

Flink任务开发建议
高可用性下考虑提高Checkpoint保存数
Checkpoint保存数默认是1,也就是只保存最新的Checkpoint的状态文件,当进行状态恢复时,如果最新的Checkpoint文件不可用(比如HDFS文件所有副本都损坏或者其他原因),那么状态恢复就会失败。如果设置Checkpoint保存数为2,即使最新的Checkpoint恢复失败,那么Flink会回滚到之前那一次Checkpoint的状态文件进行恢复。所以可以增加Checkpoint保存数。
【示例】配置Checkpoint文件保存数为2:
state.checkpoints.num-retained: 2
生产环境使用增量Rocksdb作为State Backend
Flink提供了三种状态后端:MemoryStateBackend,FsStateBackend,和RocksDBStateBackend。
- MemoryStateBackend是将state存储在JobManager的Java堆上,每个状态的大小不能超过akka帧的大小,且总量不能超过JobManager的堆内存大小。所以只适合于本地开发调试,或状态大小有限的一些小状态的场景。
- FsStateBackend是文件系统状态后端,正常情况下将state存储在TaskManager堆内存中,当Checkpoint时将state存储在文件系统上,而JobManager内存中存储极少的元数据(高可用场景下存储在ZooKeeper)。因为文件系统的存储空间足够,适合于大状态,长窗口,或大键值状态的有状态处理任务,也适合于高可用方案。
- RocksDBStateBackend是内嵌数据库后端,正常情况下state存储在RocksDB数据库中,该数据库数据放在本地磁盘上,在Checkpoint时将state存储在配置的文件系统上而JobManager内存中存储极少的元数据(高可用场景下存储在ZooKeeper),同时是唯一一个可以增量Checkpoint的状态后端,除了适合于FsStateBackend的场景,还适用于超大状态的场景。
| 类别 | MemoryStateBackend | FsStateBackend | RocksDBStateBackend |
|---|---|---|---|
| 方式 | Checkpoint数据直接返回给Master节点,不落盘 | 数据写入文件,将文件路径传给Master | 数据写入文件,将文件路径传给Master |
| 存储 | 堆内存 | 堆内存 | Rocksdb(本地磁盘) |
| 性能 | 相比其他方式最好(一般不用) | 性能好 | 性能不好 |
| 缺点 | 数据量小、易丢失 | 容易出现OOM风险 | 需要读写、序列化、IO等耗时 |
| 是否支持增量 | 不支持 | 不支持 | 支持 |
【示例】配置RockDBStateBackend(flink-conf.yaml):
state.backend: rocksdb state.checkpoints.dir: hdfs://namenode:40010/flink/checkpoints
使用EXACTLY ONCE流处理语义保证端到端的一致性
流处理语义有三种:EXACTLY ONCE、AT LEAST ONCE、AT MOST ONCE。
- AT MOST ONCE:无法保证数据处理的完整性,但性能相比最好。
- AT LEAST ONCE:可以保证数据处理的完整性,但无法保证数据处理的准确性,性能适中。
- EXACTLY ONCE:可以保证数据处理的准确性,但性能最差。
首先需要确认能否保证EXACTLY_ONCE(严格一次),因为端到端EXACTLY ONCE语义需要输入数据源的可回放(例如Kafka可回放数据),输出数据源的事务性(例如MySQL可原子性写入数据)。在无法满足这些条件的情况下,可以视情况将其降级为AT LEAST ONCE或者AT MOST ONCE。
- 在无法满足输入源的可回放时,只能保证AT MOST ONCE。
- 在无法满足输出目的的原子性写入时,只能保证AT LEAST ONCE。
【示例】API方式设置Exactly once语义:
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
【示例】资源文件方式设置Exactly once语义:
# checkpoint的语义 execution.checkpointing.mode: EXACTLY_ONCE
通过查看监控信息定位Back Pressure点
Flink提供了很多的监控指标,根据这些指标可以分析任务过程中的性能状况及瓶颈。
【示例】配置采样的样本数和时间间隔:
# 有效地反压结果被废弃并重新进行采样的时间,单位ms web.backpressure.refresh-interval: 60000 # 用于确定反压采样的样本数 web.backpressure.num-samples: 100 # 用于确定反压采样的间隔时间,单位ms web.backpressure.delay-between-samples: 50
可以在Job的Overview选项卡后面查看BackPressure,如下图表示采样进行中,默认情况下,大约需要5秒完成采样。

