数据没有更新
- Hudi表默认使用DefaultHoodieRecordPayload做更新行为计算,增量数据的preCombine字段比存量数据的preCombine字段小就不会更新,大于或者等于都会更新,不同的Payload有不同的更新行为。

- 写入操作没有提交或者失败,增量数据读不到。
- 提交失败,数据可以读不到:
- 提交成功,数据可以读到:
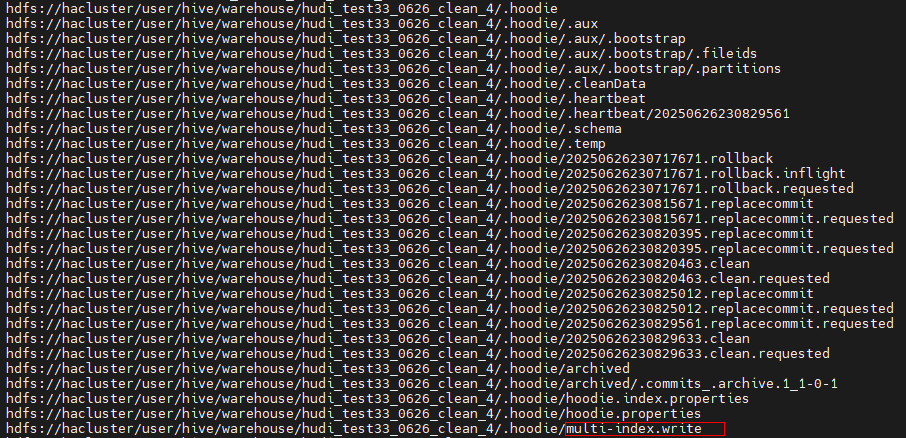
- 使用不同的索引写同一个Hudi表,数据没有更新,而且会把Hudi表写坏(常出现在Flink+Spark混写场景)。
多索引写Hudi表,会生成multi-index.write标记文件,然后写任务会报错。
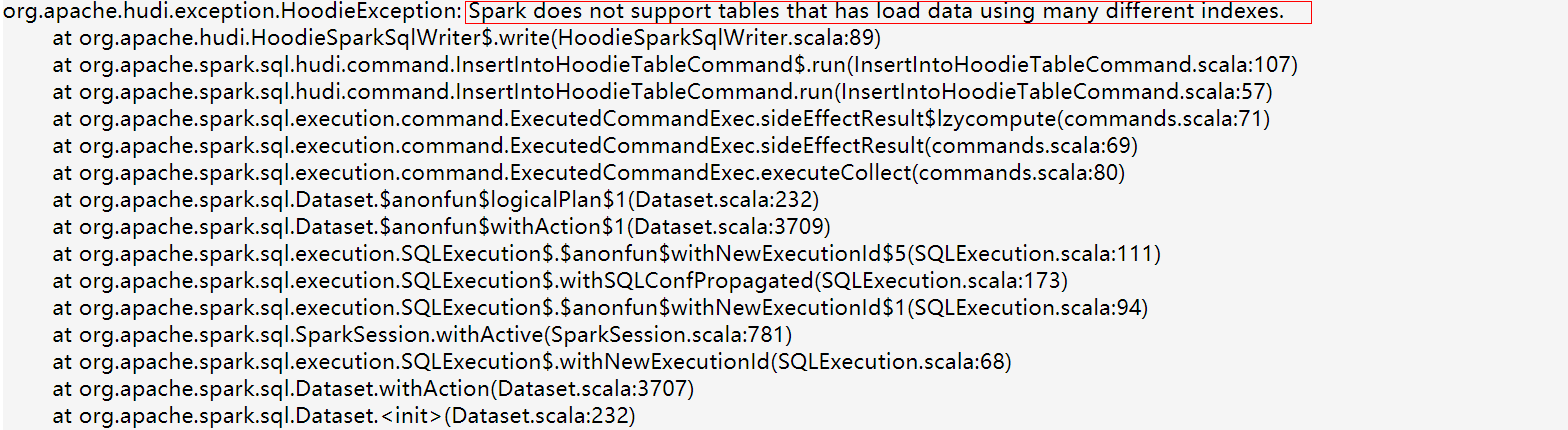
- 多种ComplexKeyGenerator写同一个Hudi表,数据没有更新,而且会把Hudi表写坏(常出现在用户自己做二次开发的场景,绕过了属性校验导致)。
- 查看Hudi表的hoodie.properties文件,确认Hudi表的KeyGenerator类。

