function Overview
-
Service Overview
- Infographics
- What Is MRS?
- Advantages
- Application Scenarios
- MRS Cluster Version Overview
- List of MRS Component Versions
- Components
- Functions
- Constraints
- Technical Support
- Billing
- Permissions Management
- Related Services
- Quota Description
- Common Concepts
-
Getting Started
- Creating and Using a Hadoop Cluster for Offline Analysis
- Creating and Using a Kafka Cluster for Stream Processing
- Creating and Using an HBase Cluster for Offline Query
- Creating and Using a ClickHouse Cluster for Columnar Store
- Creating and Using an MRS Cluster Requiring Security Authentication
- Best Practices for Beginners
-
User Guide
- Preparing a User
-
Configuring a Cluster
- How to Buy an MRS Cluster
- Quick Configuration
- Buying a Custom Cluster
- Configuring Custom Topology
- Adding a Tag to a Cluster/Node
- Communication Security Authorization
-
Configuring Auto Scaling Rules
- Overview
- Configuring Auto Scaling During Cluster Creation
- Creating an Auto Scaling Policy for an Existing Cluster
- Scenario 1: Using Auto Scaling Rules Alone
- Scenario 2: Using Resource Plans Alone
- Scenario 3: Using Both Auto Scaling Rules and Resource Plans
- Modifying an Auto Scaling Policy
- Deleting an Auto Scaling Policy
- Enabling or Disabling an Auto Scaling Policy
- Viewing an Auto Scaling Policy
- Configuring Automation Scripts
- Configuring Auto Scaling Metrics
- Managing Data Connections
- Installing Third-Party Software Using Bootstrap Actions
- Viewing Failed MRS Tasks
- Viewing Information of a Historical Cluster
-
Managing Clusters
- Logging In to a Cluster
- Cluster Overview
- Viewing and Customizing Cluster Monitoring Metrics
-
Cluster O&M
- Importing and Exporting Data
- Changing the Subnet of a Cluster
- Configuring Message Notification
- Checking Health Status
- Remote O&M
- Viewing MRS Operation Logs
- Changing Billing Mode to Yearly/Monthly
- Unsubscribing from a Cluster
- Unsubscribing from a Specified Node in a Yearly/Monthly Cluster
- Deleting a Cluster
- Managing Nodes
-
Job Management
- Introduction to MRS Jobs
- Running a MapReduce Job
- Running a SparkSubmit or Spark Job
- Running a HiveSQL Job
- Running a SparkSql Job
- Running a Flink Job
- Running a HadoopStreaming Job
- Viewing Job Configuration and Logs
- Stopping a Job
- Deleting a Job
- Using Encrypted OBS Data for Job Running
- Configuring Job Notification Rules
-
Component Management
- Object Management
- Viewing Configuration
- Managing Services
- Configuring Service Parameters
- Configuring Customized Service Parameters
- Synchronizing Service Configuration
- Managing Role Instances
- Configuring Role Instance Parameters
- Synchronizing Role Instance Configuration
- Decommissioning and Recommissioning a Role Instance
- Starting and Stopping a Cluster
- Synchronizing Cluster Configuration
- Exporting Cluster Configuration
- Performing Rolling Restart
- Alarm Management
-
Patch Management
- Installing an Online Patch
- Installing a Rolling Patch
- Restoring Patches for the Isolated Hosts
-
MRS Patch Description
- Fixed the Privilege Escalation Vulnerability of User omm
- MRS 3.2.0-LTS.1 Patch Description
- MRS 2.1.0.11 Patch Description
- MRS 3.0.5.1 Patch Description
- MRS 2.1.0.10 Patch Description
- MRS 2.1.0.9 Patch Description
- MRS 2.1.0.8 Patch Description
- MRS 2.1.0.7 Patch Description
- MRS 2.1.0.6 Patch Description
- MRS 2.1.0.3 Patch Description
- MRS 2.1.0.2 Patch Description
- MRS 2.1.0.1 Patch Description
- MRS 2.0.6.1 Patch Description
- MRS 2.0.1.3 Patch Description
- MRS 2.0.1.2 Patch Description
- MRS 2.0.1.1 Patch Description
- MRS 1.9.3.3 Patch Description
- MRS 1.9.3.1 Patch Description
- MRS 1.9.2.2 Patch Description
- MRS 1.9.0.8, 1.9.0.9, and 1.9.0.10 Patch Description
- MRS 1.9.0.7 Patch Description
- MRS 1.9.0.6 Patch Description
- MRS 1.9.0.5 Patch Description
- MRS 1.8.10.1 Patch Description
-
Tenant Management
- Before You Start
- Overview
- Creating a Tenant
- Creating a Sub-tenant
- Deleting a Tenant
- Managing a Tenant Directory
- Restoring Tenant Data
- Creating a Resource Pool
- Modifying a Resource Pool
- Deleting a Resource Pool
- Configuring a Queue
- Configuring the Queue Capacity Policy of a Resource Pool
- Clearing Configuration of a Queue
- Bootstrap Actions
- Using an MRS Client
-
Configuring a Cluster with Decoupled Storage and Compute
- MRS Storage-Compute Decoupling
-
Interconnecting with OBS Using the Cluster Agency Mechanism
- Configuring a Storage-Compute Decoupled Cluster (Agency)
- Configuring a Storage-Compute Decoupled Cluster (AK/SK)
- Configuring the Policy for Clearing Component Data in the Recycle Bin
- Interconnecting MRS with OBS Using an Agency
- Configuring Fine-Grained Permissions for MRS Multi-User Access to OBS
- Accessing OBS from a Client on a Node Outside the Cluster
- Interconnecting with OBS Using the Guardian Service
- Accessing Web Pages of Open Source Components Managed in MRS Clusters
- Accessing Manager
-
FusionInsight Manager Operation Guide (Applicable to 3.x)
- Homepage
-
Cluster
- Cluster Management
- Managing a Service
- Instance Management
- Hosts
- O&M
- Audit
- Tenant Resources
- System
- Cluster Management
- Log Management
-
Backup and Recovery Management
- Introduction
-
Backing Up Data
- Backing Up Manager Data
- Backing Up CDL Data
- Backing Up ClickHouse Metadata
- Backing Up ClickHouse Service Data
- Backing Up DBService Data
- Backing Up Flink Metadata
- Backing Up HBase Metadata
- Backing Up HBase Service Data
- Backing Up NameNode Data
- Backing Up HDFS Service Data
- Backing Up Hive Service Data
- Backing Up IoTDB Metadata
- Backing Up IoTDB Service Data
- Backing Up Kafka Metadata
-
Recovering Data
- Restoring Manager Data
- Restoring CDL Data
- Restoring ClickHouse Metadata
- Restoring ClickHouse Service Data
- Restoring DBService data
- Restoring Flink Metadata
- Restoring HBase Metadata
- Restoring HBase Service Data
- Restoring NameNode Data
- Restoring HDFS Service Data
- Restoring Hive Service Data
- Restoring IoTDB Metadata
- Restoring IoTDB Service Data
- Restoring Kafka Metadata
- Enabling Cross-Cluster Replication
- Managing Local Quick Restoration Tasks
- Modifying a Backup Task
- Viewing Backup and Restoration Tasks
- How Do I Configure the Environment When I Create a ClickHouse Backup Task on FusionInsight Manager and Set the Path Type to RemoteHDFS?
- SQL Inspector
-
Security Management
- Security Overview
-
Account Management
- Account Security Settings
- Changing the Password for a System User
- Changing the Password for a System Internal User
-
Changing the Password for a Database User
- Changing the Password of the OMS Database Administrator
- Changing the Password for the Data Access User of the OMS Database
- Changing the Password for a Component Database User
- Resetting the Component Database User Password
- Changing the Password for User omm in DBService
- Changing the Password for User compdbuser of the DBService Database
- Changing or Resetting the Password for User admin of Manager
- Certificate Management
-
Security Hardening
- Hardening Policies
- Configuring a Trusted IP Address to Access LDAP
- HFile and WAL Encryption
- Configuring Hadoop Security Parameters
- Configuring an IP Address Whitelist for Modification Allowed by HBase
- Updating a Key for a Cluster
- Hardening the LDAP
- Configuring Kafka Data Encryption During Transmission
- Configuring HDFS Data Encryption During Transmission
- Configuring Spark2x Data Encryption During Transmission
- Configuring ZooKeeper SSL
- Encrypting the Communication Between the Controller and the Agent
- Updating SSH Keys for User omm
- Changing the Timeout Duration of the Manager Page
- Security Maintenance
- Security Statement
-
MRS Manager Operation Guide (Applicable to 2.x and Earlier Versions)
- Introduction to MRS Manager
- Checking Running Tasks
- Monitoring Management
- Alarm Management
-
Alarm Reference (Applicable to MRS 2.x and Earlier Versions)
- ALM-12001 Audit Log Dump Failure (For MRS 2.x or Earlier)
- ALM-12002 HA Resource Abnormal (For MRS 2.x or Earlier)
- ALM-12004 OLdap Resource Abnormal (For MRS 2.x or Earlier)
- ALM-12005 OKerberos Resource Abnormal (For MRS 2.x or Earlier)
- ALM-12006 Node Fault (For MRS 2.x or Earlier)
- ALM-12007 Process Fault (For MRS 2.x or Earlier)
- ALM-12010 Manager Heartbeat Interruption Between the Active and Standby Nodes (For MRS 2.x or Earlier)
- ALM-12011 Data Synchronization Exception Between the Active and Standby Manager Nodes (For MRS 2.x or Earlier)
- ALM-12012 NTP Service Abnormal (For MRS 2.x or Earlier)
- ALM-12014 Device Partition Lost (For MRS 2.x or Earlier)
- ALM-12015 Device Partition File System Read-Only (For MRS 2.x or Earlier)
- ALM-12016 CPU Usage Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-12017 Insufficient Disk Capacity (For MRS 2.x or Earlier)
- ALM-12018 Memory Usage Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-12027 Host PID Usage Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-12028 Number of Processes in the D State on the Host Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-12031 User omm or Password Is About to Expire (For MRS 2.x or Earlier)
- ALM-12032 User ommdba or Password Is About to Expire (For MRS 2.x or Earlier)
- ALM-12033 Slow Disk Fault (For MRS 2.x or Earlier)
- ALM-12034 Periodic Backup Failure (For MRS 2.x or Earlier)
- ALM-12035 Unknown Data Status After Recovery Task Failure (For MRS 2.x or Earlier)
- ALM-12037 NTP Server Abnormal (For MRS 2.x or Earlier)
- ALM-12038 Monitoring Indicator Dump Failure (For MRS 2.x or Earlier)
- ALM-12039 GaussDB Data Is Not Synchronized (For MRS 2.x or Earlier)
- ALM-12040 Insufficient System Entropy (For MRS 2.x or Earlier)
- ALM-12041 Permission of Key Files Is Abnormal (For MRS 2.x or Earlier)
- ALM-12042 Key File Configurations Are Abnormal (For MRS 2.x or Earlier)
- ALM-12043 DNS Parsing Duration Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-12045 Read Packet Dropped Rate Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-12046 Write Packet Dropped Rate Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-12047 Read Packet Error Rate Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-12048 Write Packet Error Rate Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-12049 Read Throughput Rate Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-12050 Write Throughput Rate Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-12051 Disk Inode Usage Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-12052 Usage of Temporary TCP Ports Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-12053 File Handle Usage Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-12054 Invalid Certificate File (For MRS 2.x or Earlier)
- ALM-12055 Certificate File Is About to Expire (For MRS 2.x or Earlier)
- ALM-12180 Disk Card I/O (For MRS 2.x or Earlier)
- ALM-12357 Failed to Export Audit Logs to OBS (For MRS 2.x or Earlier)
- ALM-13000 ZooKeeper Service Unavailable (For MRS 2.x or Earlier)
- ALM-13001 Available ZooKeeper Connections Are Insufficient (For MRS 2.x or Earlier)
- ALM-13002 ZooKeeper Memory Usage Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-14000 HDFS Service Unavailable (For MRS 2.x or Earlier)
- ALM-14001 HDFS Disk Usage Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-14002 DataNode Disk Usage Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-14003 Number of Lost HDFS Blocks Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-14004 Number of Damaged HDFS Blocks Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-14006 Number of HDFS Files Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-14007 HDFS NameNode Memory Usage Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-14008 HDFS DataNode Memory Usage Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-14009 Number of Faulty DataNodes Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-14010 NameService Is Abnormal (For MRS 2.x or Earlier)
- ALM-14011 HDFS DataNode Data Directory Is Not Configured Properly (For MRS 2.x or Earlier)
- ALM-14012 HDFS Journalnode Data Is Not Synchronized (For MRS 2.x or Earlier)
- ALM-16000 Percentage of Sessions Connected to the HiveServer to the Maximum Number Allowed Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-16001 Hive Warehouse Space Usage Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-16002 Hive SQL Execution Success Rate Is Lower Than the Threshold (For MRS 2.x or Earlier)
- ALM-16004 Hive Service Unavailable (For MRS 2.x or Earlier)
- ALM-16005 Number of Failed Hive SQL Executions in the Last Period Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-18000 Yarn Service Unavailable (For MRS 2.x or Earlier)
- ALM-18002 NodeManager Heartbeat Lost (For MRS 2.x or Earlier)
- ALM-18003 NodeManager Unhealthy (For MRS 2.x or Earlier)
- ALM-18004 NodeManager Disk Usability Ratio Is Lower Than the Threshold (For MRS 2.x or Earlier)
- ALM-18006 MapReduce Job Execution Timeout (For MRS 2.x or Earlier)
- ALM-18008 Heap Memory Usage of Yarn ResourceManager Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-18009 Heap Memory Usage of MapReduce JobHistoryServer Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-18010 Number of Pending Yarn Tasks Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-18011 Memory of Pending Yarn Tasks Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-18012 Number of Terminated Yarn Tasks in the Last Period Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-18013 Number of Failed Yarn Tasks in the Last Period Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-19000 HBase Service Unavailable (For MRS 2.x or Earlier)
- ALM-19006 HBase Replication Sync Failed (For MRS 2.x or Earlier)
- ALM-19007 HBase Merge Queue Exceeds the Threshold (for 2.x and Earlier Versions)
- ALM-20002 Hue Service Unavailable (For MRS 2.x or Earlier)
- ALM-23001 Loader Service Unavailable (For MRS 2.x or Earlier)
- ALM-24000 Flume Service Unavailable (For MRS 2.x or Earlier)
- ALM-24001 Flume Agent Is Abnormal (For MRS 2.x or Earlier)
- ALM-24003 Flume Client Connection Interrupted (For MRS 2.x or Earlier)
- ALM-24004 Flume Fails to Read Data (For MRS 2.x or Earlier)
- ALM-24005 Data Transmission by Flume Is Abnormal (For MRS 2.x or Earlier)
- ALM-25000 LdapServer Service Unavailable (For MRS 2.x or Earlier)
- ALM-25004 Abnormal LdapServer Data Synchronization (For MRS 2.x or Earlier)
- ALM-25500 KrbServer Service Unavailable (For MRS 2.x or Earlier)
- ALM-26051 Storm Service Unavailable (For MRS 2.x or Earlier)
- ALM-26052 Number of Available Supervisors in Storm Is Lower Than the Threshold (For MRS 2.x or Earlier)
- ALM-26053 Slot Usage of Storm Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-26054 Heap Memory Usage of Storm Nimbus Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-27001 DBService Unavailable (For MRS 2.x or Earlier)
- ALM-27003 DBService Heartbeat Interruption Between the Active and Standby Nodes (For MRS 2.x or Earlier)
- ALM-27004 Data Inconsistency Between Active and Standby DBServices (For MRS 2.x or Earlier)
- ALM-28001 Spark Service Unavailable (For MRS 2.x or Earlier)
- ALM-38000 Kafka Service Unavailable (For MRS 2.x or Earlier)
- ALM-38001 Insufficient Kafka Disk Capacity (For MRS 2.x or Earlier)
- ALM-38002 Heap Memory Usage of Kafka Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-43001 Spark Service Unavailable (For MRS 2.x or Earlier)
- ALM-43006 Heap Memory Usage of the JobHistory Process Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-43007 Non-Heap Memory Usage of the JobHistory Process Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-43008 Direct Memory Usage of the JobHistory Process Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-43009 JobHistory GC Time Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-43010 Heap Memory Usage of the JDBCServer Process Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-43011 Non-Heap Memory Usage of the JDBCServer Process Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-43012 Direct Memory Usage of the JDBCServer Process Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-43013 JDBCServer GC Time Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-44004 Presto Coordinator Resource Group Queuing Tasks Exceed the Threshold (For MRS 2.x or Earlier)
- ALM-44005 Presto Coordinator Process GC Time Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-44006 Presto Worker Process GC Time Exceeds the Threshold (For MRS 2.x or Earlier)
- ALM-45325 Presto Service Unavailable (For MRS 2.x or Earlier)
-
Object Management
- Managing Objects
- Viewing Configurations
- Managing Services
- Configuring Service Parameters
- Configuring Customized Service Parameters
- Synchronizing Service Configurations
- Managing Role Instances
- Configuring Role Instance Parameters
- Synchronizing Role Instance Configuration
- Decommissioning and Recommissioning a Role Instance
- Managing a Host
- Isolating a Host
- Canceling Host Isolation
- Starting or Stopping a Cluster
- Synchronizing Cluster Configurations
- Exporting Configuration Data of a Cluster
- Log Management
-
Health Check Management
- Performing a Health Check
- Viewing and Exporting a Health Check Report
- Configuring the Number of Health Check Reports to Be Reserved
- Managing Health Check Reports
- DBService Health Check Indicators
- Flume Health Check Indicators
- HBase Health Check Indicators
- Host Health Check Indicators
- HDFS Health Check Indicators
- Hive Health Check Indicators
- Kafka Health Check Indicators
- KrbServer Health Check Indicators
- LdapServer Health Check Indicators
- Loader Health Check Indicators
- MapReduce Health Check Indicators
- OMS Health Check Indicators
- Spark Health Check Indicators
- Storm Health Check Indicators
- Yarn Health Check Indicators
- ZooKeeper Health Check Indicators
- Static Service Pool Management
-
Tenant Management
- Overview
- Creating a Tenant
- Creating a Sub-tenant
- Deleting a tenant
- Managing a Tenant Directory
- Restoring Tenant Data
- Creating a Resource Pool
- Modifying a Resource Pool
- Deleting a Resource Pool
- Configuring a Queue
- Configuring the Queue Capacity Policy of a Resource Pool
- Clearing Configuration of a Queue
- Backup and Restoration
-
Security Management
- Default Users of Clusters with Kerberos Authentication Disabled
- Default Users of Clusters with Kerberos Authentication Enabled
- Changing the Password of an OS User
- Changing the password of user admin
- Changing the Password of the Kerberos Administrator
- Changing the Passwords of the LDAP Administrator and the LDAP User
- Changing the Password of a Component Running User
- Changing the Password of the OMS Database Administrator
- Changing the Password of the Data Access User of the OMS Database
- Changing the Password of a Component Database User
- Replacing the HA Certificate
- Updating Cluster Keys
- Permissions Management
-
MRS Multi-User Permission Management
- Users and Permissions of MRS Clusters
- Default Users of Clusters with Kerberos Authentication Enabled
- Creating a Role
- Creating a User Group
- Creating a User
- Modifying User Information
- Locking a User
- Unlocking a User
- Deleting a User
- Changing the Password of an Operation User
- Initializing the Password of a System User
- Downloading a User Authentication File
- Modifying a Password Policy
- Configuring Cross-Cluster Mutual Trust Relationships
- Configuring Users to Access Resources of a Trusted Cluster
- Patch Operation Guide
- Restoring Patches for the Isolated Hosts
- Rolling Restart
-
Alarm Reference (Applicable to MRS 3.x)
- ALM-12001 Audit Log Dumping Failure
- ALM-12004 OLdap Resource Abnormal
- ALM-12005 OKerberos Resource Abnormal
- ALM-12006 Node Fault
- ALM-12007 Process Fault
- ALM-12010 Manager Heartbeat Interruption Between the Active and Standby Nodes
- ALM-12011 Manager Data Synchronization Exception Between the Active and Standby Nodes
- ALM-12012 NTP Service Is Abnormal
- ALM-12014 Partition Lost
- ALM-12015 Partition Filesystem Readonly
- ALM-12016 CPU Usage Exceeds the Threshold
- ALM-12017 Insufficient Disk Capacity
- ALM-12018 Memory Usage Exceeds the Threshold
- ALM-12027 Host PID Usage Exceeds the Threshold
- ALM-12028 Number of Processes in the D State and Z State on a Host Exceeds the Threshold
- ALM-12033 Slow Disk Fault
- ALM-12034 Periodical Backup Failure
- ALM-12035 Unknown Data Status After Recovery Task Failure
- ALM-12037 NTP Server Abnormal
- ALM-12038 Monitoring Indicator Dumping Failure
- ALM-12039 Active/Standby OMS Databases Not Synchronized
- ALM-12040 Insufficient System Entropy
- ALM-12041 Incorrect Permission on Key Files
- ALM-12042 Incorrect Configuration of Key Files
- ALM-12045 Read Packet Dropped Rate Exceeds the Threshold
- ALM-12046 Write Packet Dropped Rate Exceeds the Threshold
- ALM-12047 Read Packet Error Rate Exceeds the Threshold
- ALM-12048 Write Packet Error Rate Exceeds the Threshold
- ALM-12049 Network Read Throughput Rate Exceeds the Threshold
- ALM-12050 Network Write Throughput Rate Exceeds the Threshold
- ALM-12051 Disk Inode Usage Exceeds the Threshold
- ALM-12052 TCP Temporary Port Usage Exceeds the Threshold
- ALM-12053 Host File Handle Usage Exceeds the Threshold
- ALM-12054 Invalid Certificate File
- ALM-12055 Certificate File Is About to Expire
- ALM-12057 Metadata Not Configured with the Task to Periodically Back Up Data to a Third-Party Server
- ALM-12061 Process Usage Exceeds the Threshold
- ALM-12062 OMS Parameter Configurations Mismatch with the Cluster Scale
- ALM-12063 Unavailable Disk
- ALM-12064 Host Random Port Range Conflicts with Cluster Used Port
- ALM-12066 Trust Relationships Between Nodes Become Invalid
- ALM-12067 Tomcat Resource Is Abnormal
- ALM-12068 ACS Resource Exception
- ALM-12069 AOS Resource Exception
- ALM-12070 Controller Resource Is Abnormal
- ALM-12071 Httpd Resource Is Abnormal
- ALM-12072 FloatIP Resource Is Abnormal
- ALM-12073 CEP Resource Is Abnormal
- ALM-12074 FMS Resource Is Abnormal
- ALM-12075 PMS Resource Is Abnormal
- ALM-12076 GaussDB Resource Is Abnormal
- ALM-12077 User omm Expired
- ALM-12078 Password of User omm Expired
- ALM-12079 User omm Is About to Expire
- ALM-12080 Password of User omm Is About to Expire
- ALM-12081User ommdba Expired
- ALM-12082 User ommdba Is About to Expire
- ALM-12083 Password of User ommdba Is About to Expire
