

Horovod/MPI/MindSpore-GPU
ModelArts训练服务支持了多种AI引擎,并对不同的引擎提供了针对性适配,用户在使用这些引擎进行模型训练时,训练的算法代码也需要做相应适配,本文讲解了使用Horovod/MPI/MindSpore-GPU引擎所需要做的代码适配。
Horovod/MPI/MindSpore-GPU框架启动原理
规格和节点个数
下面以选择“GPU: 8*GP-Vnt1 | CPU: 72核 | 内存:512GB”规格为例,介绍在单机和分布式场景下ModelArts规格资源的分配情况。
单机作业时(即选择的节点数为1),ModelArts只会在一个节点上启动一个训练容器,该训练容器独享节点规格的可使用资源。
分布式作业时(即选择的节点数大于1),worker的数量和创建作业时选择的节点数一致,每个worker将被分配到所选规格对应的计算资源。例如计算节点个数为“2”时,将启动2个worker,每个worker拥有“GPU: 8*GP-Vnt1 | CPU: 72核 | 内存:512GB”的计算资源。
网络通信介绍
- 单机作业不涉及网络通信情况。
- 分布式作业的涉及网络通信则可以分为节点内网络通信和节点间网络通信。
节点内网络
使用NVLink和共享内存通信。
节点间网络
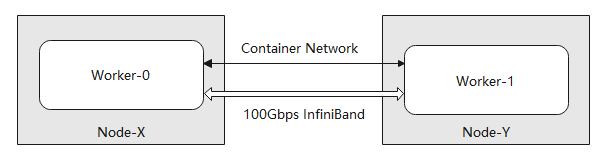
当计算节点个数大于1时,将启动PyTorch引擎分布式训练模式。PyTorch引擎的分布式模式如下图所示,worker之间可通过容器网络和100Gbps的InfiniBand网卡或RoCE网卡通信,部分规格中使用RoCE网卡,将在规格中额外提示。其中,容器网络可以通过DNS域名通信,但网络性能一般,可用于点对点小规模通信需求;InfiniBand网络和RoCE网络为高性能网络,可用于集合通信等分布式训练的场景。
启动命令
训练服务使用作业镜像中默认的python解释器启动训练脚本,即which python命令指向的可执行文件,启动时的工作目录(即pwd命令或python中os.getcwd()返回的目录)为/home/ma-user/user-job-dir/<代码目录最外层目录名>。
启动命令
mpirun \
-np ${OPENMPI_NP} \
-hostfile ${OPENMPI_HOST_FILE_PATH} \
-mca plm_rsh_args "-p ${SSHD_PORT}" \
-tune ${TUNE_ENV_FILE} \
${OPENMPI_BIND_ARGS} \
${OPENMPI_X_ARGS} \
${OPENMPI_MCA_ARGS} \
${OPENMPI_EXTRA_ARGS} \
python <启动文件相对路径> <作业运行参数>
- OPENMPI_NP:可控制mpirun启动的进程数,默认为“GPU 卡数 * 节点数”,不建议修改。
- OPENMPI_HOST_FILE_PATH:可控制hostfile参数,不建议修改。