- 查询Hudi表的_hoodie_record_key元字段的值,同一条数据使用不同的KeyGenerator类去写入,生成的_hoodie_record_key元字段的值是不一样的,会影响更新。
org.apache.hudi.keygen.ComplexKeyGenerator

org.apache.hudi.keygen.SimpleKeyGenerator

死锁
Caused by: org.apache.hudi.exception.HoodieLockException: FAILED_TO_ACQUIRE lock atZkBasePath = /hudi/lock/write, lock key = xxx.db_xxx_table
- SparkSql手动释放ZooKeeper锁。
找到日志里打印出来的lock key,再执行下面的SQL命令:
call remove_lock_on_zookeeper(znode => "/hudi/lock/write/${lock key}"); - 登录MRS客户端,source环境变量,执行zk-cli.sh进入ZooKeeper后台去手动删除znode。
BUCKET桶ID重复
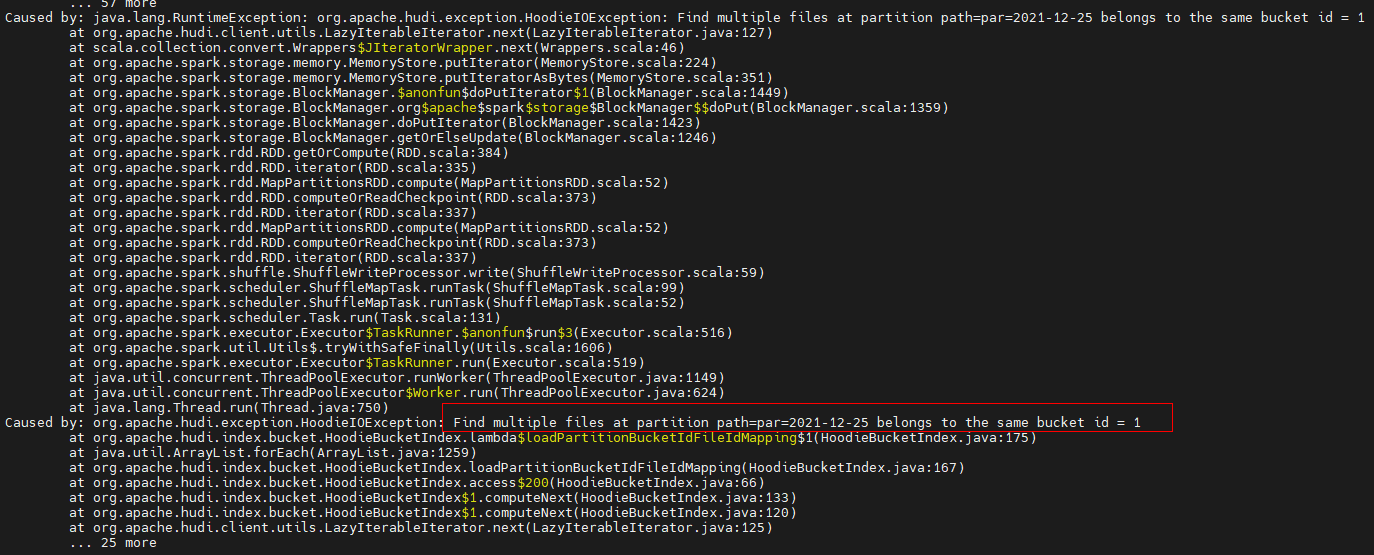
报错堆栈:
可得知是2021-12-25分区下的00000001号桶有多个不同的File ID。
