

更新时间:2023-05-05 GMT+08:00
TF-IDF
概述
“词频-逆文档频率”节点主要功能是计算某个词对于所属文档的重要程度。词频-逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF)算法规定某个词语的重要性与它在一个文档中出现的次数成正比,与该词语在语料库的所有文档中出现的频率成反比。给定语料库D,则文档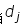 中的词语
中的词语 的
的 定义如下:
定义如下:

式中,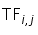 指词语
指词语 在文档
在文档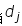 出现频率的归一化结果,
出现频率的归一化结果, 表示该词在文档dj中的出现次数,
表示该词在文档dj中的出现次数, 表示文件
表示文件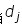 中所有词语的出现次数之和;
中所有词语的出现次数之和;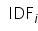 表示词语
表示词语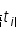 的逆向文件频率(Inverse Document Frequency),|D|表示语料库的文件总数,
的逆向文件频率(Inverse Document Frequency),|D|表示语料库的文件总数, 表示包含词语
表示包含词语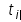 的文件数目。
的文件数目。
输入
参数 |
子参数 |
参数说明 |
|---|---|---|
inputs |
dataframe |
inputs为字典类型,dataframe为pyspark中的DataFrame类型对象 |
输出
spark pipeline类型的模型
参数说明
参数 |
子参数 |
参数说明 |
|---|---|---|
text_col |
- |
文本列所在的列名,默认为"text_col" |
tokenizer_col |
- |
对数据集文本列分词之后的结果列名,默认为"tokenizer_col" |
tf_col |
- |
对数据集应用HashingTF之后的结果列名,默认为"tf_col" |
idf_col |
- |
对数据集应用IDF之后的结果列名,默认为"idf_col" |
tf_binary |
- |
默认为False |
tf_num_features |
- |
HashingTF中的特征个数 |
idf_min_doc_freq |
- |
最小文档频率,默认为0 |
样例
inputs = {
"dataframe": None # @input {"label":"dataframe","type":"DataFrame"}
}
params = {
"inputs": inputs,
"text_col": "text_col", # @param {"label":"text_col","type":"string","required":"false","helpTip":""}
"tokenizer_col": "tokenizer_col", # @param {"label":"tokenizer_col","type":"string","required":"false","helpTip":""}
"tf_col": "tf_col", # @param {"label":"tf_col","type":"string","required":"false","helpTip":""}
"idf_col": "idf_col", # @param {"label":"idf_col","type":"string","required":"false","helpTip":""}
"tf_binary": False, # @param {"label":"tf_binary","type":"boolean","required":"false","helpTip":""}
"tf_num_features": 1 << 18, # @param {"label":"tf_num_features","type":"integer","required":"true","range":"(0,2147483647]","helpTip":""}
"idf_min_doc_freq": 0 # @param {"label":"idf_min_doc_freq","type":"integer","required":"true","range":"(0,2147483647]","helpTip":""}
}
tf_idf____id___ = MLSTFIDF(**params)
tf_idf____id___.run()
# @output {"label":"pipeline_model","name":"tf_idf____id___.get_outputs()['output_port_1']","type":"PipelineModel"}
# @output {"label":"dataframe","name":"tf_idf____id___.get_outputs()['output_port_2']","type":"DataFrame"}
父主题: 文本