- ALM-12084 Password of User ommdba Expired
- ALM-12085 Service Audit Log Dump Failure
- ALM-12087 System Is in the Upgrade Observation Period
- ALM-12089 Inter-Node Network Is Abnormal
- ALM-12091 Abnormal disaster Resources
- ALM-12099 core dump Occurred
- ALM-12100 AD Service Connection Failed
- ALM-12101 AZ Unhealthy
- ALM-12102 AZ HA Component Is Not Deployed Based on DR Requirements
- ALM-12103 Executor Resource Exception
- ALM-12104 Abnormal Knox Resources
- ALM-12110 Failed to get ECS temporary AK/SK
- ALM-12172 Failed to Report Metrics to Cloud Eye
- ALM-12180 Suspended Disk I/O
- ALM-12186 CGroup Task Usage Exceeds the Threshold
- ALM-12187 Failed to Expand Disk Partition Capacity
- ALM-12188 diskmgt Disk Monitoring Unavailable
- ALM-12190 Number of Knox Connections Exceeds the Threshold
- ALM-13000 ZooKeeper Service Unavailable
- ALM-13001 Available ZooKeeper Connections Are Insufficient
- ALM-13002 ZooKeeper Direct Memory Usage Exceeds the Threshold
- ALM-13003 GC Duration of the ZooKeeper Process Exceeds the Threshold
- ALM-13004 ZooKeeper Heap Memory Usage Exceeds the Threshold
- ALM-13005 Failed to Set the Quota of Top Directories of ZooKeeper Components
- ALM-13006 Znode Number or Capacity Exceeds the Threshold
- ALM-13007 Available ZooKeeper Client Connections Are Insufficient
- ALM-13008 ZooKeeper Znode Usage Exceeds the Threshold
- ALM-13009 ZooKeeper Znode Capacity Usage Exceeds the Threshold
- ALM-13010 Znode Usage of a Directory with Quota Configured Exceeds the Threshold
- ALM-14000 HDFS Service Unavailable
- ALM-14001 HDFS Disk Usage Exceeds the Threshold
- ALM-14002 DataNode Disk Usage Exceeds the Threshold
- ALM-14003 Number of Lost HDFS Blocks Exceeds the Threshold
- ALM-14006 Number of HDFS Files Exceeds the Threshold
- ALM-14007 NameNode Heap Memory Usage Exceeds the Threshold
- ALM-14008 DataNode Heap Memory Usage Exceeds the Threshold
- ALM-14009 Number of Dead DataNodes Exceeds the Threshold
- ALM-14010 NameService Service Is Abnormal
- ALM-14011 DataNode Data Directory Is Not Configured Properly
- ALM-14012 JournalNode Is Out of Synchronization
- ALM-14013 Failed to Update the NameNode FsImage File
- ALM-14014 NameNode GC Time Exceeds the Threshold
- ALM-14015 DataNode GC Time Exceeds the Threshold
- ALM-14016 DataNode Direct Memory Usage Exceeds the Threshold
- ALM-14017 NameNode Direct Memory Usage Exceeds the Threshold
- ALM-14018 NameNode Non-heap Memory Usage Exceeds the Threshold
- ALM-14019 DataNode Non-heap Memory Usage Exceeds the Threshold
- ALM-14020 Number of Entries in the HDFS Directory Exceeds the Threshold
- ALM-14021 NameNode Average RPC Processing Time Exceeds the Threshold
- ALM-14022 NameNode Average RPC Queuing Time Exceeds the Threshold
- ALM-14023 Percentage of Total Reserved Disk Space for Replicas Exceeds the Threshold
- ALM-14024 Tenant Space Usage Exceeds the Threshold
- ALM-14025 Tenant File Object Usage Exceeds the Threshold
- ALM-14026 Blocks on DataNode Exceed the Threshold
- ALM-14027 DataNode Disk Fault
- ALM-14028 Number of Blocks to Be Supplemented Exceeds the Threshold
- ALM-14029 Number of Blocks in a Replica Exceeds the Threshold
- ALM-14030 HDFS Allows Write of Single-Replica Data
- ALM-14031 DataNode Process Is Abnormal
- ALM-14032 JournalNode Process Is Abnormal
- ALM-14033 ZKFC Process Is Abnormal
- ALM-14034 Router Process Is Abnormal
- ALM-14035 HttpFS Process Is Abnormal
- ALM-16000 Percentage of Sessions Connected to the HiveServer to Maximum Number Allowed Exceeds the Threshold
- ALM-16001 Hive Warehouse Space Usage Exceeds the Threshold
- ALM-16002 Hive SQL Execution Success Rate Is Lower Than the Threshold
- ALM-16003 Background Thread Usage Exceeds the Threshold
- ALM-16004 Hive Service Unavailable
- ALM-16005 The Heap Memory Usage of the Hive Process Exceeds the Threshold
- ALM-16006 The Direct Memory Usage of the Hive Process Exceeds the Threshold
- ALM-16007 Hive GC Time Exceeds the Threshold
- ALM-16008 Non-Heap Memory Usage of the Hive Process Exceeds the Threshold
- ALM-16009 Map Number Exceeds the Threshold
- ALM-16045 Hive Data Warehouse Is Deleted
- ALM-16046 Hive Data Warehouse Permission Is Modified
- ALM-16047 HiveServer Has Been Deregistered from ZooKeeper
- ALM-16048 Tez or Spark Library Path Does Not Exist
- ALM-17003 Oozie Service Unavailable
- ALM-17004 Oozie Heap Memory Usage Exceeds the Threshold
- ALM-17005 Oozie Non Heap Memory Usage Exceeds the Threshold
- ALM-17006 Oozie Direct Memory Usage Exceeds the Threshold
- ALM-17007 Garbage Collection (GC) Time of the Oozie Process Exceeds the Threshold
- ALM-17008 Abnormal Connection Between Oozie and ZooKeeper
- ALM-17009 Abnormal Connection Between Oozie and DBService
- ALM-17010 Abnormal Connection Between Oozie and HDFS
- ALM-17011 Abnormal Connection Between Oozie and Yarn
- ALM-18000 Yarn Service Unavailable
- ALM-18002 NodeManager Heartbeat Lost
- ALM-18003 NodeManager Unhealthy
- ALM-18008 Heap Memory Usage of ResourceManager Exceeds the Threshold
- ALM-18009 Heap Memory Usage of JobHistoryServer Exceeds the Threshold
- ALM-18010 ResourceManager GC Time Exceeds the Threshold
- ALM-18011 NodeManager GC Time Exceeds the Threshold
- ALM-18012 JobHistoryServer GC Time Exceeds the Threshold
- ALM-18013 ResourceManager Direct Memory Usage Exceeds the Threshold
- ALM-18014 NodeManager Direct Memory Usage Exceeds the Threshold
- ALM-18015 JobHistoryServer Direct Memory Usage Exceeds the Threshold
- ALM-18016 Non Heap Memory Usage of ResourceManager Exceeds the Threshold
- ALM-18017 Non Heap Memory Usage of NodeManager Exceeds the Threshold
- ALM-18018 NodeManager Heap Memory Usage Exceeds the Threshold
- ALM-18019 Non Heap Memory Usage of JobHistoryServer Exceeds the Threshold
- ALM-18020 Yarn Task Execution Timeout
- ALM-18021 Mapreduce Service Unavailable
- ALM-18022 Insufficient Yarn Queue Resources
- ALM-18023 Number of Pending Yarn Tasks Exceeds the Threshold
- ALM-18024 Pending Yarn Memory Usage Exceeds the Threshold
- ALM-18025 Number of Terminated Yarn Tasks Exceeds the Threshold
- ALM-18026 Number of Failed Yarn Tasks Exceeds the Threshold
- ALM-19000 HBase Service Unavailable
- ALM-19006 HBase Replication Sync Failed
- ALM-19007 HBase GC Time Exceeds the Threshold
- ALM-19008 Heap Memory Usage of the HBase Process Exceeds the Threshold
- ALM-19009 Direct Memory Usage of the HBase Process Exceeds the Threshold
- ALM-19011 RegionServer Region Number Exceeds the Threshold
- ALM-19012 HBase System Table Directory or File Lost
- ALM-19013 Duration of Regions in transaction State Exceeds the Threshold
- ALM-19014 Capacity Quota Usage on ZooKeeper Exceeds the Threshold Severely
- ALM-19015 Quantity Quota Usage on ZooKeeper Exceeds the Threshold
- ALM-19016 Quantity Quota Usage on ZooKeeper Exceeds the Threshold Severely
- ALM-19017 Capacity Quota Usage on ZooKeeper Exceeds the Threshold
- ALM-19018 HBase Compaction Queue Size Exceeds the Threshold
- ALM-19019 Number of HBase HFiles to Be Synchronized Exceeds the Threshold
- ALM-19020 Number of HBase WAL Files to Be Synchronized Exceeds the Threshold
- ALM-19021 Handler Usage of RegionServer Exceeds the Threshold
- ALM-19022 HBase Hotspot Detection Is Unavailable
- ALM-19023 Region Traffic Restriction for HBase
- ALM-19024 RPC Requests P99 Latency on RegionServer Exceeds the Threshold
- ALM-19025 Damaged StoreFile in HBase
- ALM-19026 Damaged WAL Files in HBase
- ALM-20002 Hue Service Unavailable
- ALM-23001 Loader Service Unavailable
- ALM-23003 Loader Task Execution Failure
- ALM-23004 Loader Heap Memory Usage Exceeds the Threshold
- ALM-23005 Loader Non-Heap Memory Usage Exceeds the Threshold
- ALM-23006 Loader Direct Memory Usage Exceeds the Threshold
- ALM-23007 Garbage Collection (GC) Time of the Loader Process Exceeds the Threshold
- ALM-24000 Flume Service Unavailable
- ALM-24001 Flume Agent Exception
- ALM-24003 Flume Client Connection Interrupted
- ALM-24004 Exception Occurs When Flume Reads Data
- ALM-24005 Exception Occurs When Flume Transmits Data
- ALM-24006 Heap Memory Usage of Flume Server Exceeds the Threshold
- ALM-24007 Flume Server Direct Memory Usage Exceeds the Threshold
- ALM-24008 Flume Server Non Heap Memory Usage Exceeds the Threshold
- ALM-24009 Flume Server Garbage Collection (GC) Time Exceeds the Threshold
- ALM-24010 Flume Certificate File Is Invalid or Damaged
- ALM-24011 Flume Certificate File Is About to Expire
- ALM-24012 Flume Certificate File Has Expired
- ALM-24013 Flume MonitorServer Certificate File Is Invalid or Damaged
- ALM-24014 Flume MonitorServer Certificate Is About to Expire
- ALM-24015 Flume MonitorServer Certificate File Has Expired
- ALM-25000 LdapServer Service Unavailable
- ALM-25004 Abnormal LdapServer Data Synchronization
- ALM-25005 nscd Service Exception
- ALM-25006 Sssd Service Exception
- ALM-25007 Number of SlapdServer Connections Exceeds the Threshold
- ALM-25008 SlapdServer CPU Usage Exceeds the Threshold
- ALM-25500 KrbServer Service Unavailable
- ALM-26051 Storm Service Unavailable
- ALM-26052 Number of Available Supervisors of the Storm Service Is Less Than the Threshold
- ALM-26053 Storm Slot Usage Exceeds the Threshold
- ALM-26054 Nimbus Heap Memory Usage Exceeds the Threshold
- ALM-27001 DBService Service Unavailable
- ALM-27003 DBService Heartbeat Interruption Between the Active and Standby Nodes
- ALM-27004 Data Inconsistency Between Active and Standby DBServices
- ALM-27005 Database Connections Usage Exceeds the Threshold
- ALM-27006 Disk Space Usage of the Data Directory Exceeds the Threshold
- ALM-27007 Database Enters the Read-Only Mode
- ALM-29000 Impala Service Unavailable
- ALM-29004 Impalad Process Memory Usage Exceeds the Threshold
- ALM-29005 Number of JDBC Connections to Impalad Exceeds the Threshold
- ALM-29006 Number of ODBC Connections to Impalad Exceeds the Threshold
- ALM-29007 Impalad Process Memory Usage Exceeds the Threshold
- ALM-29008 Number of ODBC Connections to Impalad Exceeds the Threshold
- ALM-29010 Number of Queries Being Submitted by Impalad Exceeds the Threshold
- ALM-29011 Number of Queries Being Executed by Impalad Exceeds the Threshold
- ALM-29012 Number of Queries Being Waited by Impalad Exceeds the Threshold
- ALM-29013 Impalad FGC Time Exceeds the Threshold
- ALM-29014 Catalog FGC Time Exceeds the Threshold
- ALM-29015 Catalog Process Memory Usage Exceeds the Threshold
- ALM-29016 Impalad Instance in the Sub-healthy State
- ALM-29100 Kudu Service Unavailable
- ALM-29104 Tserver Process Memory Usage Exceeds the Threshold
- ALM-29106 Tserver Process CPU Usage Exceeds the Threshold
- ALM-29107 Tserver Process Memory Usage Exceeds the Threshold
- ALM-38000 Kafka Service Unavailable
- ALM-38001 Insufficient Kafka Disk Capacity
- ALM-38002 Kafka Heap Memory Usage Exceeds the Threshold
- ALM-38004 Kafka Direct Memory Usage Exceeds the Threshold
- ALM-38005 GC Duration of the Broker Process Exceeds the Threshold
- ALM-38006 Percentage of Kafka Partitions That Are Not Completely Synchronized Exceeds the Threshold
- ALM-38007 Status of Kafka Default User Is Abnormal
- ALM-38008 Abnormal Kafka Data Directory Status
- ALM-38009 Busy Broker Disk I/Os (Applicable to Versions Later Than MRS 3.1.0)
- ALM-38009 Kafka Topic Overload (Applicable to MRS 3.1.0 and Earlier Versions)
- ALM-38010 Topics with Single Replica
- ALM-38011 User Connection Usage on Broker Exceeds the Threshold
- ALM-43001 Spark2x Service Unavailable
- ALM-43006 Heap Memory Usage of the JobHistory2x Process Exceeds the Threshold
- ALM-43007 Non-Heap Memory Usage of the JobHistory2x Process Exceeds the Threshold
- ALM-43008 The Direct Memory Usage of the JobHistory2x Process Exceeds the Threshold
- ALM-43009 JobHistory2x Process GC Time Exceeds the Threshold
- ALM-43010 Heap Memory Usage of the JDBCServer2x Process Exceeds the Threshold
- ALM-43011 Non-Heap Memory Usage of the JDBCServer2x Process Exceeds the Threshold
- ALM-43012 Direct Heap Memory Usage of the JDBCServer2x Process Exceeds the Threshold
- ALM-43013 JDBCServer2x Process GC Time Exceeds the Threshold
- ALM-43017 JDBCServer2x Process Full GC Number Exceeds the Threshold
- ALM-43018 JobHistory2x Process Full GC Number Exceeds the Threshold
- ALM-43019 Heap Memory Usage of the IndexServer2x Process Exceeds the Threshold
- ALM-43020 Non-Heap Memory Usage of the IndexServer2x Process Exceeds the Threshold
- ALM-43021 Direct Memory Usage of the IndexServer2x Process Exceeds the Threshold
- ALM-43022 IndexServer2x Process GC Time Exceeds the Threshold
- ALM-43023 IndexServer2x Process Full GC Number Exceeds the Threshold
- ALM-44000 Presto Service Unavailable
- ALM-44004 Presto Coordinator Resource Group Queuing Tasks Exceed the Threshold
- ALM-44005 Presto Coordinator Process GC Time Exceeds the Threshold
- ALM-44006 Presto Worker Process GC Time Exceeds the Threshold
- ALM-45000 HetuEngine Service Unavailable
- ALM-45001 Faulty HetuEngine Compute Instances
- ALM-45003 HetuEngine QAS Disk Capacity Is Insufficient
- ALM-45175 Average Time for Calling OBS Metadata APIs Is Greater than the Threshold
- ALM-45176 Success Rate of Calling OBS Metadata APIs Is Lower than the Threshold
- ALM-45177 Success Rate of Calling OBS Data Read APIs Is Lower than the Threshold
- ALM-45178 Success Rate of Calling OBS Data Write APIs Is Lower Than the Threshold
- ALM-45179 Number of Failed OBS readFully API Calls Exceeds the Threshold
- ALM-45180 Number of Failed OBS read API Calls Exceeds the Threshold
- ALM-45181 Number of Failed OBS write API Calls Exceeds the Threshold
- ALM-45182 Number of Throttled OBS Operations Exceeds the Threshold
- ALM-45275 Ranger Service Unavailable
- ALM-45276 Abnormal RangerAdmin Status
- ALM-45277 RangerAdmin Heap Memory Usage Exceeds the Threshold
- ALM-45278 RangerAdmin Direct Memory Usage Exceeds the Threshold
- ALM-45279 RangerAdmin Non Heap Memory Usage Exceeds the Threshold
- ALM-45280 RangerAdmin GC Duration Exceeds the Threshold
- ALM-45281 UserSync Heap Memory Usage Exceeds the Threshold
- ALM-45282 UserSync Direct Memory Usage Exceeds the Threshold
- ALM-45283 UserSync Non Heap Memory Usage Exceeds the Threshold
- ALM-45284 UserSync Garbage Collection (GC) Time Exceeds the Threshold
- ALM-45285 TagSync Heap Memory Usage Exceeds the Threshold
- ALM-45286 TagSync Direct Memory Usage Exceeds the Threshold
- ALM-45287 TagSync Non Heap Memory Usage Exceeds the Threshold
- ALM-45288 TagSync Garbage Collection (GC) Time Exceeds the Threshold
- ALM-45289 PolicySync Heap Memory Usage Exceeds the Threshold
- ALM-45290 PolicySync Direct Memory Usage Exceeds the Threshold
- ALM-45291 PolicySync Non-Heap Memory Usage Exceeds the Threshold
- ALM-45292 PolicySync GC Duration Exceeds the Threshold
- ALM-45325 Presto Service Unavailable
- ALM-45326 Number of Presto Coordinator Threads Exceeds the Threshold
- ALM-45327 Presto Coordinator Process GC Time Exceeds the Threshold
- ALM-45328 Presto Worker Process GC Time Exceeds the Threshold
- ALM-45329 Presto Coordinator Resource Group Queuing Tasks Exceed the Threshold
- ALM-45330 Number of Presto Worker Threads Exceeds the Threshold
- ALM-45331 Number of Presto Worker1 Threads Exceeds the Threshold
- ALM-45332 Number of Presto Worker2 Threads Exceeds the Threshold
- ALM-45333 Number of Presto Worker3 Threads Exceeds the Threshold
- ALM-45334 Number of Presto Worker4 Threads Exceeds the Threshold
- ALM-45335 Presto Worker1 Process GC Time Exceeds the Threshold
- ALM-45336 Presto Worker2 Process GC Time Exceeds the Threshold
- ALM-45337 Presto Worker3 Process GC Time Exceeds the Threshold
- ALM-45338 Presto Worker4 Process GC Time Exceeds the Threshold
- ALM-45425 ClickHouse Service Unavailable
- ALM-45426 ClickHouse Service Quantity Quota Usage in ZooKeeper Exceeds the Threshold
- ALM-45427 ClickHouse Service Capacity Quota Usage in ZooKeeper Exceeds the Threshold
- ALM-45428 ClickHouse Disk I/O Exception
- ALM-45429 Table Metadata Synchronization Failed on the Added ClickHouse Node
- ALM-45430 Permission Metadata Synchronization Failed on the Added ClickHouse Node
- ALM-45431 Improper ClickHouse Instance Distribution for Topology Allocation
- ALM-45432 ClickHouse User Synchronization Process Fails
- ALM-45433 ClickHouse AZ Topology Exception
- ALM-45434 A Single Replica Exists in the ClickHouse Data Table
- ALM-45435 Inconsistent Metadata of ClickHouse Tables
- ALM-45436 Skew ClickHouse Table Data
- ALM-45437 Excessive Parts in the ClickHouse Table
- ALM-45438 ClickHouse Disk Usage Exceeds 80%
- ALM-45439 ClickHouse Node Enters the Read-Only Mode
- ALM-45440 Inconsistency Between ClickHouse Replicas
- ALM-45441 Zookeeper Disconnected
- ALM-45442 Too Many Concurrent SQL Statements
- ALM-45443 Slow SQL Queries in the Cluster
- ALM-45444 Abnormal ClickHouse Process
- ALM-45475 A Single Replica Exists in the Kudu Data Table
- ALM-45476 Kudu Failed to Enter the Maintenance Mode
- ALM-45477 Failed to Restore Data After a Disk of Kudu Is Replaced
- ALM-45478 Kudu Failed Data Balancing
- ALM-45479 Number of Tablets of the Tserver Process Exceeds the Threshold
- ALM-45480 Tablet Leaders of a Tserver Process Are Unevenly Distributed
- ALM-45481 KuduTserver Has Full Disks
- ALM-45585 IoTDB Service Unavailable
- ALM-45586 IoTDBServer Heap Memory Usage Exceeds the Threshold
- ALM-45587 IoTDBServer GC Duration Exceeds the Threshold
- ALM-45588 IoTDBServer Direct Memory Usage Exceeds the Threshold
- ALM-45589 ConfigNode Heap Memory Usage Exceeds the Threshold
- ALM-45590 ConfigNode GC Duration Exceeds the Threshold
- ALM-45591 ConfigNode Direct Memory Usage Exceeds the Threshold
- ALM-45592 IoTDBServer RPC Execution Duration Exceeds the Threshold
- ALM-45593 IoTDBServer Flush Execution Duration Exceeds the Threshold
- ALM-45594 IoTDBServer Intra-Space Merge Duration Exceeds the Threshold
- ALM-45595 IoTDBServer Cross-Space Merge Duration Exceeds the Threshold
- ALM-45596 Procedure Execution Failed
- ALM-45615 CDL Service Unavailable
- ALM-45616 CDL Job Execution Exception
- ALM-45617 Data Queued in the CDL Replication Slot Exceeds the Threshold
- ALM-45635 FlinkServer Job Execution Failure
- ALM-45636 FlinkServer Job Checkpoints Keep Failing
- ALM-45636 Flink Job Checkpoints Keep Failing
- ALM-45637 FlinkServer Task Is Continuously Under Back Pressure
- ALM-45638 Number of Restarts After FlinkServer Job Failures Exceeds the Threshold
- ALM-45638 Number of Restarts After Flink Job Failures Exceeds the Threshold
- ALM-45639 Checkpointing of a Flink Job Times Out
- ALM-45640 FlinkServer Heartbeat Interruption Between the Active and Standby Nodes
- ALM-45641 Data Synchronization Exception Between the Active and Standby FlinkServer Nodes
- ALM-45642 RocksDB Continuously Triggers Write Traffic Limiting
- ALM-45643 MemTable Size of RocksDB Continuously Exceeds the Threshold
- ALM-45644 Number of SST Files at Level 0 of RocksDB Continuously Exceeds the Threshold
- ALM-45645 Pending Flush Size of RocksDB Continuously Exceeds the Threshold
- ALM-45646 Pending Compaction Size of RocksDB Continuously Exceeds the Threshold
- ALM-45647 Estimated Pending Compaction Size of RocksDB Continuously Exceeds the Threshold
- ALM-45648 RocksDB Frequently Encounters Write-Stopped
- ALM-45649 P95 Latency of RocksDB Get Requests Continuously Exceeds the Threshold
- ALM-45650 P95 Latency of RocksDB Write Requests Continuously Exceeds the Threshold
- ALM-45652 Flink Service Unavailable
- ALM-45653 Invalid Flink HA Certificate File
- ALM-45654 Flink HA Certificate Is About to Expire
- ALM-45655 Flink HA Certificate File Has Expired
- ALM-45736 Guardian Service Unavailable
- ALM-45737 TokenServer Heap Memory Usage Exceeds the Threshold
- ALM-45738 TokenServer Direct Memory Usage Exceeds the Threshold
- ALM-45739 TokenServer Non-Heap Memory Usage Exceeds the Threshold
- ALM-45740 TokenServer GC Duration Exceeds the Threshold
- ALM-45741 Failed to Call the ECS securitykey API
- ALM-45742 Failed to Call the ECS Metadata API
- ALM-45743 Failed to Call the IAM API
- ALM-50201 Doris Service Unavailable
- ALM-50202 FE CPU Usage Exceeds the Threshold
- ALM-50203 FE Memory Usage Exceeds the Threshold
- ALM-50205 BE CPU Usage Exceeds the Threshold
- ALM-50206 BE Memory Usage Exceeds the Threshold
- ALM-50207 Ratio of Connections to the FE MySQL Port to the Maximum Connections Allowed Exceeds the Threshold
- ALM-50208 Failures to Clear Historical Metadata Image Files Exceed the Threshold
- ALM-50209 Failures to Generate Metadata Image Files Exceed the Threshold
- ALM-50210 Maximum Compaction Score of All BE Nodes Exceeds the Threshold
- ALM-50211 FE Queue Length of BE Periodic Report Tasks Exceeds the Threshold
- ALM-50212 Accumulated Old-Generation GC Duration of the FE Process Exceeds the Threshold
- ALM-50213 Number of Tasks Queuing in the FE Thread Pool for Interacting with BE Exceeds the Threshold
- ALM-50214 Number of Tasks Queuing in the FE Thread Pool for Task Processing Exceeds the Threshold
- ALM-50215 Longest Duration of RPC Requests Received by Each FE Thrift Method Exceeds the Threshold
- ALM-50216 Memory Usage of the FE Node Exceeds the Threshold
- ALM-50217 Heap Memory Usage of the FE Node Exceeds the Threshold
- ALM-50219 Length of the Queue in the Thread Pool for Query Execution Exceeds the Threshold
- ALM-50220 Error Rate of TCP Packet Receiving Exceeds the Threshold
- ALM-50221 BE Data Disk Usage Exceeds the Threshold
- ALM-50222 Disk Status of a Specified Data Directory on BE Is Abnormal
- ALM-50223 Maximum Memory Required by BE Is Greater Than the Remaining Memory of the Machine
- ALM-50224 Failures a Certain Task Type on BE Are Increasing
- ALM-50225 FE Instance Fault
- ALM-50226 BE Instance Fault
- ALM-50401 Number of JobServer Jobs Waiting to Be Executed Exceeds the Threshold
- ALM-50402 JobGateway Service Unavailable
- Security Description
- High-Risk Operations
- Interconnecting Jupyter Notebook with MRS Using Custom Python
- Appendix
-
Component Operation Guide (Normal)
- Using Alluxio
- Using CarbonData (for Versions Earlier Than MRS 3.x)
-
Using CarbonData (for MRS 3.x or Later)
- CarbonData Data Types
- CarbonData Table User Permissions
- Creating a CarbonData Table Using the Spark Client
- CarbonData Data Analytics
- CarbonData Performance Tuning
- Typical CarbonData Configuration Parameters
- CarbonData Syntax Reference
- CarbonData Troubleshooting
-
CarbonData FAQs
- Why Is Incorrect Output Displayed When I Perform Query with Filter on Decimal Data Type Values?