如下图显示“OK”表示没有反压,“HIGH”表示对应SubTask被反压。


使用Hive SQL时如果Flink语法不兼容则可切换Hive方言
当前Flink支持的SQL语法解析引擎有default和Hive两种,第一种为Flink原生SQL语言,第二种是Hive SQL语言。因为部分Hive语法的DDL和DML无法用Flink SQL运行,所以遇到这种SQL可直接切换成Hive的dialect。使用Hive dialect需要注意:
- Hive dialect只能用于操作Hive表,不能用于普通表。Hive方言应与HiveCatalog一起使用。
- 虽然所有Hive版本都支持相同的语法,但是是否有特定功能仍然取决于使用的Hive版本。例如仅在Hive-2.7.0或更高版本中支持更新数据库位置。
- Hive和Calcite具有不同的保留关键字。例如default在Calcite中是保留关键字,在Hive中是非保留关键字。所以在使用Hive dialect时,必须使用反引号(`)引用此类关键字,才能将其用作标识符。
- 在Hive中不能查询在Flink中创建的视图。
【示例】修改SQL解析为Hive语法(sql-submit-defaults.yaml):
configuration: table.sql-dialect: hive
中小规模数据量维度表可以采用内存维度表(如Hudi)
- 内存维度表:将维度数据加载到内存当中,每个TM都会加载全量的数据,在内存内实现数据点查关联。若数据量过大,需要给TM分配大的内存空间,否则容易导致作业异常。
- 外置维度表:将维度数据存在高速的K-V数据库中,通过远程的K-V查询实现点查关联,常用的开源K-V库有HBase。
- 状态维度表:将维度表数据当做流表,实时读入到流式作业当中,通过数据的回撤流能力实现维度更新和数据不对齐场景下的数据一致性保证。维度表保存时间比较长,当前Flink on Hudi能力可以针对Hudi作为维度表单独设置TTL时长。
| 维度 | 内存维度表(hive/hudi表) | 外置维度表(HBase) | 状态维度表 |
|---|---|---|---|
| 性能 | 非常高(毫秒内) | 中(毫秒级) | 高(毫秒内~毫秒级) |
| 数据量 | 小,建议单个TM保持1GB以内 | 大,TB级 | 中,GB级 |
| 存储资源 | 内存消耗大,单个TM全量存储 | 外置存储,无存储资源消耗 | 各TM分散存储,内存+磁盘存储 |
| 时效性 | 周期性数据加载,时效低 | 相对高 | 高 |
| 关联数据结果 | 低 | 中 | - |
大数据量的维度表建议采用HBase
数据量比较大,而且不要数据高一致的场景,可以采用HBase类的KV库提供维度表点查关联能力。
由于K-V库的数据需由另外的作业写入,与当前的Flink作业会存在一定的时差,容易导致当前Flink作业查询K-V库时不是最新的数据,且由于lookup查询不支持回撤,关联的结果存在一致性问题。
维度表要求高数据一致性采用流表作为维度表
基于Hudi作为维度source表,可以实现维度表单独设置TTL时长,不跟随作业的整体TTL时间进行数据老化,从而保证维度数据可以长期保存在状态后端中。而且基于流表作为维度表可以基于Flink回撤机制实现数据的一致性。
SinkUpsertMaterializer算子的配置及使用场景
SinkUpsertMaterializer是一个用于处理Upsert(更新插入)语义的关键算子,主要作用是当Sink输出的是更新流且其upsert键与结果表的主键不匹配时,需要通过一个中间步骤消除乱序带来的影响,并基于结果表的主键生成新的主键对应的Changelog事件。
SinkUpsertMaterializer算子的配置
- SinkUpsertMaterializer算子通常由Flink自动推断并添加到执行计划中,在Sink算子之前,需要在sink表中指定主键。
CREATE TABLE output_table ( user_id STRING, pv BIGINT, uv BIGINT, PRIMARY KEY (user_id) NOT ENFORCED ) WITH (...);
- SinkUpsertMaterializer算子也可以通过table.exec.sink.upsert-materialize进行配置:
- auto(默认值):Flink会从正确性的角度推断出乱序是否存在,如果必要的话,则会添加SinkUpsertMaterializer。
- none:不使用。
- force:强制使用。即便结果表的DDL未指定主键,优化器也会插入SinkUpsertMaterializer状态节点,以确保数据的物理化处理。
以下场景需要使用SinkUpsertMaterializer算子
- 结果表定义主键,而写入该结果表的数据丢失了唯一性。
- 结果表的确立依赖于主键的设定,然而在数据输入过程中,其原有的顺序性却遭到破坏。例如双流Join时若一方数据未通过主键与另一方关联,而结果表的主键列又是基于另一方的主键列生成的,这便可能导致数据顺序的混乱。
以下场景不建议使用SinkUpsertMaterializer算子
通过设置join关联字段为source主键字段,使同key的数据在一个算子关联,可以不使用SinkUpsertMaterializer也能保证输出顺序。

