

更新时间:2024-04-18 GMT+08:00
Hudi简介
Apache Hudi(发音Hoodie)表示Hadoop Upserts Deletes and Incrementals。用来管理Hadoop大数据体系下存储在DFS上大型分析数据集。
Hudi不是单纯的数据格式,而是一套数据访问方法(类似GaussDB(DWS)存储的access层),在Apache Hudi 0.9版本,大数据的Spark,Flink等组件都单独实现各自客户端。Hudi的逻辑存储如下图所示:
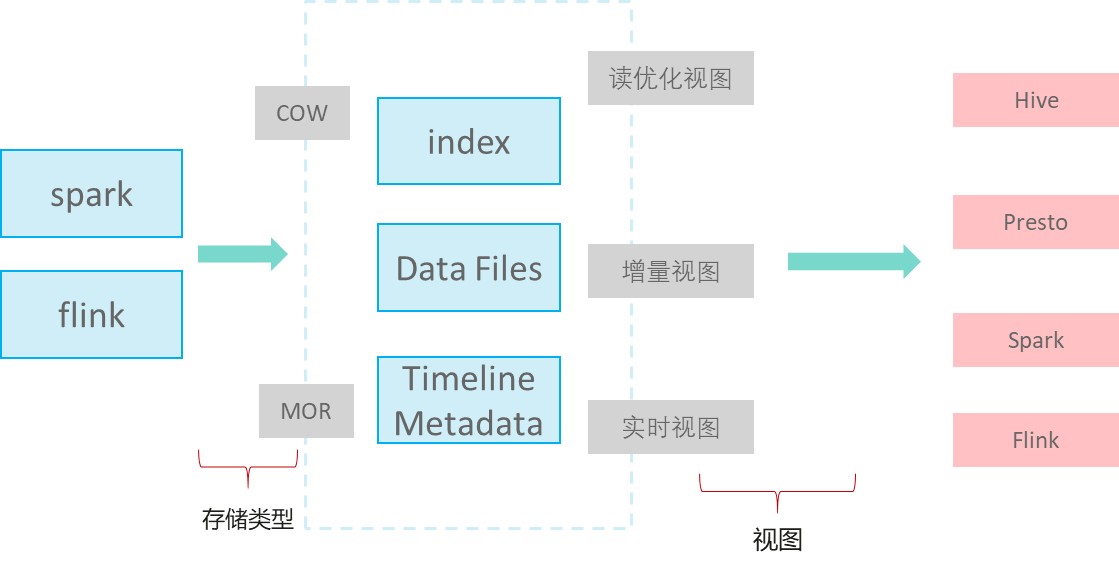
- 写入模式
MOR:读时复制,对于UPDATE&DELETE增量写delta log文件,分析时进行base和delta log文件合并,异步compaction合并文件。
父主题: SQL on Hudi