- How to Avoid Minor Compaction for Historical Data?
- How to Change the Default Group Name for CarbonData Data Loading?
- Why Does INSERT INTO CARBON TABLE Command Fail?
- Why Is the Data Logged in Bad Records Different from the Original Input Data with Escape Characters?
- Why Data Load Performance Decreases due to Bad Records?
- Why INSERT INTO/LOAD DATA Task Distribution Is Incorrect and the Opened Tasks Are Less Than the Available Executors when the Number of Initial ExecutorsIs Zero?
- Why Does CarbonData Require Additional Executors Even Though the Parallelism Is Greater Than the Number of Blocks to Be Processed?
- Why Data loading Fails During off heap?
- Why Do I Fail to Create a Hive Table?
- How Do I Logically Split Data Across Different Namespaces?
- Why Does the Missing Privileges Exception Occur When the Database Is Dropped?
- Why the UPDATE Command Cannot Be Executed in Spark Shell?
- How Do I Configure Unsafe Memory in CarbonData?
- Why Does CarbonData Become Abnormal After the Disk Space Quota of the HDFS Storage Directory Is Set?
- Why Does Data Query or Loading Fail and "org.apache.carbondata.core.memory.MemoryException: Not enough memory" Is Displayed?
- Why Do Files of a Carbon Table Exist in the Recycle Bin Even If the drop table Command Is Not Executed When Mis-deletion Prevention Is Enabled?
-
Using ClickHouse
- ClickHouse Overview
- ClickHouse User Permission Management
- Using the ClickHouse Client
- Creating a ClickHouse Table
- ClickHouse Data Import
- Enterprise-Class Enhancements of ClickHouse
- ClickHouse Performance Tuning
- ClickHouse O&M Management
-
Common ClickHouse SQL Syntax
- CREATE DATABASE: Creating a Database
- CREATE TABLE: Creating a Table
- INSERT INTO: Inserting Data into a Table
- SELECT: Querying Table Data
- ALTER TABLE: Modifying a Table Structure
- ALTER TABLE: Modifying Table Data
- DESC: Querying a Table Structure
- DROP: Deleting a Table
- SHOW: Displaying Information About Databases and Tables
-
ClickHouse FAQ
- How Do I Do If the Disk Status Displayed in the System.disks Table Is fault or abnormal?
- How Do I Migrate Data from Hive/HDFS to ClickHouse?
- An Error Is Reported in Logs When the Auxiliary ZooKeeper or Replica Data Is Used to Synchronize Table Data
- How Do I Grant the Select Permission at the Database Level to ClickHouse Users?
- Using DBService
-
Using Flink
- Flink Job Engine
- Flink User Permission Management
- Using the Flink Client
- Preparing for Creating a FlinkServer Job
- Creating a FlinkServerJob
- Managing FlinkServer Jobs
- Flink O&M Management
- Flink Performance Tuning
- Typical Commands of the Flink Client
- Common Issues About Flink
- Example of Issuing a Certificate
-
Using Flume
- Flume Log Collection Overview
- Flume Service Model Configuration
- Installing the Flume Client
- Quickly Using Flume to Collect Node Logs
-
Configuring a Non-Encrypted Flume Data Collection Task
- Generating Configuration Files for the Flume Server and Client
- Using Flume Server to Collect Static Logs from Local Host to Kafka
- Using Flume Server to Collect Static Logs from Local Host to HDFS
- Using Flume Server to Collect Dynamic Logs from Local Host to HDFS
- Using Flume Server to Collect Logs from Kafka to HDFS
- Using Flume Client to Collect Logs from Kafka to HDFS
- Using Cascaded Agents to Collect Static Logs from Local Host to HBase
- Configuring an Encrypted Flume Data Collection Task
- Enterprise-Class Enhancements of Flume
- Flume O&M Management
- Common Issues About Flume
-
Using HBase
- Creating HBase Roles
- Using the HBase Client
- Quickly Using HBase for Offline Data Analysis
- Migrating Data to HBase Using BulkLoad
- HBase Data Operations
- Enterprise-Class Enhancements of HBase
- HBase Performance Tuning
- HBase O&M Management
-
Common Issues About HBase
- Operation Failures Occur in Stopping BulkLoad On the Client
- How Do I Restore a Region in the RIT State for a Long Time?
- What Should I Do If HMaster Exits Due to Timeout When Waiting for the Namespace Table to Go Online?
- Why Does SocketTimeoutException Occur When a Client Queries HBase?
- What Should I Do If Error Message "java.lang.UnsatisfiedLinkError: Permission denied" Is Displayed When I Start the HBase Shell?
- When Will the" Dead Region Servers" Information Displayed on the HMaster Web UI Be Cleared After a RegionServer Is Stopped?
- What Can I Do If a Message Indicating Insufficient Permission Is Displayed When I Access HBase Phoenix?
- How Do I Restore an HBase Region in Overlap State?
- Phoenix BulkLoad Use Restrictions
- Why a Message Is Displayed Indicating that the Permission is Insufficient When CTBase Connects to the Ranger Plug-ins?
-
HBase Troubleshooting
- The HBase Client Failed to Connect to the Server for a Long Time
- An Exception Occurred When HBase Deletes and Creates a Table Consecutively
- Other Services Are Unstable When Too Many HBase Connections Occupy the Network Ports
- HBase BulkLoad Tasks of 210,000 Map Tasks and 10,000 Reduce Tasks failed To Be Executed
- Modified and Deleted Data Can Still Be Queried by the Scan Command
- Failed to Create Tables When the Region is in FAILED_OPEN State
- How to Delete the residual Table Name on the ZooKeeper table-lock Node After a Table Creation Failure
- HBase Become Faulty When I Set a Quota for the Directory Used by HBase in HDFS
- HMaster Failed to Be Started After the OfflineMetaRepair Tool Is Used to Rebuild Metadata
- FileNotFoundException Is Frequently Printed in HMaster Logs
- Data Is Successfully Imported Using HBase BulkLoad, but Different Results May Be Returned To the Same Query
- HBase Data Restoration Task Failed to Be Rolled Back
- RegionServer Failed to Be Started When GC Parameters Xms and Xmx of HBase RegionServer Are Set to 31 GB
- When LoadIncrementalHFiles Is Used to Import Data in Batches on Cluster Nodes, the Insufficient Permission Error Is Reported
- "import argparse" Is Reported When the Phoenix Sqlline Script Is Used
-
Using HDFS
- Overview of HDFS File System Directories
- HDFS User Permission Management
- Using the HDFS Client
- Using Hadoop
- Configuring the Recycle Bin Mechanism
- Configuring HDFS DataNode Data Balancing
- Configuring HDFS Disk Balancing
- Using HDFS Mover to Migrate Data
- Configuring the Label Policy (NodeLabel) for HDFS File Directories
- Configuring NameNode Memory Parameters
- Setting the Number Limit of HBase and HDFS Handles
- Configuring the Number of Files in a Single HDFS Directory
- Enterprise-Class Enhancements of HDFS
-
HDFS Performance Tuning
- Improving HDFS Write Performance
- Improving Read Performance By HDFS Client Metadata Caching
- Improving the HDFS Client Connection Performance with Active NameNode Caching
- Optimization for Unstable HDFS Network
- Optimizing HDFS NameNode RPC QoS
- Optimizing HDFS DataNode RPC QoS
- Performing Concurrent Operations on HDFS Files
- Using the LZC Compression Algorithm to Store HDFS Files
-
HDFS O&M Management
- HDFS Common Configuration Parameters
- HDFS Log Overview
- Viewing the HDFS Capacity
- Changing the DataNode Storage Directory
- Adjusting Parameters Related to Damaged DataNode Disk Volumes
- Configuring the Maximum Lifetime of an HDFS Token
- Using DistCp to Copy HDFS Data Across Clusters
- Configuring the NFS Server to Store NameNode Metadata
-
Common Issues About HDFS
- What Should I Do If an Error Is Reported When I Run DistCp Commands?
- When Does a Balance Process in HDFS, Shut Down and Fail to be Executed Again?
- "This page can't be displayed" Is Displayed When Internet Explorer Fails to Access the Native HDFS UI
- What Should I Do If the HDFS Web UI Cannot Update the Information About the Damaged Data?
- What Should I Do If the HDFS Client Is Irresponsive When the NameNode Is Overloaded for a Long Time?
- Why are There Two Standby NameNodes After the active NameNode Is Restarted?
- Why Does DataNode Fail to Report Data Blocks?
- Can I Modify the DataNode Data Storage Directory?
- What Can I Do If the DataNode Capacity Is Incorrectly Calculated?
- Why Is Data in the Cache Lost When Small Files Are Stored?
- Why Is the Storage Type of File Copies DISK When the Tiered Storage Policy Is LAZY_PERSIST?
- Why Some Blocks Are Missing on the NameNode UI?
-
HDFS Troubleshooting
- Why Is "java.net.SocketException" Reported When Data Is Written to HDFS
- It Takes a Long Time to Restart NameNode After a Large Number of Files Are Deleted
- NameNode Fails to Be Restarted Due to EditLog Discontinuity
- The standby NameNode Fails to Be Started After It Is Powered Off During Metadata Storage
- DataNode Fails to Be Started When the Number of Disks Defined in dfs.datanode.data.dir Equals the Value of dfs.datanode.failed.volumes.tolerated
- "ArrayIndexOutOfBoundsException: 0" Occurs When HDFS Invokes getsplit of FileInputFormat
-
Using Hive
- Hive User Permission Management
- Using the Hive Client
- Using Hive for Data Analysis
- Configuring Hive Data Storage and Encryption
- Hive on HBase
- Using Hive to Read Data in a Relational Database
-
Enterprise-Class Enhancement of Hive
- Configuring Automatic Removal of Old Data in the Hive Directory to the Recycle Bin
- Configuring Hive to Insert Data to a Directory That Does Not Exist
- Forbidding Location Specification When Hive Internal Tables Are Created
- Creating a Foreign Table in a Directory (Read and Execute Permission Granted)
- Configuring HTTPS/HTTP-based REST APIs
- Configuring Hive Transform
- Switching the Hive Execution Engine to Tez
- Hive Load Balancing
- Configuring Access Control Permission for the Dynamic View of a Hive Single Table
- Allowing Users without ADMIN Permission to Create Temporary Functions
- Allowing Users with Select Permission to View the Table Structure
- Allowing Only the Hive Administrator to Create Databases and Tables in the Default Database
- Configuring Hive to Support More Than 32 Roles
- Creating User-Defined Hive Functions
- Configuring High Reliability for Hive Beeline
- Hive Performance Tuning
- Hive O&M Management
- Common Hive SQL Syntax
-
Common Issues About Hive
- How Do I Delete All Permanent Functions from HiveServer?
- Why Cannot the DROP Operation Be Performed on a Backed Up Hive Table?
- How to Perform Operations on Local Files with Hive User-Defined Functions
- How Do I Forcibly Stop MapReduce Jobs Executed by Hive?
- What Are the Special Characters Not Supported by Hive in Complex Field Names?
- How Do I Monitor the Hive Table Size?
- How Do I Prevent Data Loss Caused by Misoperations of the insert overwrite Statement?
- How Do I Handle a Slow Hive on Spark Task When HBase Is Not Installed?
- What Should I Do If an Error Is Reported When the WHERE Condition Is Used to Query Tables with Excessive Partitions in Hive?
- Why Cannot I Connect to HiveServer When I Use IBM JDK to Access the Beeline Client?
- Does the Location of a Hive Table Support Cross-OBS and Cross-HDFS Paths?
- What Should I Do If the MapReduce Engine Cannot Query the Data Written by the Union Statement Running on Tez?
- Does Hive Support Concurrent Data Writing to the Same Table or Partition?
- Does Hive Support Vectorized Query?
- What Should I Do If the Task Fails When the HDFS Data Directory of the Hive Table Is Deleted By Mistake, But The Metadata Still Exists?
- How Do I Disable the Logging Function of Hive?
- Why Is the OBS Quick Deletion Directory Not Applied After Being Added to the Custom Hive Configuration?
- Hive Configuration Problems
- Hive Troubleshooting
-
Using Hudi
- Hudi Table Overview
- Creating a Hudi Table Using Spark Shell
- Operating a Hudi Table Using hudi-cli.sh
- Hudi Write Operation
- Hudi Read Operation
- Data Management and Maintenance
- Typical Hudi Configuration Parameters
- Hudi Performance Tuning
-
Common Issues About Hudi
-
Data Write
- Parquet/Avro schema Is Reported When Updated Data Is Written
- UnsupportedOperationException Is Reported When Updated Data Is Written
- SchemaCompatabilityException Is Reported When Updated Data Is Written
- What Should I Do If Hudi Consumes Much Space in a Temporary Folder During Upsert?
- Hudi Fails to Write Decimal Data with Lower Precision
- Data Collection
- Hive Synchronization
-
Data Write
- Using Hue (Versions Earlier Than MRS 3.x)
-
Using Hue (MRS 3.x or Later)
- Accessing the Hue Web UI
- Using Hue WebUI to Operate Hive Tables
- Creating a Hue Job
- Typical Application Scenarios of the Hue Web UI
- Typical Hue Configurations
- Hue Log Overview
-
Common Issues About Hue
- Why Do HQL Statements Fail to Execute in Hue Using Internet Explorer?
- Why Does the use database Statement Become Invalid in Hive?
- Why Do HDFS Files Fail to Access Through the Hue Web UI?
- Why Do Large Files Fail to Upload on the Hue Page
- Why Is the Hue Native Page Cannot Be Properly Displayed If the Hive Service Is Not Installed in a Cluster?
- What Should I Do If It Takes a Long Time to Access the Native Hue UI and the File Browser Reports "Read timed out"?
- Using Impala
-
Using Kafka
- Kafka Data Consumption
- Kafka User Permission Management
- Using the Kafka Client
- Quickly Using Kafka to Produce and Consume Data
- Creating a Kafka Topic
- Checking the Consumption Information of Kafka Topics
- Managing Kafka Topics
- Enterprise-Class Enhancements of Kafka
- Kafka Performance Tuning
- Kafka O&M Management
- Common Issues About Kafka
- Using KafkaManager
-
Using Loader
- Using Loader from Scratch
- How to Use Loader
- Common Loader Parameters
- Creating a Loader Role
- Loader Link Configuration
- Managing Loader Links (Versions Earlier Than MRS 3.x)
- Managing Loader Links (MRS 3.x and Later Versions)
- Source Link Configurations of Loader Jobs
- Destination Link Configurations of Loader Jobs
- Managing Loader Jobs
- Preparing a Driver for MySQL Database Link
-
Importing Data
- Overview
- Importing Data Using Loader
- Typical Scenario: Importing Data from an SFTP Server to HDFS or OBS
- Typical Scenario: Importing Data from an SFTP Server to HBase
- Typical Scenario: Importing Data from an SFTP Server to Hive
- Typical Scenario: Importing Data from an FTP Server to HBase
- Typical Scenario: Importing Data from a Relational Database to HDFS or OBS
- Typical Scenario: Importing Data from a Relational Database to HBase
- Typical Scenario: Importing Data from a Relational Database to Hive
- Typical Scenario: Importing Data from HDFS or OBS to HBase
- Typical Scenario: Importing Data from a Relational Database to ClickHouse
- Typical Scenario: Importing Data from HDFS to ClickHouse
-
Exporting Data
- Overview
- Using Loader to Export Data
- Typical Scenario: Exporting Data from HDFS or OBS to an SFTP Server
- Typical Scenario: Exporting Data from HBase to an SFTP Server
- Typical Scenario: Exporting Data from Hive to an SFTP Server
- Typical Scenario: Exporting Data from HDFS or OBS to a Relational Database
- Typical Scenario: Exporting Data from HBase to a Relational Database
- Typical Scenario: Exporting Data from Hive to a Relational Database
- Typical Scenario: Importing Data from HBase to HDFS or OBS
- Managing Jobs
- Operator Help
-
Client Tools
- Running a Loader Job by Using Commands
- loader-tool Usage Guide
- loader-tool Usage Example
- schedule-tool Usage Guide
- schedule-tool Usage Example
- Using loader-backup to Back Up Job Data
- Open Source sqoop-shell Tool Usage Guide
- Example for Using the Open-Source sqoop-shell Tool (SFTP-HDFS)
- Example for Using the Open-Source sqoop-shell Tool (Oracle-HBase)
- Loader Log Overview
- Example: Using Loader to Import Data from OBS to HDFS
- Common Issues About Loader
- Using Kudu
-
Using MapReduce
- Configuring the Distributed Cache to Execute MapReduce Jobs
- Configuring the MapReduce Shuffle Address
- Configuring the MapReduce Cluster Administrator List
- Submitting a MapReduce Task on Windows
- Configuring the Archiving and Clearing Mechanism for MapReduce Task Logs
-
MapReduce Performance Tuning
- MapReduce Optimization Configuration for Multiple CPU Cores
- Configuring the Baseline Parameters for MapReduce Jobs
- MapReduce Shuffle Tuning
- AM Optimization for Big MapReduce Tasks
- Configuring Speculative Execution for MapReduce Tasks
- Tuning MapReduce Tasks Using Slow Start
- Optimizing the Commit Phase of MapReduce Tasks
- Improving MapReduce Client Task Reliability
- MapReduce Log Overview
-
Common Issues About MapReduce
- How Do I Handle the Problem that MapReduce Task Has No Progress for a Long Time?
- Why Is the Client Unavailable When a Task Is Running?
- What Should I Do If HDFS_DELEGATION_TOKEN Cannot Be Found in the Cache?
- How Do I Set the Task Priority When Submitting a MapReduce Task?
- Why Physical Memory Overflow Occurs If a MapReduce Task Fails?
- What Should I Do If MapReduce Job Information Cannot Be Opened Through Tracking URL on the ResourceManager Web UI?
- Why MapReduce Tasks Fails in the Environment with Multiple NameServices?
- What Should I Do If the Partition-based Task Blacklist Is Abnormal?
- Using OpenTSDB
-
Using Oozie
- Using Oozie Client to Submit an Oozie Job
-
Using Hue to Submit an Oozie Job
- Creating a Workflow Using Hue
- Submitting an Oozie Hive2 Job Using Hue
- Submitting an Oozie HQL Script Using Hue
- Submitting an Oozie Spark2x Job Using Hue
- Submitting an Oozie Java Job Using Hue
- Submitting an Oozie Loader Job Using Hue
- Submitting an Oozie MapReduce Job Using Hue
- Submitting an Oozie Sub Workflow Job Using Hue
- Submitting an Oozie Shell Job Using Hue
- Submitting an Oozie HDFS Job Using Hue
- Submitting an Oozie Streaming Job Using Hue
- Submitting an Oozie Distcp Job Using Hue
- Submitting an Oozie SSH Job Using Hue
- Submitting a Coordinator Periodic Scheduling Job Using Hue
- Submitting a Bundle Batch Processing Job Using Hue
- Querying Oozie Job Results on the Hue Web UI
- Configuring Mutual Trust Between Oozie Nodes
- Enabling Oozie High Availability (HA)
- Oozie Log Overview
- Common Issues About Oozie
- Using Presto
- Using Ranger (MRS 1.9.2)
-
Using Ranger (MRS 3.x)
- Logging In to the Ranger Web UI
- Enabling Ranger Authentication for MRS Cluster Services
- Adding a Ranger Permission Policy
-
Configuration Examples for Ranger Permission Policy
- Adding a Ranger Access Permission Policy for HDFS
- Adding a Ranger Access Permission Policy for HBase
- Adding a Ranger Access Permission Policy for Hive
- Adding a Ranger Access Permission Policy for Impala
- Adding a Ranger Access Permission Policy for Yarn
- Adding a Ranger Access Permission Policy for Spark2x
- Adding a Ranger Access Permission Policy for Kafka
- Adding a Ranger Access Permission Policy for Storm
- Viewing Ranger Audit Information
- Configuring Ranger Security Zone
- Changing the Ranger Data Source to LDAP for a Normal Cluster
- Viewing Ranger User Permission Synchronization Information
- Ranger Log Overview
-
Common Issues About Ranger
- Why Ranger Startup Fails During the Cluster Installation?
- How Do I Determine Whether the Ranger Authentication Is Used for a Service?
- Why Cannot a New User Log In to Ranger After Changing the Password?
- When an HBase Policy Is Added or Modified on Ranger, Wildcard Characters Cannot Be Used to Search for Existing HBase Tables
- Why Can't I View the Created MRS User on the Ranger Management Page?