SinkUpsertMaterializer虽然解决了Sink端Changelog事件乱序问题,但其在状态后端维护了一个RowData列表。这可能会导致状态过大并增加状态访问I/O的开销,最终影响作业的吞吐量。因此,应尽量避免使用它。
ChangelogNormalize算子的配置及使用场景
ChangelogNormalize是一个用于处理变更日志(Changelog)数据流的关键算子,主要用于对涉及主键语义的数据变更日志进行标准化处理,通过该算子,可以有效地整合和优化数据变更记录,确保数据的一致性和准确性。
ChangelogNormalize算子的配置
ChangelogNormalize是优化器自动生成的,且没有关闭功能。只有当source包含主键,并且source的Changelog mode为UPSERT时优化器才会添加。
以下场景需要使用ChangelogNormalize算子
- 使用了带有主键的upsert源表,需要输出完整的Changelog消息。
在遇到被更新或删除的文档时,查表即可得知变更前的状态,如图所示:

- 对CDC事件的日志去重。需要将“table.exec.source.cdc-events-duplicate”设置为“true”。
ChangelogNormalize算子使用ValueState来存储当前主键下最新的整行记录,更新状态并向下游发送变更的过程如下图所示。
处理第二条-U(2, 'Jerry', 77)时State已经empty,说明截止目前+I/+UA和-D/-UB已经两两抵销,当前这条retract消息是重复的,可以丢弃。
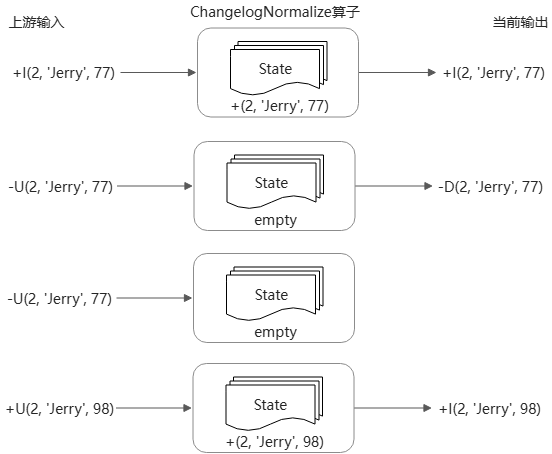
和SinkUpsertMaterializer算子一样,ChangelogNormalize会在状态后端用ValueState存储主键的最新记录。从而增加状态访问I/O的开销,最终影响作业的吞吐量。因此,应尽量避免使用它。




