

更新时间:2023-05-05 GMT+08:00
线性支持向量机分类
概述
“支持向量机分类”节点构造一个线性支持向量机模型,支持二分类和多分类。该节点采用Trust Region Newton Method(TRON)算法优化L2-SVM模型,更适用于大规模数据的建模,模型训练效率更高。
算法实现方式的简介如下:





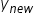

输入
参数 |
子参数 |
参数说明 |
|---|---|---|
inputs |
dataframe |
inputs为字典类型,dataframe为pyspark中的DataFrame类型对象 |
输出
spark pipeline类型的模型
参数说明
参数 |
子参数 |
参数说明 |
|---|---|---|
b_use_default_encoder |
- |
是否使用默认编码,默认为True |
input_features_str |
- |
输入的列名以逗号分隔组成的字符串,例如: "column_a" "column_a,column_b" |
label_col |
- |
目标列 |
classifier_label_index_col |
- |
目标列经过标签编码后的新的列名,默认为"label_index" |
classifier_feature_vector_col |
- |
算子输入的特征向量列的列名,默认为"model_features" |
prediction_index_col |
- |
算子输出的预测label对应的标签列,默认为"prediction_index" |
prediction_col |
- |
算子输出的预测label的列名,默认为"prediction" |
max_iter |
- |
最大迭代次数,默认为100 |
reg_param |
- |
正则化系数,默认为0.0 |
tol |
- |
收敛阈值,默认为1e-6 |
fit_intercept |
- |
默认为True |
standardization |
- |
训练模型之前是否对训练特征标准化,默认为True |
aggregation_depth |
- |
聚合时的深度,默认为2 |
样例
inputs = {
"dataframe": None # @input {"label":"dataframe","type":"DataFrame"}
}
params = {
"inputs": inputs,
"b_output_action": True,
"b_use_default_encoder": True, # @param {"label": "b_use_default_encoder", "type": "boolean", "required": "true", "helpTip": ""}
"input_features_str": "", # @param {"label": "input_features_str", "type": "string", "required": "false", "helpTip": ""}
"outer_pipeline_stages": None,
"label_col": "", # @param {"label": "label_col", "type": "string", "required": "true", "helpTip": "target label column"}
"classifier_label_index_col": "label_index", # @param {"label": "classifier_label_index_col", "type": "string", "required": "true", "helpTip": ""}
"classifier_feature_vector_col": "model_features", # @param {"label": "classifier_feature_vector_col", "type": "string", "required": "true", "helpTip": ""}
"prediction_index_col": "prediction_index", # @param {"label": "prediction_index_col", "type": "string", "required": "true", "helpTip": ""}
"prediction_col": "prediction", # @param {"label": "prediction_col", "type": "string", "required": "true", "helpTip": ""}
"max_iter": 100, # @param {"label": "max_iter", "type": "integer", "required": "true", "range": "(0,2147483647]", "helpTip": ""}
"reg_param": 0.0, # @param {"label": "reg_param", "type": "number", "required": "true", "range": "[0,none)", "helpTip": ""}
"tol": 1e-6, # @param {"label": "tol", "type": "number", "required": "true", "range": "(0,none)", "helpTip": ""}
"fit_intercept": True, # @param {"label": "fit_intercept", "type": "boolean", "required": "true", "helpTip": ""}
"standardization": True, # @param {"label": "standardization", "type": "boolean", "required": "true", "helpTip": ""}
"aggregation_depth": 2 # @param {"label": "aggregation_depth", "type": "integer", "required": "true", "range": "(0,2147483647]", "helpTip": ""}
}
linear_svc_classifier____id___ = MLSLinearSVCClassifier(**params)
linear_svc_classifier____id___.run()
# @output {"label":"pipeline_model","name":"linear_svc_classifier____id___.get_outputs()['output_port_1']","type":"PipelineModel"}
父主题: 分类