- What Should I Do If MRS Users Failed to Be Synchronized to the Ranger Web UI?
- Using Spark (for Versions Earlier Than MRS 3.x)
-
Using Spark2x (for MRS 3.x or Later)
- Spark User Permission Management
- Using the Spark Client
- Configuring Spark to Read HBase Data
- Configuring Spark Tasks Not to Obtain HBase Token Information
- Spark Core Enterprise-Class Enhancements
- Spark SQL Enterprise-Class Enhancements
- Spark Streaming Enterprise-Class Enhancements
-
Spark Core Performance Tuning
- Spark Core Data Serialization
- Spark Core Memory Tuning
- Spark Core Memory Tuning
- Configuring Spark Core Broadcasting Variables
- Configuring Heap Memory Parameters for Spark Executor
- Using the External Shuffle Service to Improve Spark Core Performance
- Configuring Spark Dynamic Resource Scheduling in YARN Mode
- Adjusting Spark Core Process Parameters
- Spark DAG Design Specifications
- Experience
-
Spark SQL Performance Tuning
- Optimizing the Spark SQL Join Operation
- Improving Spark SQL Calculation Performance Under Data Skew
- Optimizing Spark SQL Performance in the Small File Scenario
- Optimizing the Spark INSERT SELECT Statement
- Optimizing Memory when Data Is Inserted into Dynamic Partitioned Tables
- Optimizing Small Files
- Optimizing the Aggregate Algorithms
- Optimizing Datasource Tables
- Merging CBO
- SQL Optimization for Multi-level Nesting and Hybrid Join
- Spark Streaming Performance Tuning
-
Spark O&M Management
- Configuring Parameters Rapidly
- Common Parameters
- Spark2x Logs
- Changing Spark Log Levels
- Viewing Container Logs on the Web UI
- Obtaining Container Logs of a Running Spark Application
- Configuring Spark Event Log Rollback
- Configuring the Number of Lost Executors Displayed in WebUI
- Configuring Local Disk Cache for JobHistory
- Enhancing Stability in a Limited Memory Condition
- Configuring Environment Variables in Yarn-Client and Yarn-Cluster Modes
- Broaden Support for Hive Partition Pruning Predicate Pushdown
- Configuring the Column Statistics Histogram to Enhance the CBO Accuracy
- Using CarbonData for First Query
-
Common Issues About Spark2x
-
Spark Core
- How Do I View Aggregated Spark Application Logs?
- Why Is the Return Code of Driver Inconsistent with Application State Displayed on ResourceManager WebUI?
- Why Cannot Exit the Driver Process?
- Why Does FetchFailedException Occur When the Network Connection Is Timed out
- How to Configure Event Queue Size If Event Queue Overflows?
- What Can I Do If the getApplicationReport Exception Is Recorded in Logs During Spark Application Execution and the Application Does Not Exit for a Long Time?
- What Can I Do If "Connection to ip:port has been quiet for xxx ms while there are outstanding requests" Is Reported When Spark Executes an Application and the Application Ends?
- Why Do Executors Fail to be Removed After the NodeManeger Is Shut Down?
- What Can I Do If the Message "Password cannot be null if SASL is enabled" Is Displayed?
- "Failed to CREATE_FILE" Is Displayed When Data Is Inserted into the Dynamic Partitioned Table Again
- Why Tasks Fail When Hash Shuffle Is Used?
- What Can I Do If the Error Message "DNS query failed" Is Displayed When I Access the Aggregated Logs Page of Spark Applications?
- What Can I Do If Shuffle Fetch Fails Due to the "Timeout Waiting for Task" Exception?
- Why Does the Stage Retry due to the Crash of the Executor?
- Why Do the Executors Fail to Register Shuffle Services During the Shuffle of a Large Amount of Data?
- NodeManager OOM Occurs During Spark Application Execution
- Why Does the Realm Information Fail to Be Obtained When SparkBench is Run on HiBench for the Cluster in Security Mode?
-
Spark SQL and DataFrame
- What Do I have to Note When Using Spark SQL ROLLUP and CUBE?
- Why Spark SQL Is Displayed as a Temporary Table in Different Databases?
- How to Assign a Parameter Value in a Spark Command?
- What Directory Permissions Do I Need to Create a Table Using SparkSQL?
- Why Do I Fail to Delete the UDF Using Another Service?
- Why Cannot I Query Newly Inserted Data in a Parquet Hive Table Using SparkSQL?
- How to Use Cache Table?
- Why Are Some Partitions Empty During Repartition?
- Why Does 16 Terabytes of Text Data Fails to Be Converted into 4 Terabytes of Parquet Data?
- How Do I Rectify the Exception Occurred When I Perform an Operation on the Table Named table?
- Why Is a Task Suspended When the ANALYZE TABLE Statement Is Executed and Resources Are Insufficient?
- If I Access a parquet Table on Which I Do not Have Permission, Why a Job Is Run Before "Missing Privileges" Is Displayed?
- Why Do I Fail to Modify MetaData by Running the Hive Command?
- Why Is "RejectedExecutionException" Displayed When I Exit Spark SQL?
- How Do I Do If I Incidentally Kill the JDBCServer Process During Health Check?
- Why No Result Is found When 2016-6-30 Is Set in the Date Field as the Filter Condition?
- Why Does the --hivevar Option I Specified in the Command for Starting spark-beeline Fail to Take Effect?
- Why Is the "Code of method ... grows beyond 64 KB" Error Message Displayed When I Run Complex SQL Statements?
- Why Is Memory Insufficient if 10 Terabytes of TPCDS Test Suites Are Consecutively Run in Beeline/JDBCServer Mode?
- Why Functions Cannot Be Used When Different JDBCServers Are Connected?
- Why Does an Exception Occur When I Drop Functions Created Using the Add Jar Statement?
- Why Does Spark2x Have No Access to DataSource Tables Created by Spark1.5?
- Why Cannot I Query Newly Inserted Data in an ORC Hive Table Using Spark SQL?
-
Spark Streaming
- Same DAG Log Is Recorded Twice for a Streaming Task
- What Can I Do If Spark Streaming Tasks Are Blocked?
- What Should I Pay Attention to When Optimizing Spark Streaming Task Parameters?
- Why Does the Spark Streaming Application Fail to Be Submitted After the Token Validity Period Expires?
- Why Does the Spark Streaming Application Fail to Be Started from the Checkpoint When the Input Stream Has No Output Logic?
- Why Is the Input Size Corresponding to Batch Time on the Web UI Set to 0 Records When Kafka Is Restarted During Spark Streaming Running?
- Why the Job Information Obtained from the restful Interface of an Ended Spark Application Is Incorrect?
- Why Cannot I Switch from the Yarn Web UI to the Spark Web UI?
- What Can I Do If an Error Occurs when I Access the Application Page Because the Application Cached by HistoryServer Is Recycled?
- Why Is not an Application Displayed When I Run the Application with the Empty Part File?
- Why Does Spark2x Fail to Export a Table with the Same Field Name?
- Why JRE fatal error after running Spark application multiple times?
- Native Spark2x UI Fails to Be Accessed or Is Incorrectly Displayed when Internet Explorer Is Used for Access
- How Does Spark2x Access External Cluster Components?
- Why Does the Foreign Table Query Fail When Multiple Foreign Tables Are Created in the Same Directory?
- Why Is the Native Page of an Application in Spark2x JobHistory Displayed Incorrectly?
- Why Do I Fail to Create a Table in the Specified Location on OBS After Logging to spark-beeline?
- Spark Shuffle Exception Handling
-
Spark Core
-
Using Sqoop
- Using Sqoop from Scratch
- Adapting Sqoop 1.4.7 to MRS 3.x Clusters
- Common Sqoop Commands and Parameters
-
Common Issues About Sqoop
- What Should I Do If Class QueryProvider Is Unavailable?
- What Should I Do If Method getHiveClient Does Not Exist?
- How Do I Do If PostgreSQL or GaussDB Fails to Connect?
- What Should I Do If Data Failed to Be Synchronized to a Hive Table on the OBS Using hive-table?
- What Should I Do If Data Failed to Be Synchronized to an ORC or Parquet Table Using hive-table?
- What Should I Do If Data Failed to Be Synchronized Using hive-table?
- What Should I Do If Data Failed to Be Synchronized to a Hive Parquet Table Using HCatalog?
- What Should I Do If the Data Type of Fields timestamp and data Is Incorrect During Data Synchronization Between Hive and MySQL?
-
Using Storm
- Using Storm from Scratch
- Using the Storm Client
- Submitting Storm Topologies on the Client
- Accessing the Storm Web UI
- Managing Storm Topologies
- Querying Storm Topology Logs
- Storm Common Parameters
- Configuring a Storm Service User Password Policy
- Migrating Storm Services to Flink
- Storm Log Introduction
- Performance Tuning
- Using Tez
-
Using YARN
- YARN User Permission Management
- Submitting a Task Using the Yarn Client
- Configuring Container Log Aggregation
- Enabling Yarn CGroups to Limit the Container CPU Usage
-
Enterprise-Class Enhancement of YARN
- Configuring the Yarn Permission Control
- Specifying the User Who Runs Yarn Tasks
- Configuring the Number of ApplicationMaster Retries
- Configure the ApplicationMaster to Automatically Adjust the Allocated Memory
- Configuring ApplicationMaster Work Preserving
- Configuring the Access Channel Protocol
- Configuring the Additional Scheduler WebUI
- Configuring Resources for a NodeManager Role Instance
- Configuring Yarn Restart
- Yarn Performance Tuning
- YARN O&M Management
-
Common Issues About Yarn
- Why Mounted Directory for Container is Not Cleared After the Completion of the Job While Using CGroups?
- Why the Job Fails with HDFS_DELEGATION_TOKEN Expired Exception?
- Why Are Local Logs Not Deleted After YARN Is Restarted?
- Why the Task Does Not Fail Even Though AppAttempts Restarts for More Than Two Times?
- Why Is an Application Moved Back to the Original Queue After ResourceManager Restarts?
- Why Does Yarn Not Release the Blacklist Even All Nodes Are Added to the Blacklist?
- Why Does the Switchover of ResourceManager Occur Continuously?
- Why Does a New Application Fail If a NodeManager Has Been in Unhealthy Status for 10 Minutes?
- Why Does an Error Occur When I Query the ApplicationID of a Completed or Non-existing Application Using the RESTful APIs?
- Why May A Single NodeManager Fault Cause MapReduce Task Failures in the Superior Scheduling Mode?
- Why Are Applications Suspended After They Are Moved From Lost_and_Found Queue to Another Queue?
- How Do I Limit the Size of Application Diagnostic Messages Stored in the ZKstore?
- Why Does a MapReduce Job Fail to Run When a Non-ViewFS File System Is Configured as ViewFS?
- Why Do Reduce Tasks Fail to Run in Some OSs After the Native Task Feature is Enabled?
-
Using ZooKeeper
- Using ZooKeeper from Scratch
- Configuring the ZooKeeper Permissions
- Common ZooKeeper Parameters
- ZooKeeper Log Overview
-
Common Issues About ZooKeeper
- Why Do ZooKeeper Servers Fail to Start After Many znodes Are Created?
- Why Does the ZooKeeper Server Display the java.io.IOException: Len Error Log?
- Why Four Letter Commands Don't Work With Linux netcat Command When Secure Netty Configurations Are Enabled at Zookeeper Server?
- How Do I Check Which ZooKeeper Instance Is a Leader?
- Why Cannot the Client Connect to ZooKeeper using the IBM JDK?
- What Should I Do When the ZooKeeper Client Fails to Refresh a TGT?
- Why Is Message "Node does not exist" Displayed when A Large Number of Znodes Are Deleted Using the deleteallCommand
- Appendix
-
Component Operation Guide (LTS)
-
Using CarbonData
- Overview
- Configuration Reference
- CarbonData Operation Guide
- CarbonData Performance Tuning
- CarbonData Access Control
- CarbonData Syntax Reference
- CarbonData Troubleshooting
-
CarbonData FAQ
- Why Is Incorrect Output Displayed When I Perform Query with Filter on Decimal Data Type Values?
- How to Avoid Minor Compaction for Historical Data?
- How to Change the Default Group Name for CarbonData Data Loading?
- Why Does INSERT INTO CARBON TABLE Command Fail?
- Why Is the Data Logged in Bad Records Different from the Original Input Data with Escape Characters?
- Why Data Load Performance Decreases due to Bad Records?
- Why INSERT INTO/LOAD DATA Task Distribution Is Incorrect and the Opened Tasks Are Less Than the Available Executors when the Number of Initial Executors Is Zero?
- Why Does CarbonData Require Additional Executors Even Though the Parallelism Is Greater Than the Number of Blocks to Be Processed?
- Why Data loading Fails During off heap?
- Why Do I Fail to Create a Hive Table?
- Why CarbonData tables created in V100R002C50RC1 not reflecting the privileges provided in Hive Privileges for non-owner?
- How Do I Logically Split Data Across Different Namespaces?
- Why Missing Privileges Exception is Reported When I Perform Drop Operation on Databases?
- Why the UPDATE Command Cannot Be Executed in Spark Shell?
- How Do I Configure Unsafe Memory in CarbonData?
- Why Exception Occurs in CarbonData When Disk Space Quota is Set for Storage Directory in HDFS?
- Why Does Data Query or Loading Fail and "org.apache.carbondata.core.memory.MemoryException: Not enough memory" Is Displayed?
-
Using ClickHouse
- Using ClickHouse from Scratch
-
Common ClickHouse SQL Syntax
- CREATE DATABASE: Creating a Database
- CREATE TABLE: Creating a Table
- INSERT INTO: Inserting Data into a Table
- SELECT: Querying Table Data
- ALTER TABLE: Modifying a Table Structure
- DESC: Querying a Table Structure
- DROP: Deleting a Table
- SHOW: Displaying Information About Databases and Tables
- Importing and Exporting File Data
- User Management and Authentication
- ClickHouse Table Engine Overview
- Creating a ClickHouse Table
- Using the ClickHouse Data Migration Tool
- Monitoring of Slow ClickHouse Query Statements and Replication Table Data Synchronization
- Adaptive MV Usage in ClickHouse
- Enabling the mysql_port Configuration for ClickHouse
- ClickHouse Log Overview
- Using DBService
-
Using Flink
- Using Flink from Scratch
- Viewing Flink Job Information
- Flink Configuration Management
- Security Configuration
- Security Hardening
- Security Statement
-
Using the Flink Web UI
- Overview
- FlinkServer Permissions Management
- Accessing the Flink Web UI
- Creating an Application on the Flink Web UI
- Creating a Cluster Connection on the Flink Web UI
- Creating a Data Connection on the Flink Web UI
- Managing Tables on the Flink Web UI
- Managing Jobs on the Flink Web UI
- Managing UDFs on the Flink Web UI
- Interconnecting FlinkServer with External Components
- Deleting Residual Information About Flink Tasks
- Flink Log Overview
- Flink Performance Tuning
- Common Flink Shell Commands
-
Using Flume
- Using Flume from Scratch
- Overview
- Installing the Flume Client on Clusters
- Viewing Flume Client Logs
- Stopping or Uninstalling the Flume Client
- Using the Encryption Tool of the Flume Client
- Flume Service Configuration Guide
- Flume Configuration Parameter Description
- Using Environment Variables in the properties.properties File
-
Non-Encrypted Transmission
- Configuring Non-encrypted Transmission
- Typical Scenario: Collecting Local Static Logs and Uploading Them to Kafka
- Typical Scenario: Collecting Local Static Logs and Uploading Them to HDFS
- Typical Scenario: Collecting Local Dynamic Logs and Uploading Them to HDFS
- Typical Scenario: Collecting Logs from Kafka and Uploading Them to HDFS
- Typical Scenario: Collecting Logs from Kafka and Uploading Them to HDFS Through the Flume Client
- Typical Scenario: Collecting Local Static Logs and Uploading Them to HBase
- Encrypted Transmission
- Viewing Flume Client Monitoring Information
- Connecting Flume to Kafka in Security Mode
- Connecting Flume with Hive in Security Mode
- Configuring the Flume Service Model
- Introduction to Flume Logs
- Flume Client Cgroup Usage Guide
- Secondary Development Guide for Flume Third-Party Plug-ins
- Configuring the Flume Customized Script
- Common Issues About Flume
-
Using HBase
- Using HBase from Scratch
- Creating HBase Roles
- Using an HBase Client
- Configuring HBase Replication
- Enabling Cross-Cluster Copy
- Supporting Full-Text Index
- Using the ReplicationSyncUp Tool
- GeoMesa Command Line
- Using HIndex
- Configuring HBase DR
- Performing an HBase DR Service Switchover
- Configuring HBase Data Compression and Encoding
- Performing an HBase DR Active/Standby Cluster Switchover
- Community BulkLoad Tool
- In-House Enhanced BulkLoad Tool
- Configuring the MOB
- Configuring Secure HBase Replication
- Configuring Region In Transition Recovery Chore Service
- Using a Secondary Index
- HBase Log Overview
- HBase Performance Tuning
-
Common Issues About HBase
- Why Does a Client Keep Failing to Connect to a Server for a Long Time?
- Operation Failures Occur in Stopping BulkLoad On the Client
- Why May a Table Creation Exception Occur When HBase Deletes or Creates the Same Table Consecutively?
- Why Other Services Become Unstable If HBase Sets up A Large Number of Connections over the Network Port?
- Why Does the HBase BulkLoad Task (One Table Has 26 TB Data) Consisting of 210,000 Map Tasks and 10,000 Reduce Tasks Fail?
- How Do I Restore a Region in the RIT State for a Long Time?
- Why Does HMaster Exits Due to Timeout When Waiting for the Namespace Table to Go Online?
- Why Does SocketTimeoutException Occur When a Client Queries HBase?
- Why Modified and Deleted Data Can Still Be Queried by Using the Scan Command?
- Why "java.lang.UnsatisfiedLinkError: Permission denied" exception thrown while starting HBase shell?
- When does the RegionServers listed under "Dead Region Servers" on HMaster WebUI gets cleared?
- Why Are Different Query Results Returned After I Use Same Query Criteria to Query Data Successfully Imported by HBase bulkload?
- What Should I Do If I Fail to Create Tables Due to the FAILED_OPEN State of Regions?
- How Do I Delete Residual Table Names in the /hbase/table-lock Directory of ZooKeeper?
- Why Does HBase Become Faulty When I Set a Quota for the Directory Used by HBase in HDFS?
- Why HMaster Times Out While Waiting for Namespace Table to be Assigned After Rebuilding Meta Using OfflineMetaRepair Tool and Startups Failed
- Why Messages Containing FileNotFoundException and no lease Are Frequently Displayed in the HMaster Logs During the WAL Splitting Process?
- Why Does the ImportTsv Tool Display "Permission denied" When the Same Linux User as and a Different Kerberos User from the Region Server Are Used?
- Insufficient Rights When a Tenant Accesses Phoenix
- Insufficient Rights When a Tenant Uses the HBase Bulkload Function
- What Can I Do When HBase Fails to Recover a Task and a Message Is Displayed Stating "Rollback recovery failed"?
- How Do I Fix Region Overlapping?
- Why Does RegionServer Fail to Be Started When GC Parameters Xms and Xmx of HBase RegionServer Are Set to 31 GB?
- Why Does the LoadIncrementalHFiles Tool Fail to Be Executed and "Permission denied" Is Displayed When Nodes in a Cluster Are Used to Import Data in Batches?
- Why Is the Error Message "import argparse" Displayed When the Phoenix sqlline Script Is Used?
- How Do I Deal with the Restrictions of the Phoenix BulkLoad Tool?
- Why a Message Is Displayed Indicating that the Permission is Insufficient When CTBase Connects to the Ranger Plug-ins?
-
Using HDFS
- Configuring Memory Management
- Creating an HDFS Role
- Using the HDFS Client
- Running the DistCp Command
- Overview of HDFS File System Directories
- Changing the DataNode Storage Directory
- Configuring HDFS Directory Permission
- Configuring NFS
- Planning HDFS Capacity
- Configuring ulimit for HBase and HDFS
- Balancing DataNode Capacity
- Configuring Replica Replacement Policy for Heterogeneous Capacity Among DataNodes
- Configuring the Number of Files in a Single HDFS Directory
- Configuring the Recycle Bin Mechanism
- Setting Permissions on Files and Directories
- Setting the Maximum Lifetime and Renewal Interval of a Token
- Configuring the Damaged Disk Volume
- Configuring Encrypted Channels
- Reducing the Probability of Abnormal Client Application Operation When the Network Is Not Stable
- Configuring the NameNode Blacklist
- Optimizing HDFS NameNode RPC QoS
- Optimizing HDFS DataNode RPC QoS
- Configuring LZC Compression
- Configuring Reserved Percentage of Disk Usage on DataNodes
- Configuring HDFS NodeLabel
- Configuring HDFS DiskBalancer
- Performing Concurrent Operations on HDFS Files
- Introduction to HDFS Logs
- HDFS Performance Tuning
-
FAQ
- NameNode Startup Is Slow
- Why MapReduce Tasks Fails in the Environment with Multiple NameServices?
- DataNode Is Normal but Cannot Report Data Blocks
- HDFS WebUI Cannot Properly Update Information About Damaged Data
- Why Does the Distcp Command Fail in the Secure Cluster, Causing an Exception?
- Why Does DataNode Fail to Start When the Number of Disks Specified by dfs.datanode.data.dir Equals dfs.datanode.failed.volumes.tolerated?
- Why Does an Error Occur During DataNode Capacity Calculation When Multiple data.dir Are Configured in a Partition?
- Standby NameNode Fails to Be Restarted When the System Is Powered off During Metadata (Namespace) Storage
- Why Data in the Buffer Is Lost If a Power Outage Occurs During Storage of Small Files
- Why Does Array Border-crossing Occur During FileInputFormat Split?
- Why Is the Storage Type of File Copies DISK When the Tiered Storage Policy Is LAZY_PERSIST?
- The HDFS Client Is Unresponsive When the NameNode Is Overloaded for a Long Time
- Can I Delete or Modify the Data Storage Directory in DataNode?
- Blocks Miss on the NameNode UI After the Successful Rollback
- Why Is "java.net.SocketException: No buffer space available" Reported When Data Is Written to HDFS
- Why are There Two Standby NameNodes After the active NameNode Is Restarted?
- When Does a Balance Process in HDFS, Shut Down and Fail to be Executed Again?
