

更新时间:2024-04-29 GMT+08:00
FM算法
概述
FM主要是解决稀疏数据下的特征组合问题,并且其预测的复杂度是线性的,对于连续和离散特征有较好的通用性。
公式为:
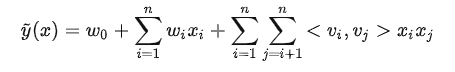
输入
参数 |
子参数 |
参数说明 |
|---|---|---|
inputs |
dataframe |
inputs为字典类型,dataframe为pyspark中的DataFrame类型对象 |
输出
spark pipeline类型的模型
参数说明
参数 |
参数含义 |
默认值 |
|---|---|---|
tensor_col_name |
特征列名称。 数据格式为key:value,多个特征使用英文逗号(,)分隔。例如1:1.0,3:1.0 |
无 |
label_col_name |
label列名。数据必须是数值类型。如果task取值为binary_classification,则label只能取0或1。 |
无 |
task |
FM算法的训练模式(分类、回归) |
binary_classification |
dim |
使用英文逗号(,)分隔的三个整数,分别表示0次项、线性项及二次项的长度。 |
1,1,8 |
num_epochs |
迭代数。 |
100 |
learn_rate |
学习率。 |
0.01 |
param_lambda |
使用英文逗号(,)分隔的三个浮点数,分别表示0次项、线性项及二次项的正则化系数。 |
0.2,0.2,0.2 |
init_stdev |
参数初始化标准差。 |
0.01 |
mini_batch_fraction |
训练过程中,最小分片大小。 |
1 |
tol |
判断收敛的忍受度。 |
0.1 |
pred_result_col_name |
预测结果列名。 |
predictResultCol |
pred_score_col_name |
预测得分列名(在分类模型中存在)。 |
predictScoreCol |
keep_col_names |
保存至输出结果表的列。 |
无 |
数据样例:

算链样例


当训练特征维度高于1w的样本,建议使用CU64G以上的资源。
父主题: 分类








