

多层感知机分类
概述
“多层感知机分类”节点可用于建立一个基于前馈人工神经网络的分类模型。
前馈人工神经网络采用一种单向多层结构。其中每一层包含若干个神经元,同一层的神经元之间没有互相连接,层间信息的传送只沿一个方向进行。其中第一层称为输入层。最后一层为输出层,中间为隐层。K+1层前馈神经网络矩阵形式如下表示,其中X为特征集,w为权重值,b为偏置量,y为预测值。

中间层的节点使用sigmod函数:
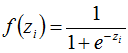
输出层的节点使用softmax函数:
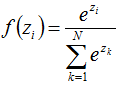
输出层中的节点个数对应类别数量。
输入
参数 |
子参数 |
参数说明 |
|---|---|---|
inputs |
dataframe |
inputs为字典类型,dataframe为pyspark中的DataFrame类型对象 |
输出
spark pipeline类型的模型
参数说明
参数 |
子参数 |
参数说明 |
|---|---|---|
b_use_default_encoder |
- |
是否使用默认编码,默认为True |
input_features_str |
- |
输入的列名以逗号分隔组成的字符串,例如: "column_a" "column_a,column_b" |
label_col |
- |
目标列 |
classifier_label_index_col |
- |
目标列经过标签编码后的新的列名,默认为"label_index" |
classifier_feature_vector_col |
- |
算子输入的特征向量列的列名,默认为"model_features" |
prediction_col |
- |
算子输出的预测label的列名,默认为"prediction" |
prediction_index_col |
- |
算子输出的预测label对应的标签列,默认为"prediction_index" |
max_iter |
- |
最大迭代次数,默认为100 |
tol |
- |
收敛阈值,默认为1e-6 |
seed |
- |
随机数种子,默认为0 |
layers_str |
- |
层的个数用逗号分隔组成的字符串,例如: "2,3,4" "3" |
step_size |
- |
步长,默认为0.03 |
solver |
- |
用来优化的处理算法,支持l-bfgs、gd,默认为"l-bfgs" |
initial_weights_str |
- |
初始化权重用逗号分隔组成的字符串,例如: "0.01" "0.01,0.02,0.04" |
样例
inputs = {
"dataframe": None # @input {"label":"dataframe","type":"DataFrame"}
}
params = {
"inputs": inputs,
"b_output_action": True,
"b_use_default_encoder": True, # @param {"label": "b_use_default_encoder", "type": "boolean", "required": "true", "helpTip": ""}
"input_features_str": "", # @param {"label": "input_features_str", "type": "string", "required": "false", "helpTip": ""}
"outer_pipeline_stages": None,
"label_col": "", # @param {"label": "label_col", "type": "string", "required": "true", "helpTip": ""}
"classifier_label_index_col": "label_index", # @param {"label": "classifier_label_index_col", "type": "string", "required": "true", "helpTip": ""}
"classifier_feature_vector_col": "model_features", # @param {"label": "classifier_feature_vector_col", "type": "string", "required": "true", "helpTip": ""}
"prediction_col": "prediction", # @param {"label": "prediction_col", "type": "string", "required": "true", "helpTip": ""}
"prediction_index_col": "prediction_index", # @param {"label": "prediction_index_col", "type": "string", "required": "true", "helpTip": ""}
"max_iter": 100, # @param {"label": "max_iter", "type": "integer", "required": "true", "range": "(0,2147483647]", "helpTip": ""}
"tol": 1e-6, # @param {"label": "tol", "type": "number", "required": "true", "range": "(0,none)", "helpTip": ""}
"seed": 0, # @param {"label": "seed", "type": "integer", "required": "false", "range": "[0,2147483647]", "helpTip": ""}
"layers_str": "", # @param {"label": "layers_str", "type": "string", "required": "false", "helpTip": ""}
"block_size": 128,
"step_size": 0.03, # @param {"label": "step_size", "type": "number", "required": "true", "range": "(0,none)", "helpTip": ""}
"solver": "l-bfgs", # @param {"label": "solver", "type": "enum", "required": "true", "options": "gd,l-bfgs", "helpTip": ""}
"initial_weights_str": "" # @param {"label": "initial_weights_str", "type": "string", "required": "false", "helpTip": ""}
}
multilayer_perception_classifier____id___ = MLSMultilayerPerceptronClassifier(**params)
multilayer_perception_classifier____id___.run()
# @output {"label":"pipeline_model","name":"multilayer_perception_classifier____id___.get_outputs()['output_port_1']","type":"PipelineModel"}