- "This page can't be displayed" Is Displayed When Internet Explorer Fails to Access the Native HDFS UI
- NameNode Fails to Be Restarted Due to EditLog Discontinuity
-
Using HetuEngine
- Using HetuEngine from Scratch
- HetuEngine Permission Management
- Creating HetuEngine Compute Instances
- Configuring Data Sources
-
Managing Compute Instances
- Configuring Resource Groups
- Adjusting the Number of Worker Nodes
- Managing a HetuEngine Compute Instance
- Importing and Exporting Compute Instance Configurations
- Viewing the Instance Monitoring Page
- Viewing Coordinator and Worker Logs
- Using Resource Labels to Specify on Which Node Coordinators Should Run
- Using the HetuEngine Client
- Using the HetuEngine Cross-Source Function
- Using HetuEngine Cross-Domain Function
- Using a Third-Party Visualization Tool to Access HetuEngine
- Function & UDF Development and Application
- Introduction to HetuEngine Logs
- HetuEngine Performance Tuning
- Common Issues About HetuEngine
-
HetuEngine SQL Syntax
- Data Type
-
SQL Syntax
-
DDL Syntax
- CREATE SCHEMA
- CREATE VIRTUAL SCHEMA
- CREATE TABLE
- CREATE TABLE AS
- CREATE TABLE LIKE
- CREATE VIEW
- CREATE FUNCTION
- ALTER TABLE
- ALTER VIEW
- ALTER SCHEMA
- DROP SCHEMA
- DROP TABLE
- DROP VIEW
- DROP FUNCTION
- TRUNCATE TABLE
- COMMENT
- VALUES
- SHOW Syntax Overview
- SHOW CATALOGS
- SHOW SCHEMAS (DATABASES)
- SHOW TABLES
- SHOW TBLPROPERTIES TABLE|VIEW
- SHOW TABLE/PARTITION EXTENDED
- SHOW STATS
- SHOW FUNCTIONS
- SHOW SESSION
- SHOW PARTITIONS
- SHOW COLUMNS
- SHOW CREATE TABLE
- SHOW VIEWS
- SHOW CREATE VIEW
- DML Syntax
- TCL Syntax
- DQL Syntax
- Auxiliary Command Syntax
- Reserved Keywords
-
DDL Syntax
-
SQL Functions and Operators
- Logical Operators
- Comparison Functions and Operators
- Condition Expression
- Conversion function
- Mathematical Functions and Operators
- Bitwise Function
- Regular Expressions
- Binary Functions and Operators
- JSON Functions and Operators
- Date and Time Operators
- Aggregate Function
- Window Functions
- Array Functions and Operators
- Map Functions and Operators
- URL Function
- Geospatial Function
- HyperLogLog Function
- UUID Function
- Color Function
- Session Information
- Teradata Function
- Data Masking Functions
- HetuEngine SQL Tutorial
- Appendix
-
Using Hive
- Using Hive from Scratch
- Configuring Hive Parameters
- Hive SQL
- Permission Management
- Using a Hive Client
- Using HDFS Colocation to Store Hive Tables
- Using the Hive Column Encryption Function
- Customizing Row Separators
- Deleting Single-Row Records from Hive on HBase
- Configuring HTTPS/HTTP-based REST APIs
- Enabling or Disabling the Transform Function
- Access Control of a Dynamic Table View on Hive
- Specifying Whether the ADMIN Permissions Is Required for Creating Temporary Functions
- Using Hive to Read Data in a Relational Database
- Supporting Traditional Relational Database Syntax in Hive
- Creating User-Defined Hive Functions
- Enhancing beeline Reliability
- Viewing Table Structures Using the show create Statement as Users with the select Permission
- Writing a Directory into Hive with the Old Data Removed to the Recycle Bin
- Inserting Data to a Directory That Does Not Exist
- Creating Databases and Creating Tables in the Default Database Only as the Hive Administrator
- Disabling of Specifying the location Keyword When Creating an Internal Hive Table
- Enabling the Function of Creating a Foreign Table in a Directory That Can Only Be Read
- Authorizing Over 32 Roles in Hive
- Restricting the Maximum Number of Maps for Hive Tasks
- HiveServer Lease Isolation
- Hive Supporting Transactions
- Switching the Hive Execution Engine to Tez
- Interconnecting Hive with External Self-Built Relational Databases
- Redis-based CacheStore of HiveMetaStore
- Hive Materialized View
- Hive Supporting Reading Hudi Tables
- Hive Supporting Cold and Hot Storage of Partitioned Metadata
- Hive Supporting ZSTD Compression Formats
- Hive Log Overview
- Hive Performance Tuning
-
Common Issues About Hive
- How Do I Delete UDFs on Multiple HiveServers at the Same Time?
- Why Cannot the DROP operation Be Performed on a Backed-up Hive Table?
- How to Perform Operations on Local Files with Hive User-Defined Functions
- How Do I Forcibly Stop MapReduce Jobs Executed by Hive?
- Table Creation Fails Because Hive Complex Fields' Names Contain Special Characters
- How Do I Monitor the Hive Table Size?
- How Do I Prevent Key Directories from Data Loss Caused by Misoperations of the insert overwrite Statement?
- Why Is Hive on Spark Task Freezing When HBase Is Not Installed?
- Error Reported When the WHERE Condition Is Used to Query Tables with Excessive Partitions in FusionInsight Hive
- Why Cannot I Connect to HiveServer When I Use IBM JDK to Access the Beeline Client?
- Description of Hive Table Location (Either Be an OBS or HDFS Path)
- Why Cannot Data Be Queried After the MapReduce Engine Is Switched After the Tez Engine Is Used to Execute Union-related Statements?
- Why Does Hive Not Support Concurrent Data Writing to the Same Table or Partition?
- Why Does Hive Not Support Vectorized Query?
- Hive Configuration Problems
- Using Hudi
-
Using Hue
- Using Hue from Scratch
- Accessing the Hue Web UI
- Hue Common Parameters
- Using HiveQL Editor on the Hue Web UI
- Using the Metadata Browser on the Hue Web UI
- Using File Browser on the Hue Web UI
- Using Job Browser on the Hue Web UI
- Using HBase on the Hue Web UI
- Typical Scenarios
- Hue Log Overview
-
Common Issues About Hue
- How Do I Solve the Problem that HQL Fails to Be Executed in Hue Using Internet Explorer?
- Why Does the use database Statement Become Invalid When Hive Is Used?
- What Can I Do If HDFS Files Fail to Be Accessed Using Hue WebUI?
- What Should I Do If a Large File Fails to Be Uploaded on the Hue Page?
- Hue Page Cannot Be Displayed When the Hive Service Is Not Installed in a Cluster
- How Do I Solve the Problem of Setting the Time Zone of the Oozie Editor on the Hue Web UI?
-
Using Kafka
- Using Kafka from Scratch
- Managing Kafka Topics
- Querying Kafka Topics
- Managing Kafka User Permissions
- Managing Messages in Kafka Topics
- Creating a Kafka Role
- Kafka Common Parameters
- Safety Instructions on Using Kafka
- Kafka Specifications
- Using the Kafka Client
- Configuring Kafka HA and High Reliability Parameters
- Changing the Broker Storage Directory
- Checking the Consumption Status of Consumer Group
- Kafka Balancing Tool Instructions
- Kafka Token Authentication Mechanism Tool Usage
- Kafka Feature Description
- Using Kafka UI
- Introduction to Kafka Logs
- Performance Tuning
- Common Issues About Kafka
-
Using Loader
- Common Loader Parameters
- Creating a Loader Role
- Managing Loader Links
-
Importing Data
- Overview
- Importing Data Using Loader
- Typical Scenario: Importing Data from an SFTP Server to HDFS or OBS
- Typical Scenario: Importing Data from an SFTP Server to HBase
- Typical Scenario: Importing Data from an SFTP Server to Hive
- Typical Scenario: Importing Data from an SFTP Server to Spark
- Typical Scenario: Importing Data from an FTP Server to HBase
- Typical Scenario: Importing Data from a Relational Database to HDFS or OBS
- Typical Scenario: Importing Data from a Relational Database to HBase
- Typical Scenario: Importing Data from a Relational Database to Hive
- Typical Scenario: Importing Data from a Relational Database to Spark
- Typical Scenario: Importing Data from HDFS or OBS to HBase
- Typical Scenario: Importing Data from a Relational Database to ClickHouse
- Typical Scenario: Importing Data from HDFS to ClickHouse
-
Exporting Data
- Overview
- Using Loader to Export Data
- Typical Scenario: Exporting Data from HDFS/OBS to an SFTP Server
- Typical Scenario: Exporting Data from HBase to an SFTP Server
- Typical Scenario: Exporting Data from Hive to an SFTP Server
- Typical Scenario: Exporting Data from Spark to an SFTP Server
- Typical Scenario: Exporting Data from HDFS/OBS to a Relational Database
- Typical Scenario: Exporting Data from HBase to a Relational Database
- Typical Scenario: Exporting Data from Hive to a Relational Database
- Typical Scenario: Exporting Data from Spark to a Relational Database
- Typical Scenario: Importing Data from HBase to HDFS/OBS
- Job Management
- Operator Help
-
Client Tool Description
- Running a Loader Job by Using Commands
- loader-tool Usage Guide
- loader-tool Usage Example
- schedule-tool Usage Guide
- schedule-tool Usage Example
- Using loader-backup to Back Up Job Data
- Open Source sqoop-shell Tool Usage Guide
- Example for Using the Open-Source sqoop-shell Tool (SFTP-HDFS)
- Example for Using the Open-Source sqoop-shell Tool (Oracle-HBase)
- Loader Log Overview
- Common Issues About Loader
-
Using MapReduce
- Converting MapReduce from the Single Instance Mode to the HA Mode
- Configuring the Log Archiving and Clearing Mechanism
- Reducing Client Application Failure Rate
- Transmitting MapReduce Tasks from Windows to Linux
- Configuring the Distributed Cache
- Configuring the MapReduce Shuffle Address
- Configuring the Cluster Administrator List
- Introduction to MapReduce Logs
- MapReduce Performance Tuning
-
Common Issues About MapReduce
- Why Does It Take a Long Time to Run a Task Upon ResourceManager Active/Standby Switchover?
- Why Does a MapReduce Task Stay Unchanged for a Long Time?
- Why the Client Hangs During Job Running?
- Why Cannot HDFS_DELEGATION_TOKEN Be Found in the Cache?
- How Do I Set the Task Priority When Submitting a MapReduce Task?
- Why Physical Memory Overflow Occurs If a MapReduce Task Fails?
- After the Address of MapReduce JobHistoryServer Is Changed, Why the Wrong Page is Displayed When I Click the Tracking URL on the ResourceManager WebUI?
- MapReduce Job Failed in Multiple NameService Environment
- Why a Fault MapReduce Node Is Not Blacklisted?
-
Using Oozie
- Using Oozie from Scratch
- Using the Oozie Client
- Enabling Oozie High Availability (HA)
- Using Oozie Client to Submit an Oozie Job
-
Using Hue to Submit an Oozie Job
- Creating a Workflow
-
Submitting a Workflow Job
- Submitting a Hive2 Job
- Submitting a Spark2x Job
- Submitting a Java Job
- Submitting a Loader Job
- Submitting a MapReduce Job
- Submitting a Sub-workflow Job
- Submitting a Shell Job
- Submitting an HDFS Job
- Submitting a DistCp Job
- Example of Mutual Trust Operations
- Submitting an SSH Job
- Submitting a Hive Script
- Submitting an Email Job
- Submitting a Coordinator Periodic Scheduling Job
- Submitting a Bundle Batch Processing Job
- Querying the Operation Results
- Oozie Log Overview
- Common Issues About Oozie
-
Using Ranger
- Logging In to the Ranger Web UI
- Enabling Ranger Authentication
- Configuring Component Permission Policies
- Viewing Ranger Audit Information
- Configuring a Security Zone
- Viewing Ranger Permission Information
- Adding a Ranger Access Permission Policy for HDFS
- Adding a Ranger Access Permission Policy for HBase
- Adding a Ranger Access Permission Policy for Hive
- Adding a Ranger Access Permission Policy for Yarn
- Adding a Ranger Access Permission Policy for Spark2x
- Adding a Ranger Access Permission Policy for Kafka
- Adding a Ranger Access Permission Policy for HetuEngine
- Ranger Log Overview
-
Common Issues About Ranger
- Why Ranger Startup Fails During the Cluster Installation?
- How Do I Determine Whether the Ranger Authentication Is Used for a Service?
- Why Cannot a New User Log In to Ranger After Changing the Password?
- When an HBase Policy Is Added or Modified on Ranger, Wildcard Characters Cannot Be Used to Search for Existing HBase Tables
-
Using Spark2x
-
Basic Operation
- Getting Started
- Configuring Parameters Rapidly
- Common Parameters
- Spark on HBase Overview and Basic Applications
- Spark on HBase V2 Overview and Basic Applications
- SparkSQL Permission Management(Security Mode)
-
Scenario-Specific Configuration
- Configuring Multi-active Instance Mode
- Configuring the Multi-tenant Mode
- Configuring the Switchover Between the Multi-active Instance Mode and the Multi-tenant Mode
- Configuring the Size of the Event Queue
- Configuring Executor Off-Heap Memory
- Enhancing Stability in a Limited Memory Condition
- Viewing Aggregated Container Logs on the Web UI
- Configuring Whether to Display Spark SQL Statements Containing Sensitive Words
- Configuring Environment Variables in Yarn-Client and Yarn-Cluster Modes
- Configuring the Default Number of Data Blocks Divided by SparkSQL
- Configuring the Compression Format of a Parquet Table
- Configuring the Number of Lost Executors Displayed in WebUI
- Setting the Log Level Dynamically
- Configuring Whether Spark Obtains HBase Tokens
- Configuring LIFO for Kafka
- Configuring Reliability for Connected Kafka
- Configuring Streaming Reading of Driver Execution Results
- Filtering Partitions without Paths in Partitioned Tables
- Configuring Spark2x Web UI ACLs
- Configuring Vector-based ORC Data Reading
- Broaden Support for Hive Partition Pruning Predicate Pushdown
- Hive Dynamic Partition Overwriting Syntax
- Configuring the Column Statistics Histogram to Enhance the CBO Accuracy
- Configuring Local Disk Cache for JobHistory
- Configuring Spark SQL to Enable the Adaptive Execution Feature
- Configuring Event Log Rollover
- Adapting to the Third-party JDK When Ranger Is Used
- Spark2x Logs
- Obtaining Container Logs of a Running Spark Application
- Small File Combination Tools
- Using CarbonData for First Query
-
Spark2x Performance Tuning
- Spark Core Tuning
-
Spark SQL and DataFrame Tuning
- Optimizing the Spark SQL Join Operation
- Improving Spark SQL Calculation Performance Under Data Skew
- Optimizing Spark SQL Performance in the Small File Scenario
- Optimizing the INSERT...SELECT Operation
- Multiple JDBC Clients Concurrently Connecting to JDBCServer
- Optimizing Memory when Data Is Inserted into Dynamic Partitioned Tables
- Optimizing Small Files
- Optimizing the Aggregate Algorithms
- Optimizing Datasource Tables
- Merging CBO
- Optimizing SQL Query of Data of Multiple Sources
- SQL Optimization for Multi-level Nesting and Hybrid Join
- Spark Streaming Tuning
- Spark on OBS Tuning
-
Common Issues About Spark2x
-
Spark Core
- How Do I View Aggregated Spark Application Logs?
- Why Is the Return Code of Driver Inconsistent with Application State Displayed on ResourceManager WebUI?
- Why Cannot Exit the Driver Process?
- Why Does FetchFailedException Occur When the Network Connection Is Timed out
- How to Configure Event Queue Size If Event Queue Overflows?
- What Can I Do If the getApplicationReport Exception Is Recorded in Logs During Spark Application Execution and the Application Does Not Exit for a Long Time?
- What Can I Do If "Connection to ip:port has been quiet for xxx ms while there are outstanding requests" Is Reported When Spark Executes an Application and the Application Ends?
- Why Do Executors Fail to be Removed After the NodeManeger Is Shut Down?
- What Can I Do If the Message "Password cannot be null if SASL is enabled" Is Displayed?
- What Should I Do If the Message "Failed to CREATE_FILE" Is Displayed in the Restarted Tasks When Data Is Inserted Into the Dynamic Partition Table?
- Why Tasks Fail When Hash Shuffle Is Used?
- What Can I Do If the Error Message "DNS query failed" Is Displayed When I Access the Aggregated Logs Page of Spark Applications?
- What Can I Do If Shuffle Fetch Fails Due to the "Timeout Waiting for Task" Exception?
- Why Does the Stage Retry due to the Crash of the Executor?
- Why Do the Executors Fail to Register Shuffle Services During the Shuffle of a Large Amount of Data?
- Why Does the Out of Memory Error Occur in NodeManager During the Execution of Spark Applications
- Why Does the Realm Information Fail to Be Obtained When SparkBench is Run on HiBench for the Cluster in Security Mode?
-
Spark SQL and DataFrame
- What Do I have to Note When Using Spark SQL ROLLUP and CUBE?
- Why Spark SQL Is Displayed as a Temporary Table in Different Databases?
- How to Assign a Parameter Value in a Spark Command?
- What Directory Permissions Do I Need to Create a Table Using SparkSQL?
- Why Do I Fail to Delete the UDF Using Another Service?
- Why Cannot I Query Newly Inserted Data in a Parquet Hive Table Using SparkSQL?
- How to Use Cache Table?
- Why Are Some Partitions Empty During Repartition?
- Why Does 16 Terabytes of Text Data Fails to Be Converted into 4 Terabytes of Parquet Data?
- Why the Operation Fails When the Table Name Is TABLE?
- Why Is a Task Suspended When the ANALYZE TABLE Statement Is Executed and Resources Are Insufficient?
- If I Access a parquet Table on Which I Do not Have Permission, Why a Job Is Run Before "Missing Privileges" Is Displayed?
- Why Do I Fail to Modify MetaData by Running the Hive Command?
- Why Is "RejectedExecutionException" Displayed When I Exit Spark SQL?
- What Should I Do If the JDBCServer Process is Mistakenly Killed During a Health Check?
- Why No Result Is found When 2016-6-30 Is Set in the Date Field as the Filter Condition?
- Why Does the "--hivevar" Option I Specified in the Command for Starting spark-beeline Fail to Take Effect?
- Why Does the "Permission denied" Exception Occur When I Create a Temporary Table or View in Spark-beeline?
- Why Is the "Code of method ... grows beyond 64 KB" Error Message Displayed When I Run Complex SQL Statements?
- Why Is Memory Insufficient if 10 Terabytes of TPCDS Test Suites Are Consecutively Run in Beeline/JDBCServer Mode?
- Why Are Some Functions Not Available when Another JDBCServer Is Connected?
- Why Does an Exception Occur When I Drop Functions Created Using the Add Jar Statement?
- Why Does Spark2x Have No Access to DataSource Tables Created by Spark1.5?
- Why Does Spark-beeline Fail to Run and Error Message "Failed to create ThriftService instance" Is Displayed?
-
Spark Streaming
- Streaming Task Prints the Same DAG Log Twice
- What Can I Do If Spark Streaming Tasks Are Blocked?
- What Should I Pay Attention to When Optimizing Spark Streaming Task Parameters?
- Why Does the Spark Streaming Application Fail to Be Submitted After the Token Validity Period Expires?
- Why does Spark Streaming Application Fail to Restart from Checkpoint When It Creates an Input Stream Without Output Logic?
- Why Is the Input Size Corresponding to Batch Time on the Web UI Set to 0 Records When Kafka Is Restarted During Spark Streaming Running?
- Why the Job Information Obtained from the restful Interface of an Ended Spark Application Is Incorrect?
- Why Cannot I Switch from the Yarn Web UI to the Spark Web UI?
- What Can I Do If an Error Occurs when I Access the Application Page Because the Application Cached by HistoryServer Is Recycled?
- Why Is not an Application Displayed When I Run the Application with the Empty Part File?
- Why Does Spark2x Fail to Export a Table with the Same Field Name?
- Why JRE fatal error after running Spark application multiple times?
- "This page can't be displayed" Is Displayed When Internet Explorer Fails to Access the Native Spark2x UI
- How Does Spark2x Access External Cluster Components?
- Why Does the Foreign Table Query Fail When Multiple Foreign Tables Are Created in the Same Directory?
- What Should I Do If the Native Page of an Application of Spark2x JobHistory Fails to Display During Access to the Page
- Spark Shuffle Exception Handling
-
Spark Core
-
Basic Operation
- Using Tez
-
Using Yarn
- Common Yarn Parameters
- Creating Yarn Roles
- Using the Yarn Client
- Configuring Resources for a NodeManager Role Instance
- Changing NodeManager Storage Directories
- Configuring Strict Permission Control for Yarn
- Configuring Container Log Aggregation
- Using CGroups with YARN
- Configuring the Number of ApplicationMaster Retries
- Configure the ApplicationMaster to Automatically Adjust the Allocated Memory
- Configuring the Access Channel Protocol
- Configuring Memory Usage Detection
- Configuring the Additional Scheduler WebUI
- Configuring Yarn Restart
- Configuring ApplicationMaster Work Preserving
- Configuring the Localized Log Levels
- Configuring Users That Run Tasks
- Yarn Log Overview
- Yarn Performance Tuning
-
Common Issues About Yarn
- Why Mounted Directory for Container is Not Cleared After the Completion of the Job While Using CGroups?
- Why the Job Fails with HDFS_DELEGATION_TOKEN Expired Exception?
- Why Are Local Logs Not Deleted After YARN Is Restarted?
- Why the Task Does Not Fail Even Though AppAttempts Restarts for More Than Two Times?
- Why Is an Application Moved Back to the Original Queue After ResourceManager Restarts?
- Why Does Yarn Not Release the Blacklist Even All Nodes Are Added to the Blacklist?
- Why Does the Switchover of ResourceManager Occur Continuously?
- Why Does a New Application Fail If a NodeManager Has Been in Unhealthy Status for 10 Minutes?
- What Is the Queue Replacement Policy?
- Why Does an Error Occur When I Query the ApplicationID of a Completed or Non-existing Application Using the RESTful APIs?
- Why May A Single NodeManager Fault Cause MapReduce Task Failures in the Superior Scheduling Mode?
- Why Are Applications Suspended After They Are Moved From Lost_and_Found Queue to Another Queue?
- How Do I Limit the Size of Application Diagnostic Messages Stored in the ZKstore?
- Why Does a MapReduce Job Fail to Run When a Non-ViewFS File System Is Configured as ViewFS?
- Why Do Reduce Tasks Fail to Run in Some OSs After the Native Task Feature is Enabled?
-
Using ZooKeeper
- Using ZooKeeper from Scratch
- Common ZooKeeper Parameters
- Using a ZooKeeper Client
- Configuring the ZooKeeper Permissions
- Changing the ZooKeeper Storage Directory
- Configuring the ZooKeeper Connection
- Configuring ZooKeeper Response Timeout Interval
- Binding the Client to an IP Address
- Configuring the Port Range Bound to the Client
- Performing Special Configuration on ZooKeeper Clients in the Same JVM
- Configuring a Quota for a Znode
- ZooKeeper Log Overview
-
Common Issues About ZooKeeper
- Why Do ZooKeeper Servers Fail to Start After Many znodes Are Created?
- Why Does the ZooKeeper Server Display the java.io.IOException: Len Error Log?
- Why Four Letter Commands Don't Work With Linux netcat Command When Secure Netty Configurations Are Enabled at Zookeeper Server?
- How Do I Check Which ZooKeeper Instance Is a Leader?
- Why Cannot the Client Connect to ZooKeeper using the IBM JDK?
- What Should I Do When the ZooKeeper Client Fails to Refresh a TGT?
