

读CSV文件
概述
读CSV文件支持从LOCAL、OBS、HDFS读取CSV类型的文件数据。
输入
无
输出
参数 |
子参数 |
参数说明 |
|---|---|---|
output |
output_port_1 |
output为字典类型,output_port_1为pyspark中的DataFrame类型对象,为算子读取的结果。 |
参数说明
参数名称 |
是否必选 |
参数说明 |
默认值 |
|---|---|---|---|
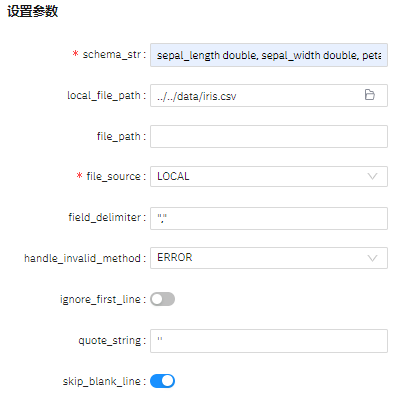
schema_str |
是 |
非空字符串 schema:配置每一列对应的数据类型,格式为colname0 coltype0[, colname1 coltype1[, ...]]。例如:f0 string,f1 bigint,f2 double。 注意:配置的数据类型需要与CSV文件每一列的数据类型保持一致,否则该列内容会读取失败。 |
无 |
local_file_path |
否 |
本地文件路径 非必须,可通过文件夹选取;仅当file_source为LOCAL时,该路径有效。 |
无 |
file_path |
否 |
读取CSV文件的路径
|
无 |
file_source |
否 |
支持LOCAL、OBS和OTHERS。范围:['LOCAL','OBS','OTHERS'] |
LOCAL |
field_delimiter |
否 |
字段分隔符;如果输入则必须为字符 |
, |
handle_invalid_method |
否 |
处理无效值的方法(无效值表示schema_str中设置的数据类型和csv中的不符),取值如下: 1.ERROR:抛出异常 2.SKIP:使用csv中的格式替换 |
ERROR |
ignore_first_line |
否 |
是否忽略第一行的数据。 如果原表中已有表头,则需要开启此开关,否则会报错。 |
FALSE |
quote_string |
否 |
引号字符,设置用于转义引号值的单个字符。 |
" |
row_delimiter |
否 |
行分隔符。 |
\n |
skip_blank_line |
否 |
是否忽略空行。 如果为True,该行数据全空时忽略;否则不忽略。 |
TRUE |

1. schema_str这个参数,相当于增加列名(如果csv没有列名,则增加列名,ignore_first_line需置为False) 或 重命名列名(如果csv有列名,可以改列名,ignore_first_line需置为True)。
2. 只支持string,bigint,double类型,之后如果是想改变数据类型,需使用新算子做类型转换;其中tinyint、smallint、int均为bigint类型,char、varchar、date等其他类型均为string类型。
3. 该算子默认以"\n"作为行分隔符,如果某一字段内部存在"\n",需要提前处理;例如;将"\n"提前替换为空格,防止读取失败。示例如下:
import pandas as pd
df = pd.read_csv("test.csv",index_col=0)
df = df.replace(to_replace=r'[\n\r]', value=' ', regex=True, inplace=True)
df.to_csv("output.csv")
样例
数据样本
5.1,3.5,1.4,0.2,Iris-setosa 5.0,2.0,3.5,1.0,Iris-versicolor 5.1,3.7,1.5,0.4,Iris-setosa 6.4,2.8,5.6,2.2,Iris-virginica 6.0,2.9,4.5,1.5,Iris-versicolor 4.9,3.0,1.4,0.2,Iris-setosa 5.7,2.6,3.5,1.0,Iris-versicolor 4.6,3.6,1.0,0.2,Iris-setosa 5.9,3.0,4.2,1.5,Iris-versicolor 6.3,2.8,5.1,1.5,Iris-virginica 4.7,3.2,1.3,0.2,Iris-setosa 5.1,3.3,1.7,0.5,Iris-setosa 5.5,2.4,3.8,1.1,Iris-versicolor
配置流程
运行流程

算法参数设置
schema_str: sepal_length double, sepal_width double, petal_length double, petal_width double, category string
查看结果









