

更新时间:2024-04-29 GMT+08:00
过滤式特征选择
概述
过滤式特征选择根据特征对标签的重要性对特征进行筛选,特征重要性较高的特征,提升训练的精度和效率。
输入
参数 |
子参数 |
参数说明 |
|---|---|---|
inputs |
dataframe |
inputs为字典类型,dataframe为pyspark中的DataFrame类型对象 |
输出
参数 |
子参数 |
参数说明 |
|---|---|---|
output |
output_feature_importance |
dataframe类型的特征重要性结果 |
output |
output_selected_dataframe |
dataframe类型的特征筛选结果 |
参数说明
参数 |
是否必选 |
参数说明 |
默认值 |
|---|---|---|---|
feature_columns_str |
是 |
特征列列名,支持多列用','分隔 |
"” |
label_column |
是 |
标签列列名 |
"" |
discretization_columns_str |
否 |
需要进行离散化特征列列名,支持多列用','分隔 |
"" |
method |
是 |
过滤选择的方法,取值如下:
|
"" |
select_feature_num |
是 |
选择的TopN个特征,如果大于输入特征数,则输出所以特征 |
None |
discretization_method |
否 |
离散化连续特征方法,取值如下:
|
"" |
discretization_bin_num |
否 |
离散化连续特征区间数量 |
None |
is_sparse |
是 |
是否是K:V的稀疏特征 |
False |
kv_col |
否 |
稀疏特征列名 |
"" |
item_spliter |
否 |
K:V特征中每个item之间的分隔符 |
"," |
kv_spliter |
否 |
K:V特征中每个key与value之间的分隔符 |
":" |
样例一(常规数据)
数据样本

配置流程
运行流程

算法参数设置
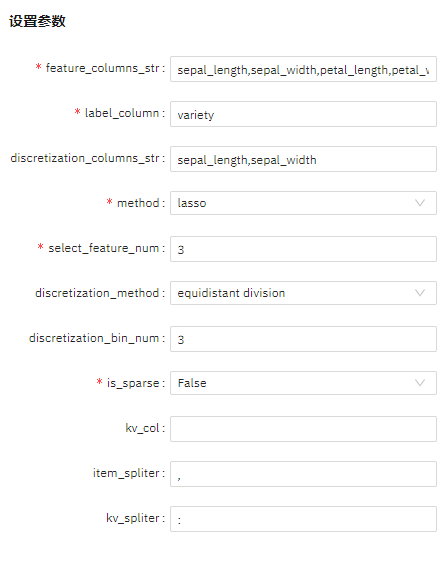
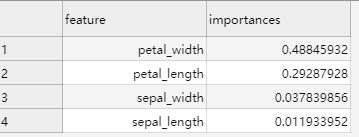
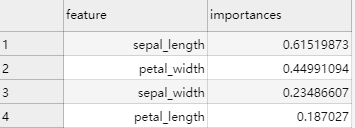
查看结果
样例二(KV稀疏数据)
数据样本

配置流程
运行流程

算法参数设置
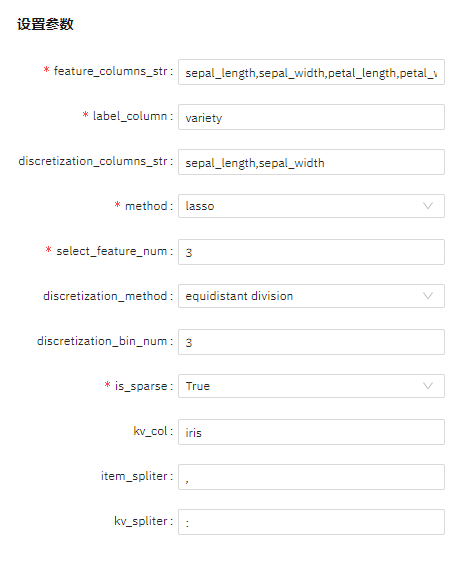
查看结果
父主题: 特征工程