- Why Is Message "Node does not exist" Displayed when A Large Number of Znodes Are Deleted Using the deleteallCommand
- Appendix
-
Using CarbonData
-
Best Practices
-
Data Analytics
- Using Spark2x to Analyze IoV Drivers' Driving Behavior
- Using Hive to Load HDFS Data and Analyze Book Scores
- Using Hive to Load OBS Data and Analyze Enterprise Employee Information
- Using Flink Jobs to Process OBS Data
- Consuming Kafka Data Using Spark Streaming Jobs
- Using Flume to Collect Log Files from a Specified Directory to HDFS
- Kafka-based WordCount Data Flow Statistics Case
- Data Migration
- Interconnection with Other Cloud Services
- Interconnection with Ecosystem Components
- MRS Cluster Management
-
Data Analytics
-
Developer Guide
-
Developer Guide (LTS)
- Description
- Obtaining Sample Projects from Huawei Mirrors
- Using Open-source JAR File Conflict Lists
- Mapping Between Maven Repository JAR Versions and MRS Component Versions
- Security Authentication
- ClickHouse Development Guide (Security Mode)
- ClickHouse Development Guide (Normal Mode)
-
Flink Development Guide (Security Mode)
- Overview
- Environment Preparation
- Developing an Application
- Debugging the Application
-
More Information
- Introduction to Common APIs
- Overview of RESTful APIs
- Overview of Savepoints CLI
- Introduction to Flink Client CLI
-
FAQ
- Savepoints-related Problems
- What If the Chrome Browser Cannot Display the Title
- What If the Page Is Displayed Abnormally on Internet Explorer 10/11
- What If Checkpoint Is Executed Slowly in RocksDBStateBackend Mode When the Data Amount Is Large
- What If yarn-session Start Fails When blob.storage.directory Is Set to /home
- Why Does Non-static KafkaPartitioner Class Object Fail to Construct FlinkKafkaProducer010?
- When I Use a Newly Created Flink User to Submit Tasks, Why Does the Task Submission Fail and a Message Indicating Insufficient Permission on ZooKeeper Directory Is Displayed?
- Why Cannot I Access the Apache Flink Dashboard?
- How Do I View the Debugging Information Printed Using System.out.println or Export the Debugging Information to a Specified File?
- Incorrect GLIBC Version
-
Flink Development Guide (Normal Mode)
- Overview
- Environment Preparation
- Developing an Application
- Debugging the Application
-
More Information
- Introduction to Common APIs
- Overview of RESTful APIs
- Overview of Savepoints CLI
- Introduction to Flink Client CLI
-
FAQ
- Savepoints-related Problems
- What If the Chrome Browser Cannot Display the Title
- What If the Page Is Displayed Abnormally on Internet Explorer 10/11
- What If Checkpoint Is Executed Slowly in RocksDBStateBackend Mode When the Data Amount Is Large
- What If yarn-session Start Fails When blob.storage.directory Is Set to /home
- Why Does Non-static KafkaPartitioner Class Object Fail to Construct FlinkKafkaProducer010?
- When I Use a Newly Created Flink User to Submit Tasks, Why Does the Task Submission Fail and a Message Indicating Insufficient Permission on ZooKeeper Directory Is Displayed?
- Why Cannot I Access the Apache Flink Dashboard?
- How Do I View the Debugging Information Printed Using System.out.println or Export the Debugging Information to a Specified File?
- Incorrect GLIBC Version
-
HBase Development Guide (Security Mode)
- Overview
- Environment Preparation
-
Developing an Application
- Typical Scenario Description
- Development Idea
-
Example Code Description
- Configuring Log4j Log Output
- Creating Configuration
- Creating Connection
- Creating a Table
- Deleting a Table
- Modifying a Table
- Inserting Data
- Deleting Data
- Reading Data Using Get
- Reading Data Using Scan
- Filtering Data
- Creating a Secondary Index
- Deleting an Index
- Secondary Index-based Query
- Multi-Point Region Division
- Creating a Phoenix Table
- Writing Data to the PhoenixTable
- Reading the PhoenixTable
- Accessing Multiple ZooKeepers
- Querying Cluster Information Using REST
- Obtaining All Tables Using REST
- Operate Namespaces Using REST
- Operate Tables Using REST
- Accessing the ThriftServer Operation Table
- Accessing ThriftServer to Write Data
- Accessing ThriftServer to Write Data
- Using HBase Dual-Read
- Application Commissioning
-
More Information
- SQL Query
- HBase Dual-Read Configuration Items
- External Interfaces
- Phoenix Command Line
-
FAQs
- How to Rectify the Fault When an Exception Occurs During the Running of an HBase-developed Application and "org.apache.hadoop.hbase.ipc.controller.ServerRpcControllerFactory" Is Displayed in the Error Information?
- What Are the Application Scenarios of the Bulkload and put Data-loading Modes?
- An Error Occurred When Building a JAR Package
-
HBase Development Guide (Normal Mode)
- Overview
- Environment Preparation
-
Developing an Application
- Typical Scenario Description
- Development Idea
-
Example Code Description
- Configuring Log4j Log Output
- Creating Configuration
- Creating Connection
- Creating a Table
- Deleting a Table
- Modifying a Table
- Inserting Data
- Deleting Data
- Reading Data Using Get
- Reading Data Using Scan
- Filtering Data
- Creating a Secondary Index
- Deleting an Index
- Secondary Index-based Query
- Multi-Point Region Division
- Creating a Phoenix Table
- Writing Data to the PhoenixTable
- Reading the PhoenixTable
- Accessing Multiple ZooKeepers
- Querying Cluster Information Using REST
- Obtaining All Tables Using REST
- Operate Namespaces Using REST
- Operate Tables Using REST
- Accessing the ThriftServer Operation Table
- Accessing ThriftServer to Write Data
- Accessing ThriftServer to Write Data
- Using HBase Dual-Read
- Application Commissioning
-
More Information
- SQL Query
- HBase Dual-Read Configuration Items
- External Interfaces
- Phoenix Command Line
-
FAQs
- How to Rectify the Fault When an Exception Occurs During the Running of an HBase-developed Application and "org.apache.hadoop.hbase.ipc.controller.ServerRpcControllerFactory" Is Displayed in the Error Information?
- What Are the Application Scenarios of the bulkload and put Data-loading Modes?
- An Error Occurred When Building a JAR Package
- HDFS Development Guide (Security Mode)
- HDFS Development Guide (Normal Mode)
- HetuEngine Development Guide (Security Mode)
- HetuEngine Development Guide (Normal Mode)
- Hive Development Guide (Security Mode)
- Hive Development Guide (Normal Mode)
-
Kafka Development Guide (Security Mode)
- Overview
- Environment Preparation
- Developing an Application
- Application Commissioning
- More Information
- Kafka Development Guide (Normal Mode)
- MapReduce Development Guide (Security Mode)
- MapReduce Development Guide (Normal Mode)
- Oozie Development Guide (Security Mode)
- Oozie Development Guide (Normal Mode)
-
Spark2x Development Guide (Security Mode)
- Overview
- Preparing for the Environment
-
Developing the Project
- Spark Core Project
- Spark SQL Project
- Accessing the Spark SQL Through JDBC
-
Spark on HBase
- Performing Operations on Data in Avro Format
- Performing Operations on the HBase Data Source
- Using the BulkPut Interface
- Using the BulkGet Interface
- Using the BulkDelete Interface
- Using the BulkLoad Interface
- Using the foreachPartition Interface
- Distributedly Scanning HBase Tables
- Using the mapPartition Interface
- Writing Data to HBase Tables In Batches Using SparkStreaming
- Reading Data from HBase and Write It Back to HBase
- Reading Data from Hive and Write It to HBase
- Streaming Connecting to Kafka0-10
- Structured Streaming Project
- Structured Streaming Stream-Stream Join
- Structured Streaming Status Operation
- Concurrent Access from Spark to HBase in Two Clusters
- Synchronizing HBase Data from Spark to CarbonData
- Using Spark to Perform Basic Hudi Operations
- Compiling User-defined Configuration Items for Hudi
- Commissioning the Application
-
More Information
- Common APIs
- Common CLIs
- JDBCServer Interface
- Structured Streaming Functions and Reliability
-
FAQ
- How to Add a User-Defined Library
- How to Automatically Load Jars Packages?
- Why the "Class Does not Exist" Error Is Reported While the SparkStresmingKafka Project Is Running?
- Privilege Control Mechanism of SparkSQL UDF Feature
- Why Does Kafka Fail to Receive the Data Written Back by SLog in to the node where the client is installed as the client installation user.park Streaming?
- Why a Spark Core Application Is Suspended Instead of Being Exited When Driver Memory Is Insufficient to Store Collected Intensive Data?
- Why the Name of the Spark Application Submitted in Yarn-Cluster Mode Does not Take Effect?
- How to Perform Remote Debugging Using IDEA?
- How to Submit the Spark Application Using Java Commands?
- A Message Stating "Problem performing GSS wrap" Is Displayed When IBM JDK Is Used
- Application Fails When ApplicationManager Is Terminated During Data Processing in the Cluster Mode of Structured Streaming
- Restrictions on Restoring the Spark Application from the checkpoint
- Support for Third-party JAR Packages on x86 and TaiShan Platforms
- What Should I Do If a Large Number of Directories Whose Names Start with blockmgr- or spark- Exist in the /tmp Directory on the Client Installation Node?
- Error Code 139 Reported When Python Pipeline Runs in the ARM Environment
- What Should I Do If the Structured Streaming Task Submission Way Is Changed?
- Common JAR File Conflicts
-
Spark2x Development Guide (Normal Mode)
- Overview
- Preparing for the Environment
-
Developing the Project
- Spark Core Project
- Spark SQL Project
- Accessing the Spark SQL Through JDBC
-
Spark on HBase
- Performing Operation on Data in Avro Format
- Performing Operations on the HBase Data Source
- Using the BulkPut Interface
- Using the BulkGet Interface
- Using the BulkDelete Interface
- Using the BulkLoad Interface
- Using the foreachPartition Interface
- Distributedly Scanning HBase Tables
- Using the mapPartition Interface
- Writing Data to HBase Tables In Batches Using SparkStreaming
- Reading Data from HBase and Write It Back to HBase
- Reading Data from Hive and Write It to HBase
- Streaming Connecting to Kafka0-10
- Structured Streaming Project
- Structured Streaming Stream-Stream Join
- Structured Streaming Status Operation
- Synchronizing HBase Data from Spark to CarbonData
- Using Spark to Perform Basic Hudi Operations
- Compiling User-defined Configuration Items for Hudi
- Commissioning the Application
-
More Information
- Common APIs
- Common CLIs
- JDBCServer Interface
- Structured Streaming Functions and Reliability
-
FAQ
- How to Add a User-Defined Library
- How to Automatically Load Jars Packages?
- Why the "Class Does not Exist" Error Is Reported While the SparkStresmingKafka Project Is Running?
- Why Does Kafka Fail to Receive the Data Written Back by Spark Streaming?
- Why a Spark Core Application Is Suspended Instead of Being Exited When Driver Memory Is Insufficient to Store Collected Intensive Data?
- Why the Name of the Spark Application Submitted in Yarn-Cluster Mode Does not Take Effect?
- How to Perform Remote Debugging Using IDEA?
- How to Submit the Spark Application Using Java Commands?
- A Message Stating "Problem performing GSS wrap" Is Displayed When IBM JDK Is Used
- Application Fails When ApplicationManager Is Terminated During Data Processing in the Cluster Mode of Structured Streaming
- Restrictions on Restoring the Spark Application from the checkpoint
- Support for Third-party JAR Packages on x86 and TaiShan Platforms
- What Should I Do If a Large Number of Directories Whose Names Start with blockmgr- or spark- Exist in the /tmp Directory on the Client Installation Node?
- Error Code 139 Reported When Python Pipeline Runs in the ARM Environment
- What Should I Do If the Structured Streaming Task Submission Way Is Changed?
- Common JAR File Conflicts
- YARN Development Guide (Security Mode)
- YARN Development Guide (Normal Mode)
- Development Specifications
-
Manager Management Development Guide
- Overview
- Environment Preparation
- Developing an Application
- Application Commissioning
-
More Information
- External Interfaces
-
FAQ
- JDK1.6 Fails to Connect to the FusionInsight System Using JDK1.8
- An Operation Fails and "authorize failed" Is Displayed in Logs
- An Operation Fails and "log4j:WARN No appenders could be found for logger(basicAuth.Main)" Is Displayed in Logs
- An Operation Fails and "illegal character in path at index 57" Is Displayed in Logs
- Run the curl Command to Access REST APIs
-
Developer Guide (Normal_3.x)
- Description
- Obtaining Sample Projects from Huawei Mirrors
- Using Open-source JAR File Conflict Lists
- Mapping Between Maven Repository JAR Versions and MRS Component Versions
- Security Authentication
- CQL Development Guide (Security Mode)
- CQL Development Guide (Normal Mode)
- ClickHouse Development Guide (Security Mode)
- ClickHouse Development Guide (Normal Mode)
-
Flink Development Guide (Security Mode)
- Overview
- Environment Preparation
- Developing an Application
- Debugging the Application
-
More Information
- Introduction to Common APIs
- Overview of RESTful APIs
- Overview of Savepoints CLI
- Introduction to Flink Client CLI
-
FAQ
- Savepoints-related Problems
- What If the Chrome Browser Cannot Display the Title
- What If the Page Is Displayed Abnormally on Internet Explorer 10/11
- What If Checkpoint Is Executed Slowly in RocksDBStateBackend Mode When the Data Amount Is Large
- What If yarn-session Start Fails When blob.storage.directory Is Set to /home
- Why Does Non-static KafkaPartitioner Class Object Fail to Construct FlinkKafkaProducer010?
- When I Use a Newly Created Flink User to Submit Tasks, Why Does the Task Submission Fail and a Message Indicating Insufficient Permission on ZooKeeper Directory Is Displayed?
- Why Cannot I Access the Apache Flink Dashboard?
- How Do I View the Debugging Information Printed Using System.out.println or Export the Debugging Information to a Specified File?
- Incorrect GLIBC Version
-
Flink Development Guide (Normal Mode)
- Overview
- Environment Preparation
- Developing an Application
- Debugging the Application
-
More Information
- Introduction to Common APIs
- Overview of RESTful APIs
- Overview of Savepoints CLI
- Introduction to Flink Client CLI
-
FAQ
- Savepoints-related Problems
- What If the Chrome Browser Cannot Display the Title
- What If the Page Is Displayed Abnormally on Internet Explorer 10/11
- What If Checkpoint Is Executed Slowly in RocksDBStateBackend Mode When the Data Amount Is Large
- What If yarn-session Start Fails When blob.storage.directory Is Set to /home
- Why Does Non-static KafkaPartitioner Class Object Fail to Construct FlinkKafkaProducer010?
- When I Use a Newly Created Flink User to Submit Tasks, Why Does the Task Submission Fail and a Message Indicating Insufficient Permission on ZooKeeper Directory Is Displayed?
- Why Cannot I Access the Apache Flink Dashboard?
- How Do I View the Debugging Information Printed Using System.out.println or Export the Debugging Information to a Specified File?
- Incorrect GLIBC Version
-
HBase Development Guide (Security Mode)
- Overview
- Environment Preparation
-
Developing an Application
- Typical Scenario Description
- Development Idea
-
Example Code Description
- Configuring Log4j Log Output
- Creating Configuration
- Creating Connection
- Creating a Table
- Deleting a Table
- Modifying a Table
- Inserting Data
- Deleting Data
- Reading Data Using Get
- Reading Data Using Scan
- Filtering Data
- Creating a Secondary Index
- Deleting an Index
- Secondary Index-based Query
- Multi-Point Region Division
- Creating a Phoenix Table
- Writing Data to the PhoenixTable
- Reading the PhoenixTable
- Accessing Multiple ZooKeepers
- Querying Cluster Information Using REST
- Obtaining All Tables Using REST
- Operate Namespaces Using REST
- Operate Tables Using REST
- Accessing the ThriftServer Operation Table
- Accessing ThriftServer to Write Data
- Accessing ThriftServer to Read Data
- Using HBase Dual-Read
- Application Commissioning
-
More Information
- SQL Query
- HBase Dual-Read Configuration Items
- External Interfaces
- HBase Access Configuration on Windows Using EIPs
- Phoenix Command Line
-
FAQs
- How to Rectify the Fault When an Exception Occurs During the Running of an HBase-developed Application and "org.apache.hadoop.hbase.ipc.controller.ServerRpcControllerFactory" Is Displayed in the Error Information?
- What Are the Application Scenarios of the Bulkload and put Data-loading Modes?
- An Error Occurred When Building a JAR Package
-
HBase Development Guide (Normal Mode)
- Overview
- Environment Preparation
-
Developing an Application
- Typical Scenario Description
- Development Idea
-
Example Code Description
- Configuring Log4j Log Output
- Creating Configuration
- Creating Connection
- Creating a Table
- Deleting a Table
- Modifying a Table
- Inserting Data
- Deleting Data
- Reading Data Using Get
- Reading Data Using Scan
- Filtering Data
- Creating a Secondary Index
- Deleting an Index
- Secondary Index-based Query
- Multi-Point Region Division
- Creating a Phoenix Table
- Writing Data to the PhoenixTable
- Reading the PhoenixTable
- Accessing Multiple ZooKeepers
- Querying Cluster Information Using REST
- Obtaining All Tables Using REST
- Operate Namespaces Using REST
- Operate Tables Using REST
- Accessing the ThriftServer Operation Table
- Accessing ThriftServer to Write Data
- Accessing ThriftServer to Read Data
- Using HBase Dual-Read
- Application Commissioning
-
More Information
- SQL Query
- HBase Dual-Read Configuration Items
- External Interfaces
- HBase Access Configuration on Windows Using EIPs
- Phoenix Command Line
-
FAQs
- How to Rectify the Fault When an Exception Occurs During the Running of an HBase-developed Application and "org.apache.hadoop.hbase.ipc.controller.ServerRpcControllerFactory" Is Displayed in the Error Information?
- What Are the Application Scenarios of the bulkload and put Data-loading Modes?
- An Error Occurred When Building a JAR Package
- HDFS Development Guide (Security Mode)
- HDFS Development Guide (Normal Mode)
- Hive Development Guide (Security Mode)
- Hive Development Guide (Normal Mode)
- Impala Development Guide (Security Mode)
- Impala Development Guide (Normal Mode)
-
Kafka Development Guide (Security Mode)
- Overview
- Environment Preparation
- Developing an Application
- Application Commissioning
- More Information
- Kafka Development Guide (Normal Mode)
- Kudu Development Guide (Security Mode)
- Kudu Development Guide (Normal Mode)
- MapReduce Development Guide (Security Mode)
- MapReduce Development Guide (Normal Mode)
- Oozie Development Guide (Security Mode)
- Oozie Development Guide (Normal Mode)
- Presto Development Guide (Security Mode)
- Presto Development Guide (Normal Mode)
-
Spark2x Development Guide (Security Mode)
- Overview
- Preparing for the Environment
-
Developing the Project
- Spark Core Project
- Spark SQL Project
- Accessing the Spark SQL Through JDBC
-
Spark on HBase
- Performing Operations on Data in Avro Format
- Performing Operations on the HBase Data Source
- Using the BulkPut Interface
- Using the BulkGet Interface
- Using the BulkDelete Interface
- Using the BulkLoad Interface
- Using the foreachPartition Interface
- Distributedly Scanning HBase Tables
- Using the mapPartition Interface
- Writing Data to HBase Tables In Batches Using SparkStreaming
- Reading Data from HBase and Write It Back to HBase
- Reading Data from Hive and Write It to HBase
- Streaming Connecting to Kafka0-10
- Structured Streaming Project
- Structured Streaming Stream-Stream Join
- Structured Streaming Status Operation
- Concurrent Access from Spark to HBase in Two Clusters
- Synchronizing HBase Data from Spark to CarbonData
- Using Spark to Perform Basic Hudi Operations
- Compiling User-defined Configuration Items for Hudi
- Commissioning the Application
-
More Information
- Common APIs
- Common CLIs
- JDBCServer Interface
- Structured Streaming Functions and Reliability
-
FAQ
- How to Add a User-Defined Library
- How to Automatically Load Jars Packages?
- Why the "Class Does not Exist" Error Is Reported While the SparkStresmingKafka Project Is Running?
- Privilege Control Mechanism of SparkSQL UDF Feature
- Why Does Kafka Fail to Receive the Data Written Back by SLog in to the node where the client is installed as the client installation user.park Streaming?
- Why a Spark Core Application Is Suspended Instead of Being Exited When Driver Memory Is Insufficient to Store Collected Intensive Data?
- Why the Name of the Spark Application Submitted in Yarn-Cluster Mode Does not Take Effect?
- How to Perform Remote Debugging Using IDEA?
- How to Submit the Spark Application Using Java Commands?
- A Message Stating "Problem performing GSS wrap" Is Displayed When IBM JDK Is Used
- Application Fails When ApplicationManager Is Terminated During Data Processing in the Cluster Mode of Structured Streaming
- Restrictions on Restoring the Spark Application from the checkpoint
- Support for Third-party JAR Packages on x86 and TaiShan Platforms
- What Should I Do If a Large Number of Directories Whose Names Start with blockmgr- or spark- Exist in the /tmp Directory on the Client Installation Node?
- Error Code 139 Reported When Python Pipeline Runs in the ARM Environment
- What Should I Do If the Structured Streaming Task Submission Way Is Changed?
- Common JAR File Conflicts
-
Spark2x Development Guide (Normal Mode)
- Overview
- Preparing for the Environment
-
Developing the Project
- Spark Core Project
- Spark SQL Project
- Accessing the Spark SQL Through JDBC
-
Spark on HBase
- Performing Operation on Data in Avro Format
- Performing Operations on the HBase Data Source
- Using the BulkPut Interface
- Using the BulkGet Interface
- Using the BulkDelete Interface
- Using the BulkLoad Interface
- Using the foreachPartition Interface
- Distributedly Scanning HBase Tables
- Using the mapPartition Interface
- Writing Data to HBase Tables In Batches Using SparkStreaming
- Reading Data from HBase and Write It Back to HBase
- Reading Data from Hive and Write It to HBase
- Streaming Connecting to Kafka0-10
- Structured Streaming Project
- Structured Streaming Stream-Stream Join
- Structured Streaming Status Operation
- Synchronizing HBase Data from Spark to CarbonData
- Using Spark to Perform Basic Hudi Operations
- Compiling User-defined Configuration Items for Hudi
- Commissioning the Application
-
More Information
- Common APIs
- Common CLIs
- JDBCServer Interface
- Structured Streaming Functions and Reliability
-
FAQ
- How to Add a User-Defined Library
- How to Automatically Load Jars Packages?
- Why the "Class Does not Exist" Error Is Reported While the SparkStreamingKafka Project Is Running?
- Why Does Kafka Fail to Receive the Data Written Back by Spark Streaming?
- Why a Spark Core Application Is Suspended Instead of Being Exited When Driver Memory Is Insufficient to Store Collected Intensive Data?
- Why the Name of the Spark Application Submitted in Yarn-Cluster Mode Does not Take Effect?
- How to Perform Remote Debugging Using IDEA?
- How to Submit the Spark Application Using Java Commands?
- A Message Stating "Problem performing GSS wrap" Is Displayed When IBM JDK Is Used
- Application Fails When ApplicationManager Is Terminated During Data Processing in the Cluster Mode of Structured Streaming
- Restrictions on Restoring the Spark Application from the checkpoint
- Support for Third-party JAR Packages on x86 and TaiShan Platforms
- What Should I Do If a Large Number of Directories Whose Names Start with blockmgr- or spark- Exist in the /tmp Directory on the Client Installation Node?
- Error Code 139 Reported When Python Pipeline Runs in the ARM Environment
- What Should I Do If the Structured Streaming Task Submission Way Is Changed?
