向量召回评估
概述
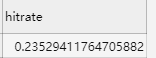
向量召回评估算子计算召回的hitrate,用于评估召回结果的好坏,hitrate越高表示训练产出的向量去召回向量的结果越准确。支持u2i召回和i2i召回的计算。u2i召回时,拿user(用户)的向量去召回top k个items(物品),i2i召回时拿item的向量去召回top k个items。 hitrate的具体计算方法为,假设真实trigger(u2i召回时为user,i2i召回时为item)的关联item集合为M,而实际召回了top k个和trigger相似的items,如果其中落在了M里的集合为N,则top k hitrate为|N| / |M|。
输入
参数 |
子参数 |
参数说明 |
|---|---|---|
inputs |
item_embedding |
inputs为字典类型,item_embedding为pyspark中的DataFrame类型对象,代表物品向量。 |
inputs |
true_sequence |
true_sequence为pyspark中的DataFrame类型对象,代表真实关联表。 |
inputs |
user_embedding |
user_embedding为pyspark中的DataFrame类型对象,代表用户向量。 |
输出
参数 |
子参数 |
参数说明 |
|---|---|---|
output |
output_port_1 |
output为字典类型,output_port_1为总体的hitrate,类型为pyspark的DataFrame。 |
output |
output_port_2 |
output为字典类型,output_port_2为详细的召回评估结果,类型为pyspark的DataFrame。 |
参数说明
参数 |
是否必选 |
参数说明 |
默认值 |
|---|---|---|---|
recall_type |
是 |
召回类型,u2i或i2i。 |
u2i |
emb_dim |
是 |
向量表的维度。 |
5 |
k |
是 |
召回数量。 |
3 |
样例
数据样本
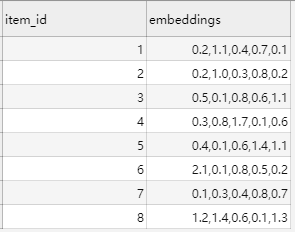
item_embeddings
真实关联序列

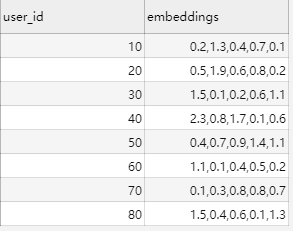
user_embeddings
配置流程
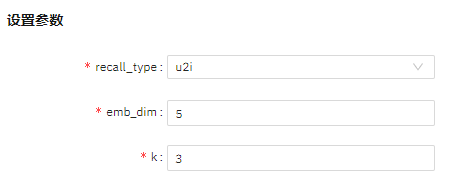
运行流程

参数设置
结果查看