

特征异常平滑
概述
特征异常平滑算子用于将数据中的异常数据平滑到一定的区间,可选择采用箱线图、阈值、百分位和z-score的方法确定平滑区间。

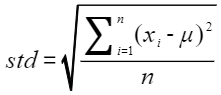

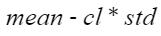
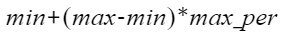


输入
参数 |
子参数 |
参数说明 |
|---|---|---|
inputs |
dataframe |
inputs为字典类型,dataframe为pyspark中的DataFrame类型对象。 |
输出
参数 |
子参数 |
参数说明 |
|---|---|---|
output |
output_port_1 |
output为字典类型,output_port_1为pyspark中的PipelineModel类型对象,特征异常平滑模型。 |
output |
output_port_2 |
output_port_2为pyspark中的DataFrame类型,为特征异常平滑结果。 |
参数说明
参数 |
是否必选 |
参数说明 |
默认值 |
|---|---|---|---|
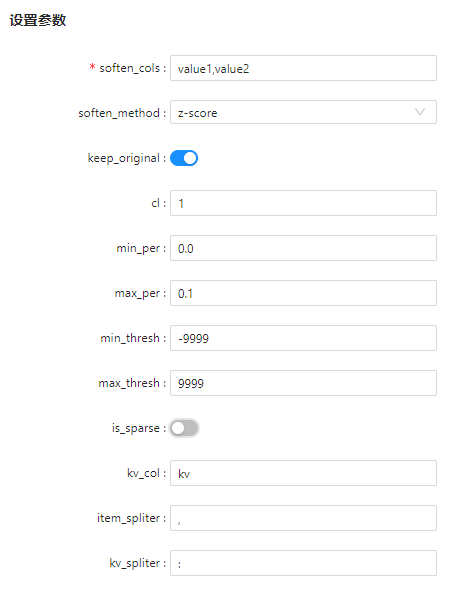
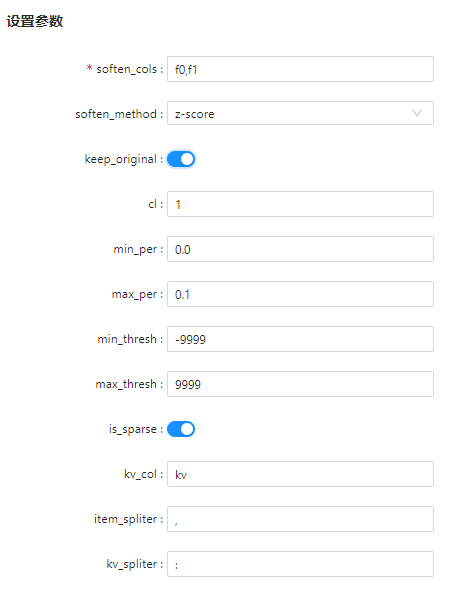
soften_cols |
是 |
需要进行特征异常平滑处理的列,逗号分隔。 |
无 |
soften_method |
是 |
特征平滑方法,可选z-score,min-max-per,min-max-thresh,boxplot。 |
"z-score" |
keep_original |
是 |
是否保留原始列,若保留则新增列,列名为原始列前加'soften_'。 |
False |
cl |
否 |
置信水平,当选择z-score方法时需要配置此参数。 |
1 |
min_per |
否 |
最低百分位。当平滑方法为min-max-per时需要配置该参数。 |
0.0 |
max_per |
否 |
最高百分位。当平滑方法为min-max-per时需要配置该参数。 |
0.1 |
min_thresh |
否 |
阈值最小值。当平滑方法为min-max-thresh时需要配置该参数。 |
-9999 |
max_thresh |
否 |
阈值最大值。当平滑方法为阈值平滑时需要配置该参数。 |
9999 |
is_sparse |
是 |
是否为k:v的稀疏特征, 若指定该列,soften_cols参数只支持选择稀疏特征列kv_col中的列名。 |
False |
kv_col |
否 |
若为稀疏特征,指定稀疏特征列名。 |
"kv" |
item_spliter |
否 |
稀疏特征的分隔符。 |
"," |
kv_spliter |
否 |
稀疏特征key和value的分隔符。 |
":" |
样例
数据样本
样例1 非稀疏数据

样例2 稀疏数据

配置流程
运行流程

参数设置
结果查看