- Common JAR File Conflicts
-
Storm Development Guide (Security Mode)
- Overview
- Environment Preparation
- Developing an Application
- Running an Application
- More Information
-
Storm Development Guide (Normal Mode)
- Overview
- Environment Preparation
- Developing an Application
- Running an Application
- More Information
- YARN Development Guide (Security Mode)
- YARN Development Guide (Normal Mode)
- Development Specifications
-
Manager Management Development Guide
- Overview
- Environment Preparation
- Developing an Application
- Application Commissioning
-
More Information
- External Interfaces
-
FAQ
- JDK1.6 Fails to Connect to the FusionInsight System Using JDK1.8
- An Operation Fails and "authorize failed" Is Displayed in Logs
- An Operation Fails and "log4j:WARN No appenders could be found for logger(basicAuth.Main)" Is Displayed in Logs
- An Operation Fails and "illegal character in path at index 57" Is Displayed in Logs
- Run the curl Command to Access REST APIs
-
Developer Guide (Normal_Earlier Than 3.x)
- Before You Start
- Method of Building an MRS Sample Project
-
HBase Application Development
- Overview
- Environment Preparation
-
Application Development
- Development Guidelines in Typical Scenarios
- Creating the Configuration Object
- Creating the Connection Object
- Creating a Table
- Deleting a Table
- Modifying a Table
- Inserting Data
- Deleting Data
- Reading Data Using Get
- Reading Data Using Scan
- Using a Filter
- Adding a Secondary Index
- Enabling/Disabling a Secondary Index
- Querying a List of Secondary Indexes
- Using a Secondary Index to Read Data
- Deleting a Secondary Index
- Writing Data into a MOB Table
- Reading MOB Data
- Multi-Point Region Splitting
- ACL Security Configuration
- Application Commissioning
- More Information
- HBase APIs
- FAQs
- Development Specifications
- Hive Application Development
- MapReduce Application Development
- HDFS Application Development
-
Spark Application Development
- Overview
-
Environment Preparation
- Environment Overview
- Preparing a Development User
- Preparing a Java Development Environment
- Preparing a Scala Development Environment
- Preparing a Python Development Environment
- Preparing an Operating Environment
- Downloading and Importing a Sample Project
- (Optional) Creating a Project
- Preparing the Authentication Mechanism Code
-
Application Development
- Spark Core Application
- Spark SQL Application
- Spark Streaming Application
- Application for Accessing Spark SQL Through JDBC
- Spark on HBase Application
- Reading Data from HBase and Writing Data Back to HBase
- Reading Data from Hive and Write Data to HBase
- Using Streaming to Read Data from Kafka and Write Data to HBase
- Application for Connecting Spark Streaming to Kafka0-10
- Structured Streaming Application
- Application Commissioning
-
Application Tuning
-
Spark Core Tuning
- Data Serialization
- Memory Configuration Optimization
- Setting a Degree of Parallelism
- Using Broadcast Variables
- Using the External Shuffle Service to Improve Performance
- Configuring Dynamic Resource Scheduling in Yarn Mode
- Configuring Process Parameters
- Designing a Direction Acyclic Graph (DAG)
- Experience Summary
- SQL and DataFrame Tuning
- Spark Streaming Tuning
- Spark CBO Tuning
-
Spark Core Tuning
- Spark APIs
-
FAQs
- How Do I Add a Dependency Package with Customized Codes?
- How Do I Handle the Dependency Package That Is Automatically Loaded?
- Why the "Class Does not Exist" Error Is Reported While the SparkStreamingKafka Project Is Running?
- Why a Spark Core Application Is Suspended Instead of Being Exited When Driver Memory Is Insufficient to Store Collected Intensive Data?
- Why the Name of the Spark Application Submitted in Yarn-Cluster Mode Does not Take Effect?
- How Do I Submit the Spark Application Using Java Commands?
- How Does the Permission Control Mechanism Work for the UDF Function in SparkSQL?
- Why Does Kafka Fail to Receive the Data Written Back by Spark Streaming?
- How Do I Perform Remote Debugging Using IDEA?
- A Message Stating "Problem performing GSS wrap" Is Displayed When IBM JDK Is Used
- Why Does the ApplicationManager Fail to Be Terminated When Data Is Being Processed in the Structured Streaming Cluster Mode?
- What Should I Do If FileNotFoundException Occurs When spark-submit Is Used to Submit a Job in Spark on Yarn Client Mode?
- What Should I Do If the "had a not serializable result" Error Is Reported When a Spark Task Reads HBase Data?
- How Do I Connect to Hive and HDFS of an MRS Cluster when the Spark Program Is Running on a Local Host?
- Development Specifications
- Storm Application Development
-
Kafka Application Development
- Overview
- Environment Preparation
-
Application Development
- Typical Application Scenario
- Old Producer API Usage Sample
- Old Consumer API Usage Sample
- Producer API Usage Sample
- Consumer API Usage Sample
- Multi-Thread Producer API Usage Sample
- Multi-Thread Consumer API Usage Sample
- SimpleConsumer API Usage Sample
- Description of the Sample Project Configuration File
- Application Commissioning
- Kafka APIs
- FAQs
- Development Specifications
- Presto Application Development
- OpenTSDB Application Development
-
Flink Application Development
- Overview
- Environment Preparation
- Application Development
- Application Commissioning
- Performance Tuning
- More Information
-
FAQs
- Savepoints FAQs
- What Should I Do If Running a Checkpoint Is Slow When RocksDBStateBackend is Set for the Checkpoint and a Large Amount of Data Exists?
- What Should I Do If yarn-session Failed to Be Started When blob.storage.directory Is Set to /home?
- Why Does Non-static KafkaPartitioner Class Object Fail to Construct FlinkKafkaProducer010?
- When I Use the Newly-Created Flink User to Submit Tasks, Why Does the Task Submission Fail and a Message Indicating Insufficient Permission on ZooKeeper Directory Is Displayed?
- Why Can't I Access the Flink Web Page?
- Impala Application Development
- Alluxio Application Development
- Appendix
-
Developer Guide (LTS)
- API Reference
- SDK Reference
-
FAQs
-
MRS Overview
- What Is MRS Used For?
- What Types of Distributed Storage Does MRS Support?
- How Do I Create an MRS Cluster Using a Custom Security Group?
- How Do I Use MRS?
- Region and AZ
- Can I Configure a Phoenix Connection Pool?
- Does MRS Support Change of the Network Segment?
- Can I Downgrade the Specifications of an MRS Cluster Node?
- What Is the Relationship Between Hive and Other Components?
- Does an MRS Cluster Support Hive on Spark?
- What Are the Differences Between Hive Versions?
- Which MRS Cluster Version Supports Hive Connection and User Synchronization?
- What Are the Differences Between OBS and HDFS in Data Storage?
- How Do I Obtain the Hadoop Pressure Test Tool?
- What Is the Relationship Between Impala and Other Components?
- Statement About the Public IP Addresses in the Open-Source Third-Party SDK Integrated by MRS
- What Is the Relationship Between Kudu and HBase?
- Does MRS Support Running Hive on Kudu?
- What Are the Solutions for processing 1 Billion Data Records?
- Can I Change the IP address of DBService?
- Can I Clear MRS sudo Logs?
- Is the Storm Log also limited to 20 GB in MRS cluster 2.1.0?
- What Is Spark ThriftServer?
- What Access Protocols Are Supported by Kafka?
- What If Error 408 Is Reported When an MRS Node Accesses OBS?
- What Is the Compression Ratio of zstd?
- Why Are the HDFS, YARN, and MapReduce Components Unavailable When an MRS Cluster Is Bought?
- Why Is the ZooKeeper Component Unavailable When an MRS Cluster Is Bought?
- Which Python Versions Are Supported by Spark Tasks in an MRS 3.1.0 Cluster?
- How Do I Enable Different Service Programs to Use Different YARN Queues?
- Differences and Relationships Between the MRS Management Console and Cluster Manager
- Billing
- Account and Password
-
Accounts and Permissions
- Does an MRS Cluster Support Access Permission Control If Kerberos Authentication Is not Enabled?
- How Do I Assign Tenant Management Permission to a New Account?
- How Do I Customize an MRS Policy?
- Why Is the Manage User Function Unavailable on the System Page on MRS Manager?
- Does Hue Support Account Permission Configuration?
- Why Cannot I Submit Jobs on the Console After My IAM Account Is Assigned with Related Permissions?
- How Do I Do If an Error Indicating Invalid Authentication Is Reported When I Submit an MRS Cluster Purchase Order?
- Client Usage
-
Web Page Access
- How Do I Change the Session Timeout Duration for an Open Source Component Web UI?
- Why Cannot I Refresh the Dynamic Resource Plan Page on MRS Tenant Tab?
- What Do I Do If the Kafka Topic Monitoring Tab Is Unavailable on Manager?
- How Do I Do If an Error Is Reported or Some Functions Are Unavailable When I Access the Web UIs of HDFS, Hue, YARN, and Flink?
- How Do I Access HDFS of the Cluster in Security Mode on Windows Using EIPs?
- How Do I Access HDFS of the Cluster in Normal Mode on Windows Using EIPs?
- How Do I Access Hive of the Cluster in Security Mode on Windows Using EIPs?
- How Do I Access Hive of the Cluster in Normal Mode on Windows Using EIPs?
- How Do I Access Kafka of the Cluster in Security Mode on Windows Using EIPs?
- How Do I Access Kafka of the Cluster in Normal Mode on Windows Using EIPs?
- How Do I Access Spark of the Cluster in Security Mode on Windows Using EIPs?
- How Do I Access Spark of the Cluster in Normal Mode on Windows Using EIPs?
- How Do I Access HBase of the Cluster in Security Mode on Windows Using EIPs?
- How Do I Access HBase of the Cluster in Normal Mode on Windows Using EIPs?
- How Do I Switch the Mode of Accessing MRS Manager?
-
Alarm Monitoring
- In an MRS Streaming Cluster, Can the Kafka Topic Monitoring Function Send Alarm Notifications?
- Where Can I View the Running Resource Queues When the Alarm "ALM-18022 Insufficient Yarn Queue Resources" Is Reported?
- How Do I Understand the Multi-Level Chart Statistics in the HBase Operation Requests Metric?
- Performance Tuning
-
Job Development
- How Do I Get My Data into OBS or HDFS?
- What Types of Spark Jobs Can Be Submitted in a Cluster?
- Can I Run Multiple Spark Tasks at the Same Time After the Minimum Tenant Resources of an MRS Cluster Is Changed to 0?
- How Do I Do If Job Parameters Separated By Spaces Cannot Be Identified?
- What Are the Differences Between the Client Mode and Cluster Mode of Spark Jobs?
- How Do I View MRS Job Logs?
- How Do I Do If the Message "The current user does not exist on MRS Manager. Grant the user sufficient permissions on IAM and then perform IAM user synchronization on the Dashboard tab page." Is Displayed?
- LauncherJob Job Execution Is Failed And the Error Message "jobPropertiesMap is null." Is Displayed
- How Do I Do If the Flink Job Status on the MRS Console Is Inconsistent with That on Yarn?
- How Do I Do If a SparkStreaming Job Fails After Being Executed Dozens of Hours and the OBS Access 403 Error is Reported?
- How Do I Do If an Alarm Is Reported Indicating that the Memory Is Insufficient When I Execute a SQL Statement on the ClickHouse Client?
- How Do I Do If Error Message "java.io.IOException: Connection reset by peer" Is Displayed During the Execution of a Spark Job?
- How Do I Do If Error Message "requestId=4971883851071737250" Is Displayed When a Spark Job Accesses OBS?
- How Do I Do If the Spark Job Error "UnknownScannerExeception" Is Reported?
- Why DataArtsStudio Occasionally Fail to Schedule Spark Jobs and the Rescheduling also Fails?
- How Do I Do If a Flink Job Fails to Execute and the Error Message "java.lang.NoSuchFieldError: SECURITY_SSL_ENCRYPT_ENABLED" Is Displayed?
- Why Submitted Yarn Job Cannot Be Viewed on the Web UI?
- How Do I Modify the HDFS NameSpace (fs.defaultFS) of an Existing Cluster?
- How Do I Do If the launcher-job Queue Is Stopped by YARN due to Insufficient Heap Size When I Submit a Flink Job on the Management Plane?
- How Do I Do If the Error Message "slot request timeout" Is Displayed When I Submit a Flink Job?
- Data Import and Export of DistCP Jobs
- How Do I View SQL Statements for Hive Jobs on the YARN Web UI?
- Cluster Upgrade/Patching
-
Peripheral Ecosystem Interconnection
- Can MRS Be Used to Perform Read and Write Operations on DLI Tables?
- Does OBS Support the ListObjectsV2 Protocol?
- Can MRS Data Be Stored in a Parallel File System Provided by OBS?
- Can the Crawler Service Be Deployed in MRS?
- Do DWS and MRS Support Secure Deletion (Preventing Retrieval After Deletion)?
- Why Is the Kerberos-Authenticated MRS Cluster Not Found When a Connection Is Set Up from DLF?
- How Do I Use PySpark on an ECS to Connect to an MRS Spark Cluster with Kerberos Authentication Enabled, on the Intranet?
- Why Mapped Fields Do not Exist in the Database After HBase Synchronizes Data to CSS?
- Can Flume Read Data from OBS?
- Can MRS Connect to an External KDC?
- How Do I Solve the Jetty Version Compatibility Issue in Open-Source Kylin 3.x and MRS 1.9.3 Interconnection?
- What If Data Failed to Be Exported from MRS to an OBS Encrypted Bucket?
- How Do I Install HSS on MRS Cluster Nodes?
- Cluster Access
-
Big Data Service Development
- Can MRS Run Multiple Flume Tasks at a Time?
- How Do I Change FlumeClient Logs to Standard Logs?
- Where Are the JAR Files and Environment Variables of Hadoop Stored?
- What Compression Algorithms Does HBase Support?
- Can MRS Write Data to HBase Through the HBase External Table of Hive?
- How Do I View HBase Logs?
- How Do I Set the TTL for an HBase Table?
- How Do I Connect to HBase of MRS Through HappyBase?
- How Do I Balance HDFS Data?
- How Do I Change the Number of HDFS Replicas?
- What Is the Port for Accessing HDFS Using Python?
- How Do I Modify the HDFS Active/Standby Switchover Class?
- What Is the Recommended Number Type of DynamoDB in Hive Tables?
- Can the Hive Driver Be Interconnected with DBCP2?
- How Do I View the Hive Table Created by Another User?
- Where Can I Download the Dependency Package (com.huawei.gaussc10) in the Hive Sample Project?
- Can I Export the Query Result of Hive Data?
- How Do I Do If an Error Occurs When Hive Runs the beeline -e Command to Execute Multiple Statements?
- How Do I Do If a "hivesql/hivescript" Job Fails to Submit After Hive Is Added?
- What If an Excel File Downloaded on Hue Failed to Open?
- How Do I Do If Sessions Are Not Released After Hue Connects to HiveServer and the Error Message "over max user connections" Is Displayed?
- How Do I Reset Kafka Data?
- How Do I Obtain the Client Version of MRS Kafka?
- What Access Protocols Are Supported by Kafka?
- How Do I Do If Error Message "Not Authorized to access group xxx" Is Displayed When a Kafka Topic Is Consumed?
- What Compression Algorithms Does Kudu Support?
- How Do I View Kudu Logs?
- How Do I Handle the Kudu Service Exceptions Generated During Cluster Creation?
- What Are the Differences Between Sample Project Building and Application Development? Is Python Code Supported?
- Does OpenTSDB Support Python APIs?
- How Do I Configure Other Data Sources on Presto?
- How Do I Update the Ranger Certificate?
- How Do I Connect to Spark Shell from MRS?
- How Do I Connect to Spark Beeline from MRS?
- Where Are the Execution Logs of Spark Jobs Stored?
- How Do I Specify a Log Path When Submitting a Task in an MRS Storm Cluster?
- How Do I Check Whether the ResourceManager Configuration of Yarn Is Correct?
- How Do I Modify the allow_drop_detached Parameter of ClickHouse?
- How Do I Do If an Alarm Indicating Insufficient Memory Is Reported During Spark Task Execution?
- How Do I Do If ClickHouse Consumes Excessive CPU Resources?
- How Do I Obtain a Spark JAR File?
- Why Is an Alarm Generated When the NameNode Process Is Not Restarted After the hdfs-site.xml File Is Modified?
- It Takes a Long Time for Spark SQL to Access Hive Partitioned Tables Before Job Startup
- API
-
Cluster Management
- How Do I View All Clusters?
- How Do I View Log Information?
- How Do I View Cluster Configuration Information?
- How Do I Add Services to an MRS Cluster?
- How Do I Install Kafka and Flume in an MRS Cluster?
- How Do I Stop an MRS Cluster?
- Do I Need to Shut Down a Master Node Before Upgrading Its Specifications?
- Can I Expand Data Disk Capacity for MRS?
- Can I Add Components to an Existing Cluster?
- Can I Delete Components Installed in an MRS Cluster?
- Can I Change MRS Cluster Nodes on the MRS Console?
- How Do I Shield Cluster Alarm/Event Notifications?
- Why Is the Resource Pool Memory Displayed in the MRS Cluster Smaller Than the Actual Cluster Memory?
- How Do I Configure the knox Memory?
- What Is the Python Version Installed for an MRS Cluster?
- How Do I View the Configuration File Directory of Each Component?
- How Do I Upload a Local File to a Node Inside a Cluster?
- How Do I Do If the Time on MRS Nodes Is Incorrect?
- How Do I Query the Startup Time of an MRS Node?
- How Do I Do If Trust Relationships Between Nodes Are Abnormal?
- How Do I Adjust the Memory Size of the manager-executor Process?
- Can I Modify a Master Node in an Existing MRS Cluster?
-
Kerberos Usage
- How Do I Change the Kerberos Authentication Status of a Created MRS Cluster?
- What Are the Ports of the Kerberos Authentication Service?
- How Do I Deploy the Kerberos Service in a Running Cluster?
- How Do I Access Hive in a Cluster with Kerberos Authentication Enabled?
- How Do I Access Presto in a Cluster with Kerberos Authentication Enabled?
- How Do I Access Spark in a Cluster with Kerberos Authentication Enabled?
- How Do I Prevent Kerberos Authentication Expiration?
- Metadata Management
-
MRS Overview
-
Troubleshooting
- Account Passwords
- Account Permissions
-
Common Exceptions in Logging In to the Cluster Manager
- Failed to Access Manager of an MRS Cluster
-
Accessing the Web Pages
- Error "502 Bad Gateway" Is Reported During the Access to MRS Manager
- An Error Message Occurs Indicating that the VPC Request Is Incorrect During the Access
- Error 503 Is Reported When Manager Is Accessed Through Direct Connect
- Error Message "You have no right to access this page." Is Displayed When Users log in to the Cluster Page
- Error Message "Invalid credentials" Is Displayed When a User Logs In to Manager
- Failed to Log In to the Manager After Timeout
- Failed to Log In to MRS Manager After the Python Upgrade
- Failed to Log In to MRS Manager After Changing the Domain Name
- Manager Page Is Blank After a Success Login
- Cluster Login Fails Because Native Kerberos Is Installed on Cluster Nodes
- Using Google Chrome to Access MRS Manager on macOS
- How Do I Unlock a User Who Logs in to Manager?
- Why Does the Manager Page Freeze?
-
Common Exceptions in Accessing the MRS Web UI
- How Do I Do If an Error Is Reported or Some Functions Are Unavailable When I Access the Web UIs of HDFS, Hue, YARN, HetuEngine, and Flink?
- Error 500 Is Reported When a User Accesses the Component Web UI
- [HBase WebUI] Users cannot switch from the HBase WebUI to the RegionServer WebUI
- [HDFS WebUI] When users access the HDFS WebUI, an error message is displayed indicating that the number of redirections is too large
- [HDFS WebUI] Failed to access the HDFS WebUI using the Internet Explorer
- [Hue Web UI] A "No Permission" Error Is Displayed When a User Log In to the Hue Web UI
- [Hue Web UI] Failed to Access the Hue Web UI
- [Hue WebUI] The error "Proxy Error" is reported when a user accesses the Hue WebUI
- [Hue WebUI] Why Is the Hue Native Page Cannot Be Properly Displayed If the Hive Service Is Not Installed in a Cluster?
- Hue (Active) Cannot Open Web Pages
- [Ranger WebUI] Why Cannot a New User Log In to Ranger After Changing the Password?
- [Tez WebUI] Error 404 is reported when users access the Tez WebUI
- [Spark WebUI] Why Cannot I Switch from the Yarn Web UI to the Spark Web UI?
- [Spark WebUI] What Can I Do If an Error Occurs when I Access the Application Page Because the Application Cached by HistoryServer Is Recycled?
- [Spark WebUI] Why Is the Native Page of an Application in Spark2x JobHistory Displayed Incorrectly?