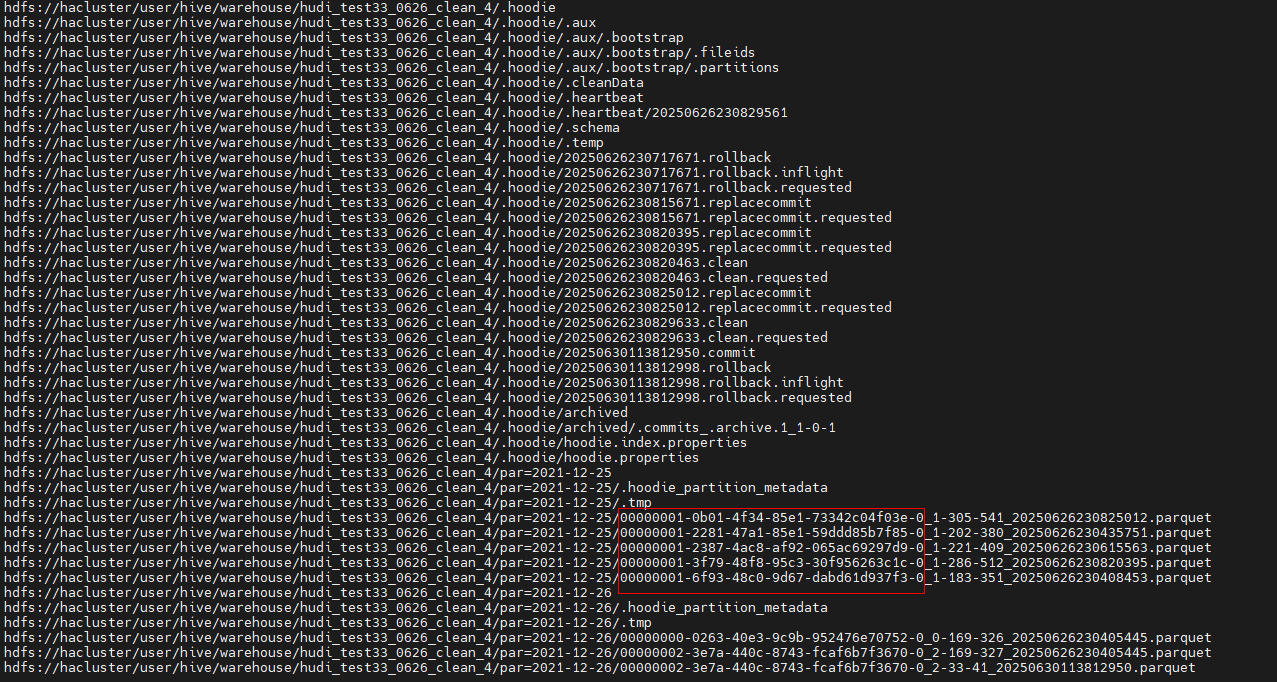
- 场景一:insert overwrite写BUCKET索引表
每次insert overwrite都会产生一个replacecommit文件,在对应的桶下都会产生一个parquet文件,当replacecommit元数据文件被归档,但parquet文件还没有被clean的时候,就会出现此问题。
解决方法:排查业务clean和archive的设置参数,保证clean在archive之前运行。
- 场景二:bulk_insert写BUCKET索引表
对于BUCKET索引表,只能使用bulk_insert方式写入一次,写入2次以上就会出现此问题,只能重新建表。
- 场景三:任务1,写Hudi表A;任务2,truncate Hudi表A + 写Hudi表A
当任务1和任务2同时执行,就会出现此问题,需要调整业务的依赖关系,不能并发执行。
属性校验
- 主键字段“/preCombine”字段不能为空。
排查存量数据和增量数据中主键字段的值是否有空和null。

排查存量数据和增量数据中preCombine字段的值是否有空和null。

- hoodie.properties文件中属性值与Table Properties中的值,或者与Session中手动指定的值不一致,发生冲突。
必须与hoodie.properties文件中属性值一致,否则无法写入,因为这些属性会影响数据一致性,需要保持统一。