- SSHD_PORT:可控制ssh登录端口,不建议修改。
- TUNE_ENV_FILE:将worker-0的如下env,广播到当前训练作业的其他worker节点。
- MA_ 前缀的env
- SHARED_ 前缀的env
- S3_ 前缀的env
- PATH的env
- VC_WORKER_ 前缀的env
- SCC前缀的env
- CRED前缀的env
env|grep -E '^MA_|^SHARED_|^S3_|^PATH|^VC_WORKER_|^SCC|^CRED'|grep -v '=$'> ${TUNE_ENV_FILE}
- OPENMPI_BIND_ARGS:可控制mprun cpu绑核行为,默认设置如下。
OPENMPI_BIND_ARGS="-bind-to none -map-by slot"
- OPENMPI_X_ARGS:可控制mpirun -x参数,默认设置如下。
OPENMPI_X_ARGS="-x LD_LIBRARY_PATH -x HOROVOD_MPI_THREADS_DISABLE=1 -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=ib0,bond0,eth0 -x NCCL_SOCKET_FAMILY=AF_INET -x NCCL_IB_DISABLE=0"
- OPENMPI_MCA_ARGS:可控制mpirun -mca参数,默认设置如下。
OPENMPI_MCA_ARGS="-mca pml ob1 -mca btl ^openib -mca plm_rsh_no_tree_spawn true"
- OPENMPI_EXTRA_ARGS:控制可额外传递到mpirun的参数,默认设置为空。
- 启动文件相对路径:启动文件相对“/home/ma-user/user-job-dir/<代码目录最外层目录名>”的路径 。
- 作业运行参数:训练作业中配置的运行参数 。
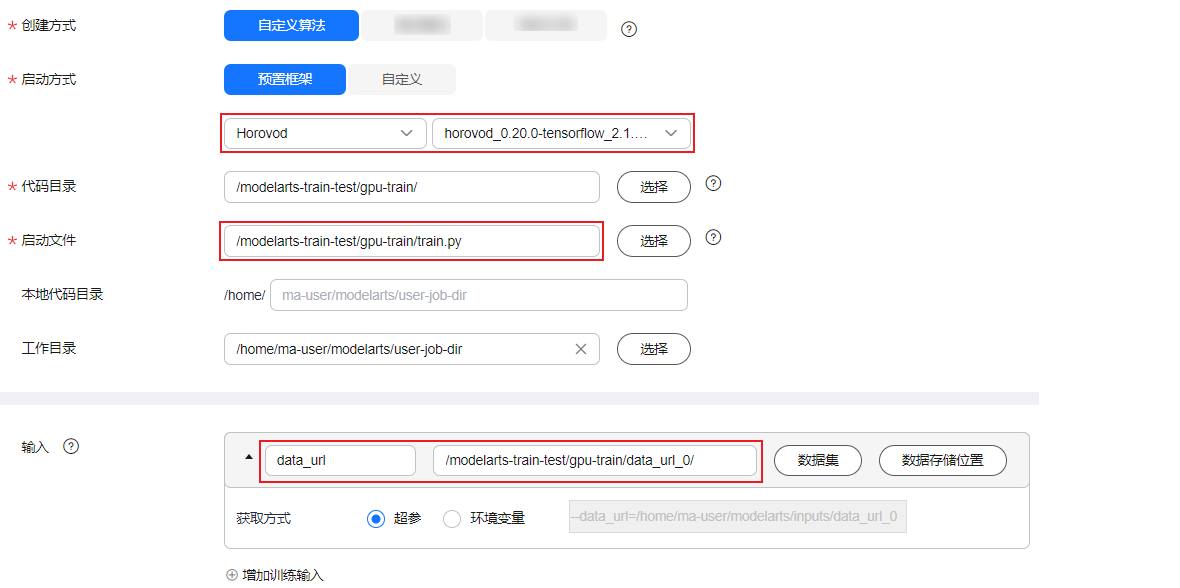
例如控制台上设置如上图所示,则控制台后台执行命令如下:
mpirun \
-np ${np} \
-hostfile ${OPENMPI_HOST_FILE_PATH} \
-mca plm_rsh_args "-p ${SSHD_PORT}" \
-tune ${TUNE_ENV_FILE} \
${OPENMPI_BIND_ARGS} \
${OPENMPI_X_ARGS} \
${OPENMPI_MCA_ARGS} \
${OPENMPI_EXTRA_ARGS} \
python /home/ma-user/user-job-dir/gpu-train/train.py --datasets=obs://modelarts-train-test/gpu-train/data_url_0

Horovod/MPI/MindSpore-GPU框架单机启动命令和分布式启动命令无区别。