- [Spark WebUI] The Spark2x WebUI fails to be accessed using the Internet Explorer
- [Yarn Web UI] Failed to Access the Yarn Web UI
- APIs
-
Cluster Management
- Failed to Reduce Task Nodes
- OBS Certificate in a Cluster Expired
- Replacing a Disk in an MRS Cluster (Applicable to 2.x and Earlier)
- Replacing a Disk in an MRS Cluster (Applicable to 3.x)
- Failed to Execute an MRS Backup Task
- Inconsistency Between df and du Command Output on the Core Node
- Disassociating a Subnet from a Network ACL
- MRS Cluster Becomes Abnormal After the Hostname of a Node Is Changed
- Processes Are Terminated Unexpectedly
- Failed to Configure Cross-Cluster Mutual Trust for MRS
- Network Is Unreachable When Python Is Installed on an MRS Cluster Node Using Pip3
- Connecting the Open-Source confluent-kafka-go to an MRS Security Cluster
- Failed to Execute the Periodic Backup Task of an MRS Cluster
- Failed to Download the MRS Cluster Client
- An Error Is Reported When a Flink Job Is Submitted in an MRS Cluster with Kerberos Authentication Enabled
- An Error Is Reported When the Insert Command Is Executed on the Hive Beeline CLI
- Upgrading the OS to Fix Vulnerabilities for an MRS Cluster Node
- Failed to Migrate Data to MRS HDFS Using CDM
- Alarms Indicating Heartbeat Interruptions Between Nodes Are Frequently Generated in the MRS Cluster
- High Memory Usage of the PMS Process
- High Memory Usage of the Knox Process
- It Takes a Long Time to Access HBase from a Client Outside a Security Cluster
- Failed to Submit Jobs
- OS Disk Space Is Insufficient Due to Oversized HBase Log Files
- OS Disk Space Is Insufficient Due to Oversized HDFS Log Files
- An Exception Occurs During Specifications Upgrade of Nodes in an MRS Cluster
- Failed to Delete a New Tenant on FusionInsight Manager
- MRS Cluster Becomes Unavailable After the VPC Is Changed
- Failed to Submit Jobs on the MRS Console
- Error "symbol xxx not defined in file libcrypto.so.1.1" Is Displayed During HA Certificate Generation
- Some Instances Fail to Be Started After Core Nodes Are Added to the MRS Cluster
- Using Alluixo
- Using ClickHouse
-
Using DBService
- DBServer Instance Is in Abnormal Status
- DBServer Instance Remains in the Restoring State
- Default Port 20050 or 20051 of DBService Is Occupied
- DBServer Instance Is Always in the Restoring State Because the Incorrect /tmp Directory Permission
- Failed to Execute a DBService Backup Task
- Components Failed to Connect to DBService in Normal State
- DBServer Failed to Start
- DBService Backup Failed Because the Floating IP Address Is Unreachable
- DBService Failed to Start Due to the Loss of the DBService Configuration File
-
Using Flink
- Error Message "Error While Parsing YAML Configuration File: Security.kerberos.login.keytab" Is Displayed When a Command Is Executed on the Flink Client
- Error Message "Error while parsing YAML configuration file : security.kerberos.login.principal:pippo" Is Displayed When a Command Is Executed on the Flink Client
- Error Message "Could Not Connect to the Leading JobManager" Is Displayed When a Command Is Executed on the Flink Client
- Failed to Create a Flink Cluster by Running yarn-session As Different Users
- Flink Service Program Fails to Read Files on the NFS Disk
- Failed to Customize the Flink Log4j Log Level
- Using Flume
-
Using HBase
- Slow Response to HBase Connection
- Failed to Authenticate the HBase User
- RegionServer Failed to Start Because the Port Is Occupied
- HBase Failed to Start Due to Insufficient Node Memory
- HBase Service Unavailable Due to Poor HDFS Performance
- HBase Failed to Start Due to Inappropriate Parameter Settings
- RegionServer Failed to Start Due to Residual Processes
- HBase Failed to Start Due to a Quota Set on HDFS
- HBase Failed to Start Due to Corrupted Version Files
- High CPU Usage Caused by Zero-Loaded RegionServer
- HBase Failed to Start with "FileNotFoundException" in RegionServer Logs
- The Number of RegionServers Displayed on the Native Page Is Greater Than the Actual Number After HBase Is Started
- RegionServer Instance Is in the Restoring State
- HBase Failed to Start in a Newly Installed Cluster
- HBase Failed to Start Due to the Loss of the ACL Table Directory
- HBase Failed to Start After the Cluster Is Powered Off and On
- Failed to Import HBase Data Due to Oversized File Blocks
- Failed to Load Data to the Index Table After an HBase Table Is Created Using Phoenix
- Failed to Run the hbase shell Command on the MRS Cluster Client
- Disordered Information Display on the HBase Shell Client Console Due to Printing of the INFO Information
- HBase Failed to Start Due to Insufficient RegionServer Memory
- Failed to Start HRegionServer on the Node Newly Added to the Cluster
- Region in the RIT State for a Long Time Due to HBase File Loss
-
Using HDFS
- HDFS NameNode Instances Become Standby After the RPC Port Is Changed
- An Error Is Reported When the HDFS Client Is Connected Through a Public IP Address
- Failed to Use Python to Remotely Connect to the Port of HDFS
- HDFS Capacity Reaches 100%, Causing Unavailable Upper-Layer Services Such as HBase and Spark
- Error Message "Permission denied" Is Displayed When HDFS and Yarn Are Started
- HDFS Users Can Create or Delete Files in Directories of Other Users
- A DataNode of HDFS Is Always in the Decommissioning State
- HDFS NameNode Failed to Start Due to Insufficient Memory
- A Large Number of Blocks Are Lost in HDFS due to the Time Change Using ntpdate
- CPU Usage of DataNodes Is Close to 100% Occasionally, Causing Node Loss
- Manually Performing Checkpoints When a NameNode Is Faulty for a Long Time
- Error "Failed to place enough replicas" Is Reported When HDFS Reads or Writes Files
- Maximum Number of File Handles Is Set to a Too Small Value, Causing File Reading and Writing Exceptions
- HDFS Client File Fails to Be Closed After Data Writing
- File Fails to Be Uploaded to HDFS Due to File Errors
- After dfs.blocksize Is Configured on the UI and Data Is Uploaded, the Block Size Does Not Change
- HDFS File Fails to Be Read, and Error Message "FileNotFoundException" Is Displayed
- Failed to Write Files to HDFS, and Error Message "item limit of xxx is exceeded" Is Displayed
- Adjusting the Log Level of the HDFS SHDFShell Client
- HDFS File Read Fails, and Error Message "No common protection layer" Is Displayed
- Failed to Write Files Because the HDFS Directory Quota Is Insufficient
- Balancing Fails, and Error Message "Source and target differ in block-size" Is Displayed
- Failed to Query or Delete HDFS Files
- Uneven Data Distribution Due to Non-HDFS Data Residuals
- Uneven Data Distribution Due to HDFS Client Installation on the DataNode
- Unbalanced DataNode Disk Usages of a Node
- Locating Common Balance Problems
- HDFS Displays Insufficient Disk Space But 10% Disk Space Remains
- Error Message "error creating DomainSocket" Is Displayed When the HDFS Client Installed on the Core Node in a Normal Cluster Is Used
- HDFS Files Fail to Be Uploaded When the Client Is Installed on a Node Outside the Cluster
- Insufficient Number of Replicas Is Reported During High Concurrent HDFS Writes
- HDFS Client Failed to Delete Overlong Directories
- An Error Is Reported When a Node Outside the Cluster Accesses MRS HDFS
- "ALM-12027 Host PID Usage Exceeds the Threshold" Is Generated for a NameNode
- ALM-14012 JournalNode Is Out of Synchronization Is Generated in the Cluster
- Failed to Decommission a DataNode Due to HDFS Block Loss
- An Error Is Reported When DistCP Is Used to Copy an Empty Folder
-
Using Hive
- Common Hive Logs
- Failed to Start Hive
- Error Message "Cannot modify xxx at runtime" Is Displayed When the set Command Is Executed in a Security Cluster
- Specifying a Queue When Submitting a Hive Task
- Setting the Map/Reduce Memory on the Client
- Specifying the Output File Compression Format When Importing a Hive Table
- Description of the Hive Table Is Too Long to Be Completely Displayed
- NULL Is Displayed When Data Is Inserted After the Partition Column Is Added to a Hive Table
- New User Created in the Cluster Does Not Have the Permission to Query Hive Data
- An Error Is Reported When SQL Is Executed to Submit a Task to a Specified Queue
- An Error Is Reported When the "load data inpath" Command Is Executed
- An Error Is Reported When the "load data local inpath" Command Is Executed
- An Error Is Reported When the create external table Command Is Executed
- An Error Is Reported When the dfs -put Command Is Executed on the Beeline Client
- Insufficient Permissions to Execute the set role admin Command
- An Error Is Reported When a UDF Is Created on the Beeline Client
- Hive Is Faulty
- Difference Between Hive Service Health Status and Hive Instance Health Status
- "authentication failed" Is Displayed During an Attempt to Connect to the Shell Client
- Failed to Access ZooKeeper from the Client
- "Invalid function" Is Displayed When a UDF Is Used
- Hive Service Status Is Unknown
- Health Status of a HiveServer or MetaStore Instance Is unknown
- Health Status of a HiveServer or MetaStore Instance Is Concerning
- Garbled Characters Returned Upon a Query If Text Files Are Compressed Using ARC4
- Hive Task Failed to Run on the Client but Successful on Yarn
- Error Message "Execution Error return code 2" Is Displayed When the SELECT Statement Is Executed
- Failed to Perform drop partition When There Are a Large Number of Partitions
- Failed to Start the Local Task When the Join Operation Is Performed
- WebHCat Fails to Be Started After the Hostname Is Changed
- An Error Is Reported When the Hive Sample Program Is Running After the Domain Name of a Cluster Is Changed
- Hive MetaStore Exception Occurs When the Number of DBService Connections Exceeds the Upper Limit
- Error Message "Failed to execute session hooks: over max connections" Is Displayed on the Beeline Client
- Error Message "OutOfMemoryError" Is Displayed on the Beeline Client
- Task Execution Fails Because the Input File Number Exceeds the Threshold
- Hive Task Execution Fails Because of Stack Memory Overflow
- Task Failed Due to Concurrent Writes to One Table or Partition
- Hive Task Failed Due to a Lack of HDFS Directory Permission
- Failed to Load Data to Hive Tables
- Failed to Run the Application Developed Based on the Hive JDBC Code Case
- HiveServer and HiveHCat Process Faults
- Error Message "ConnectionLoss for hiveserver2" Is Displayed When MRS Hive Connects to ZooKeeper
- An Error Is Reported When Hive Executes the insert into Statement
- Timeout Reported When Adding the Hive Table Field
- Failed to Restart Hive
- Failed to Delete a Table Due to Excessive Hive Partitions
- An Error Is Reported When msck repair table Is Executed on Hive
- Insufficient User Permission for Running the insert into Command on Hive
- Releasing Disk Space After Dropping a Table in Hive
- Abnormal Hive Query Due to Damaged Data in the JSON Table
- Connection Timed Out During SQL Statement Execution on the Hive Client
- WebHCat Failed to Start Due to Abnormal Health Status
- WebHCat Failed to Start Because the mapred-default.xml File Cannot Be Parsed
- An SQL Error Is Reported When the Number of MetaStore Dynamic Partitions Exceeds the Threshold
- Using Hue
- Using Impala
-
Using Kafka
- An Error Is Reported When the Kafka Client Is Run to Obtain Topics
- Using Python3.x to Connect to Kafka in a Security Cluster
- Flume Normally Connects to Kafka but Fails to Send Messages
- Producer Fails to Send Data and Error Message "NullPointerException" Is Displayed
- Producer Fails to Send Data and Error Message "TOPIC_AUTHORIZATION_FAILED" Is Displayed
- Producer Occasionally Fails to Send Data and the Log Displays "Too many open files in system"
- Consumer Is Initialized Successfully, but the Specified Topic Message Cannot Be Obtained from Kafka
- Consumer Fails to Consume Data and Remains in the Waiting State
- SparkStreaming Fails to Consume Kafka Messages, and "Error getting partition metadata" Is Displayed
- Consumer Fails to Consume Data in a Newly Created Cluster, and Message " GROUP_COORDINATOR_NOT_AVAILABLE" Is Displayed
- SparkStreaming Fails to Consume Kafka Messages, and Message "Couldn't find leader offsets" Is Displayed
- Consumer Fails to Consume Data and Message "SchemaException: Error reading field" Is Displayed
- Kafka Consumer Loses Consumed Data
- Failed to Start Kafka Due to Account Lockout
- Kafka Broker Reports Abnormal Processes and the Log Shows "IllegalArgumentException"
- Kafka Topics Cannot Be Deleted
- Error "AdminOperationException" Is Displayed When a Kafka Topic Is Deleted
- When a Kafka Topic Fails to Be Created, "NoAuthException" Is Displayed
- Failed to Set an ACL for a Kafka Topic, and "NoAuthException" Is Displayed
- When a Kafka Topic Fails to Be Created, "NoNode for /brokers/ids" Is Displayed
- When a Kafka Topic Fails to Be Created, "replication factor larger than available brokers" Is Displayed
- Consumer Repeatedly Consumes Data
- Leader for the Created Kafka Topic Partition Is Displayed as none
- Safety Instructions on Using Kafka
- Obtaining Kafka Consumer Offset Information
- Adding or Deleting Configurations for a Topic
- Reading the Content of the __consumer_offsets Internal Topic
- Configuring Logs for Shell Commands on the Kafka Client
- Obtaining Topic Distribution Information
- Kafka HA Usage Description
- Failed to Manage a Kafka Cluster Using the Kafka Shell Command
- Kafka Producer Writes Oversized Records
- Kafka Consumer Reads Oversized Records
- High Usage of Multiple Disks on a Kafka Cluster Node
- Kafka Is Disconnected from the ZooKeeper Client
- Using Oozie
-
Using Presto
- During sql-standard-with-group Configuration, a Schema Fails to Be Created and the Error Message "Access Denied" Is Displayed
- Coordinator Process of Presto Cannot Be Started
- When Presto Queries a Kudu Table, an Error Is Reported Indicating That the Table Cannot Be Found
- No Data is Found in the Hive Table Using Presto
- Error Message "The node may have crashed or be under too much load" Is Displayed During MRS Presto Query
- Accessing Presto from an MRS Cluster Through a Public Network
-
Using Spark
- An Error Is Reported When the Split Size Is Changed for a Running Spark Application
- Incorrect Parameter Format Is Displayed When a Spark Task Is Submitted
- Spark, Hive, and Yarn Are Unavailable Due to Insufficient Disk Capacity
- A Spark Job Fails to Run Due to Incorrect JAR File Import
- Spark Job Suspended Due to Insufficient Memory or Lack of JAR Packages
- Error "ClassNotFoundException" Is Reported When a Spark Task Is Submitted
- Driver Displays a Message Indicating That the Running Memory Exceeds the Threshold When a Spark Task Is Submitted
- Error "Can't get the Kerberos realm" Is Reported When a Spark Task Is Submitted in Yarn-Cluster Mode
- Failed to Start spark-sql and spark-shell Due to JDK Version Mismatch
- ApplicationMaster Fails to Start Twice When a Spark Task Is Submitted in Yarn-client Mode
- Failed to Connect to ResourceManager When a Spark Task Is Submitted
- DataArts Studio Failed to Schedule Spark Jobs
- Job Status Is error After a Spark Job Is Submitted Through an API
- ALM-43006 Is Repeatedly Reported for the MRS Cluster
- Failed to Create or Delete a Table in Spark Beeline
- Failed to Connect to the Driver When a Spark Job Is Submitted on a Node Outside the Cluster
- Large Number of Shuffle Results Are Lost During Spark Task Execution
- Disk Space Is Insufficient Due to Long-Term Running of JDBCServer
- Failed to Load Data to a Hive Table Across File Systems by Running SQL Statements Using Spark Shell
- Spark Task Submission Failure
- Spark Task Execution Failure
- JDBCServer Connection Failure
- Failed to View Spark Task Logs
- Spark Streaming Task Submission Issues
- Authentication Fails When Spark Connects to Other Services
- Authentication Fails When Spark Connects to Kafka
- An Error Occurs When SparkSQL Reads the ORC Table
- Failed to Switch to the Log Page from stderr and stdout on the Native Spark Web UI
- An Error Is Reported When spark-beeline Is Used to Query a Hive View
-
Using Sqoop
- Connecting Sqoop to MySQL
- Failed to Find the HBaseAdmin.<init> Method When Sqoop Reads Data from the MySQL Database to HBase
- An Error Is Reported When a Sqoop Task Is Created Using Hue to Import Data from HBase to HDFS
- A Data Format Error Is Reported When Data Is Exported from Hive to MySQL 8.0 Using Sqoop
- An Error Is Reported When the sqoop import Command Is Executed to Extract Data from PgSQL to Hive
- Failed to Use Sqoop to Read MySQL Data and Write Parquet Files to OBS
- An Error Is Reported When Database Data Is Migrated Using Sqoop
-
Using Storm
- Invalid Hyperlink of Events on the Storm Web UI
- Failed to Submit the Storm Topology
- Failed to Submit the Storm Topology and Message "Failed to check principle for keytab" Is Displayed
- Worker Logs Are Empty After the Storm Topology Is Submitted
- Worker Runs Abnormally After the Storm Topology Is Submitted and Error "Failed to bind to XXX" Is Displayed
- "well-known file is not secure" Is Displayed When the jstack Command Is Used to Check the Process Stack
- Data Cannot Be Written to Bolts When the Storm-JDBC Plug-in Is Used to Develop Oracle Databases
- Internal Server Error Is Displayed When the User Queries Information on the Storm UI
- Using Ranger
-
Using Yarn
- A Large Number of Jobs Occupying Resources After Yarn Is Started in a Cluster
- Error "GC overhead" Is Reported When Tasks Are Submitted Using the hadoop jar Command on the Client
- Disk Space of a Node Is Used Up Due to Oversized Aggregated Logs of Yarn
- Temporary Files Are Not Deleted When a MapReduce Job Is Abnormal
- Incorrect Port Information of the Yarn Client Causes Error "connection refused" After a Task Is Submitted
- "Could not access logs page!" Is Displayed When Job Logs Are Queried on the Yarn Web UI
- Error "ERROR 500" Is Displayed When Queue Information Is Queried on the Yarn Web UI
- Error "ERROR 500" Is Displayed When Job Logs Are Queried on the Yarn Web UI
- An Error Is Reported When a Yarn Client Command Is Used to Query Historical Jobs
- Number of Files in the TimelineServer Directory Reaches the Upper Limit
- Using ZooKeeper
-
Storage-Compute Decoupling
- A User Without the Permission on the /tmp Directory Failed to Execute a Job for Accessing OBS
- When the Hadoop Client Is Used to Delete Data from OBS, It Does Not Have the Permission for the .Trash Directory
- An MRS Cluster Fails Authentication When Accessing OBS Because the NTP Time of Cluster Nodes Is Not Synchronized
Hive Supporting Transactions
Scenario
Hive supports transactions at the table and partition levels. When the transaction mode is enabled, transaction tables can be incrementally updated, deleted, and read, implementing atomicity, isolation, consistency, and durability of operations on transaction tables.
Introduction to Transaction Features
A transaction is a group of unitized operations. These operations are either executed together or not executed together. A transaction is an inseparable unit of work. The four basic elements of a transaction are usually called ACID features, which are as follows:
- Atomicity: A transaction is an inseparable unit of work. All operations in a transaction occur or do not occur together.
- Consistency: The database integrity constraints are not damaged before and after a transaction starts.
- Isolation: When multiple transactions are concurrently accessed, the transactions are isolated from each other. A transaction does not affect the running of other transactions. The impacts between transactions are as follows: dirty read, non-repeatable read, phantom read, and lost update.
- Durability: After a transaction is complete, changes made by the transaction lock to the database are permanently stored in the database.
Characteristics of transaction execution:
- A statement can be written to multiple partitions or tables. If the operation fails, the user cannot see partial write or insert. Even if data is frequently changed, operations can still be quickly performed.
- Hive can automatically compress ACID transaction files without affecting concurrent queries. When querying many small partition files, automatic compression can improve query performance and metadata occupation.
- Read semantics include snapshot isolation. When the read operation starts, the Hive data warehouse is logically locked. The read operation is not affected by any changes that occur during the operation.
Lock Mechanism
Transactions implement the ACID feature through the following two aspects:
- Write-ahead logging ensures atomicity and durability.
- Locking ensures isolation.
|
Operation |
Type of Held Locks |
|---|---|
|
Insert overwrite |
If hive.txn.xlock.iow is set to true, the exclusive lock is held. If hive.txn.xlock.iow is set to false, the semi-shared lock is held. |
|
Insert |
Shared lock. When performing this operation, you can perform read and write operations on the current table or partition. |
|
Update/delete |
Semi-shared lock. When this operation is performed, an operation of holding a shared lock can be performed, but an operation of holding an exclusive lock or a semi-shared lock cannot be performed. |
|
Drop |
Exclusive lock. You cannot perform any other operations on the current table or partition when performing this operation. |
 NOTE:
NOTE:
If a conflict caused by the lock mechanism exists in the write operation, the operation that preferentially holds the lock succeeds, and other operations fail.
Procedure
Starting a Transaction
- Log in to FusionInsight Manager. For details, see Accessing FusionInsight Manager. Choose Cluster > Name of the desired cluster > Services > Hive > Configurations > All Configurations > MetaStore(Role) > Transaction.
- Set metastore.compactor.initiator.on to true.
- Set metastore.compactor.worker.threads to a positive integer.
NOTE:
metastore.compactor.worker.threads: Specifies the number of working threads for running the compression program on MetaStore. Set this parameter based on the actual requirements. If the value is too small, the transaction compression task is executed slowly. If the value is too large, the MetaStore execution performance deteriorates.
- Log in to the Hive client and run the following command to enable the following parameters. For details, see Using a Hive Client.
set hive.support.concurrency=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
Create a transaction table.
- Run the following command to create a transaction table:
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name (col_name data_type [COMMENT col_comment], ...) [ROW FORMAT row_format] STORED AS orc ...... TBLPROPERTIES ('transactional'='true'[,'groupId'='group1' ... ] );
For example:
CREATE TABLE acidTbl (a int, b int) STORED AS ORC TBLPROPERTIES ('transactional'='true');
NOTE:
- Currently, the transactions support only the ORC format.
- External tables are not supported.
- Sorted tables are not supported.
- To create a transaction table, you must add the table attribute transactional'='true'.
- The transaction table can be read and written only in transaction mode.
Use the transaction table.
- Run commands to use the transaction table. The following uses the acidTbl table as an example:
- Insert data into an existing transaction table:
- Update an existing transaction table:
UPDATE acidTbl SET b = 10 where a = 1;
The content of acidTbl is changed to:

- Merge the old and new transaction tables:
The acidTbl_update table contains the following data:

MERGE INTO acidTbl AS a
USING acidTbl_update AS b ON a.a = b.a
WHEN MATCHED THEN UPDATE SET b = b. b
WHEN NOT MATCHED THEN INSERT VALUES (b.a, b.b);
The content of acidTbl is changed to:
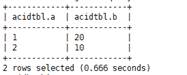 NOTE:
NOTE:
If "Error evaluating cardinality_violation" is displayed when you run the merge command, check whether duplicate connection keys exist or run the set hive.merge.cardinality.check=false command to avoid this exception.
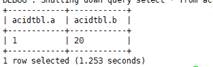
Checking the Transaction Execution Status
- Run the following command to check the transaction execution status:
Configuring the Compression Function
HDFS does not support in-place file changing. For the new content, HDFS does not provide read consistency either. To provide these features on HDFS, we follow the standard approach used in other data warehouse tools: table or partition data is stored in a set of base files, and new, updated, as well as deleted records are stored in incremental files. Each transaction creates a new set of incremental files to change the table or partition. When read, the base files and the incremental files are merged and the changes of the update or deletion are applied.
Writing a transaction table generates some small files in HDFS. Hive provides major and minor compression policies for combining these small files.
Procedure of Automatic Compression
- Log in to FusionInsight Manager. For details, see Accessing FusionInsight Manager. Choose Cluster > Name of the desired cluster > Services > Hive > Configurations > All Configurations > MetaStore(Role) > Transaction.
- Set the following parameters as required:
Table 1 Parameter description Parameter
Description
hive.compactor.check.interval
Interval of executing compression threads. Unit: second. Default value: 300
hive.compactor.cleaner.run.interval
Interval of executing cleaning threads. Unit: millisecond. Default value: 5,000.
hive.compactor.delta.num.threshold
Threshold of the number of incremental files that trigger minor compression. Default value: 10
hive.compactor.delta.pct.threshold
Ratio threshold of the total size of incremental files (delta) that trigger Major compression to the size of base files. The value 0.1 indicates that Major compression is triggered when the ratio of the total size of delta files to the size of base files is 10%. Default value: 0.1
hive.compactor.max.num.delta
Maximum number of incremental files that the compressor will attempt to process in a single job. Default value: 500
metastore.compactor.initiator.on
Indicates whether to run the startup program thread and cleanup program thread on the MetaStore instance. The value must be true. Default value: false.
metastore.compactor.worker.threads
Number of compression program work threads running on MetaStore. If this parameter is set to 0, no compression is performed. To use a transaction, you must set this parameter to a positive number on one or more instances of the MetaStore service. Unit: second Default value: 0
- Log in to the Hive client and perform compression. For details, see Using a Hive Client.
CREATE TABLE table_name ( id int, name string ) CLUSTERED BY (id) INTO 2 BUCKETS STORED AS ORC TBLPROPERTIES ("transactional"="true", "compactor.mapreduce.map.memory.mb"="2048", -- Specify the properties of a compression map job. "compactorthreshold.hive.compactor.delta.num.threshold"="4", -- If there are more than four incremental directories, slight compression is triggered. "compactorthreshold.hive.compactor.delta.pct.threshold"="0.5" -- If the ratio of the incremental file size to the basic file size is greater than 50%, deep compression is triggered. );or
ALTER TABLE table_name COMPACT 'minor' WITH OVERWRITE TBLPROPERTIES ("compactor.mapreduce.map.memory.mb"="3072"); -- Specify the properties of a compression map job. ALTER TABLE table_name COMPACT 'major' WITH OVERWRITE TBLPROPERTIES ("tblprops.orc.compress.size"="8192"); -- Modify any other Hive table attributes.NOTE:
After compression, small files are not deleted immediately. After the cleaner thread performs cleaning, the files are deleted in batches.
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.



