

关于并行导入
INSERT(通过INSERT语句直接写入数据)和COPY(使用COPY FROM STDIN导入数据)方式执行数据导入时,是一个串行执行的过程,导入性能低,因此适用于小数据量的导入。对于大数据量的导入,GaussDB支持通过外表并行导入数据到集群。外表的并行导入需要开启stream算子(由guc参数enable_stream_operator控制)才能够使用。
概述
并行导入将存储在服务器普通文件系统中的数据导入到GaussDB数据库中。
并行导入功能通过外表设置的导入策略、导入数据格式等信息来识别数据源文件,利用多DN并行的方式,将数据从数据源文件导入到数据库中,从而提高整体导入性能。如图1所示:
- CN只负责任务的规划及下发,把数据导入的工作交给了DN,释放了CN的资源,使其有能力处理其他外部请求。
- 所有DN都参与数据导入,这样可以充分利用各设备的计算能力及网络带宽,提升导入效率。

上图中所涉及的相关概念说明如下:
- CN(Coordinator Node):GaussDB协调节点。在导入场景下,接收到应用或客户端的导入SQL指令后,负责任务的规划及下发到DN。
- DN(Data Node):GaussDB数据节点。接收CN下发的导入任务,将数据源文件中的数据通过外表写入数据库目标表中。
- 数据源文件:存有数据的文件。文件中保存的是待导入数据库的数据。
- 数据服务器:数据源文件所在的服务器称为数据服务器。基于安全考虑,建议数据服务器和GaussDB集群处于同一内网。
- 外表Foreign Table:用于识别数据源文件的位置、文件格式、存放位置、编码格式、数据间的分隔符等信息。是关联数据文件与数据库实表(目标表)的对象。
- 目标表:数据库中的实表。数据源文件中的数据最终导入到这些表中存储,包括行存表和列存表。
加载策略
- Normal策略:利用高斯数据服务工具GDS(Gauss Data Service)来管理用户数据,将集群之外主机上的数据导入到集群中。
- Shared策略:利用网络文件系统NFS(Network File System)服务,将存放用户数据的服务器统一挂载到各DN所在主机的相同路径下,将集群之外主机上的数据导入到集群中。此策略下,由CN在规划任务时扫描所有数据文件,然后将数据文件平均地分配给各DN执行加载。
- Private策略:用户自行将数据文件上传到各DN所在主机。并保证数据文件按DN数均分后,不重复地存储到各主机上相同路径下,以DN node_name命名的文件夹下。这样,数据导入时,每个DN会不断从以自己node_name命名的数据目录中寻找未被加载过的文件,直到没有数据文件可加载为止。
从表1中的对比看,Normal策略因其扩展性强、准备工作简单、对导入的单行数据大小无限制,是优先推荐和常用的策略,其中Private和Shared模式的外表,需要初始用户或者运维模式下(operation_mode)的运维管理员权限。本章节也将主要介绍使用GDS的并行导入方法。关于另外两种方式可以参考示例2:Shared策略导入和示例3:Private策略导入。
GDS并发导入
- 数据量大,数据存储在多个服务器上时,在每个数据服务器上安装配置、启动GDS后,各服务器上的数据可以并行入库。如图2所示。

GDS进程数目不能超过DN数目。如果超过,会出现一个DN连接多个GDS进程的情形,可能会导致部分GDS异常运行,并有可能出现“Session doesn't exists”报错。若参与某次导入的GDS数量大于DN数量,则在导入执行开始时,会返回“It is recommanded that the number of GDS should not be greater than the number of datanode”的warning。
- 数据存储在一台数据服务器上时,如果GaussDB及数据服务器上的I/O资源均还有可利用空间时,可以采用GDS多线程来支持并发导入。
GDS是根据导入事务并发数来决定服务运行线程数的。也就是说即使启动GDS时设置了多线程,也并不会加速单个导入事务。未做过人为事务处理时,一条INSERT语句就是一个导入事务。
综上,多线程的使用场景如下:

导入流程
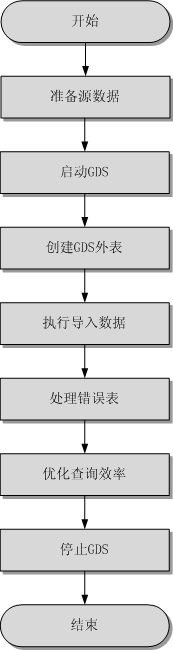
|
流程 |
说明 |
|---|---|
|
准备源数据 |
准备需要导入数据库的源数据文件,并上传至数据服务器。 详细内容请参见准备源数据。 |
|
启动GDS |
在数据服务器上安装配置并启动GDS。 详细内容请参见安装配置和启动GDS。 |
|
创建外表 |
创建外表用于识别数据源文件中的数据。外表中保存了数据源文件的位置、文件格式、存放位置、编码格式、数据间的分隔符等信息。 详细内容请参见创建GDS外表。 |
|
执行导入数据 |
在创建好外表后,通过INSERT语句,将数据快速、高效地导入到目标表中。详细内容请参见执行导入数据。 |
|
处理错误表 |
在数据并行导入发生错误时,请根据具体的错误信息进行处理,以保证导入数据的完整性。 详细内容请参见处理错误表。 |
|
优化查询效率 |
导入数据后,通过ANALYZE语句生成表统计信息。ANALYZE语句会将统计结果自动存储在系统表PG_STATISTIC中。执行计划生成器会使用这些统计数据,以生成最有效的查询执行计划。 详细内容请参见分析表。 |
|
停止GDS |
待数据导入完成后,登录每台数据服务器,分别停止GDS。 GDS的停止请参见停止GDS。 |





