

GaussDB(DWS) WITH表达式
WITH表达式用于定义在大型查询中使用的辅助语句,这些辅助语句通常被称为公共表达式或CTE(即common table expr),可以理解为一个带名称的子查询,之后该子查询可以以其名称在查询中被多次引用。
WITH表达式中的辅助语句可以是SELECT、INSERT、UPDATE或DELETE,并且WITH子句本身也可以被附加到一个主语句中,主语句可以是SELECT、INSERT或DELETE。
WITH中的SELECT
在WITH子句中使用SELECT的相关信息。
语法格式
1
|
[WITH [RECURSIVE] with_query [,…] ] SELECT … |
其中,with_query的语法为:
1 2 |
with_query_name [ ( column_name [, ...] ) ] AS [ [ NOT ] MATERIALIZED ] ( {select | values | insert | update | delete} ) |

- 显示指定MATERIALIZED时,将子查询执行一次,并将其结果集进行物化;指定NOT MATERIALIZED时,则将其子查询替换到主查询中的引用处。
- 每个CTE的AS语句指定的SQL语句,必须是可以返回查询结果的语句,可以是普通的SELECT查询语句,也可以是INSERT、UPDATE、DELETE、VALUES等其它数据修改语句,使用数据修改语句时需要通过RETURNING子句返回元组。例如:
1WITH s AS (INSERT INTO t VALUES(1) RETURNING a) SELECT * FROM s;
- 单个WITH表达式表示一个SQL语句块中的CTE定义,可以同时定义多个CTE,每个CTE可以指定列名,也可以默认使用查询输出列的别名。例如:
1WITH s1(a, b) AS (SELECT x, y FROM t1), s2 AS (SELECT x, y FROM t2) SELECT * FROM s1 JOIN s2 ON s1.a=s2.x;
该语句中定义了两个CTE,s1和s2,其中s1指定了列名为a,b,s2未指定列名,则列名为输出列名x,y。
- 每个CTE可以在主查询中引用0次、1次或多次。
- 同一个语句块中不能出现同名的CTE,但不同语句块中可以出现同名的CTE,此时,语句中引用的CTE则是距离引用位置最近的语句块中的CTE。
- 由于SQL语句中可能包含多个SQL语句块,每个语句块都可以包含一个WITH表达式,每个WITH表达式中的CTE可以在当前语句块、当前语句块的后续CTE中,以及子层语句块中引用,但不能在父层语句块中引用。由于每个CTE的定义也是个语句块,因此也支持在该语句块中定义WITH表达式。
WITH中SELECT的基本价值是将复杂的查询分解称为简单的部分。示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
WITH regional_sales AS ( SELECT region, SUM(amount) AS total_sales FROM orders GROUP BY region ), top_regions AS ( SELECT region FROM regional_sales WHERE total_sales > (SELECT SUM(total_sales)/10 FROM regional_sales) ) SELECT region, product, SUM(quantity) AS product_units, SUM(amount) AS product_sales FROM orders WHERE region IN (SELECT region FROM top_regions) GROUP BY region, product; |
WITH子句定义了两个辅助语句regional_sales和top_regions,其中regional_sales的输出用在top_regions中而top_regions的输出用在主SELECT查询。这个例子可以不用WITH来书写,但是就必须要用两层嵌套的子SELECT,使得查询更长更难以维护。
WITH递归查询
通过声明RECURSIVE关键字,一个WITH查询可以引用它自己的输出。
递归WITH查询的通常形式如下:
1
|
non_recursive_term UNION [ALL] recursive_term |
其中:UNION在合并集合时会执行去重操作,而UNION ALLL则直接将结果集合并、不执行去重;只有递归项能够包含对于查询自身输出的引用。
使用递归WITH时,必须确保查询的递归项最终不会返回元组,否则查询将无限循环。
使用表tree来存储下图中的所有节点信息:
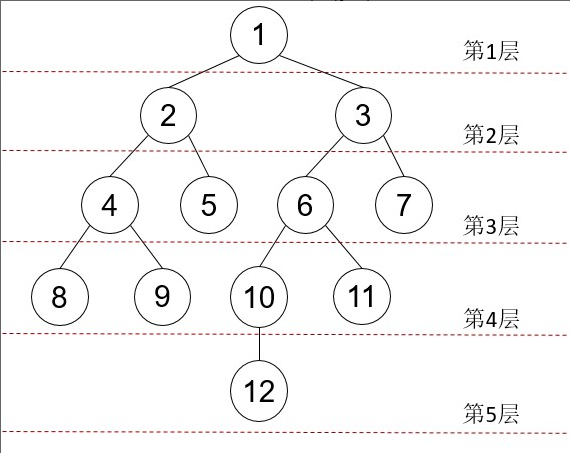
表定义语句如下:
1
|
CREATE TABLE tree(id INT, parentid INT); |
表中数据如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
INSERT INTO tree VALUES(1,0),(2,1),(3,1),(4,2),(5,2),(6,3),(7,3),(8,4),(9,4),(10,6),(11,6),(12,10); SELECT * FROM tree; id | parentid ----+---------- 1 | 0 2 | 1 3 | 1 4 | 2 5 | 2 6 | 3 7 | 3 8 | 4 9 | 4 10 | 6 11 | 6 12 | 10 (12 rows) |
通过以下WITH RECURSIVE语句,我们可以返回从顶层1号节点开始,整个树的节点,以及层次信息:
1 2 3 4 5 6 7 8 9 10 11 |
WITH RECURSIVE nodeset AS ( -- recursive initializing query SELECT id, parentid, 1 AS level FROM tree WHERE id = 1 UNION ALL -- recursive join query SELECT tree.id, tree.parentid, level + 1 FROM tree, nodeset WHERE tree.parentid = nodeset.id ) SELECT * FROM nodeset ORDER BY id; |
上述查询中,我们可以看出,一个典型的WITH RECURSIVE表达式包含至少一个递归查询的CTE,该CTE中的定义为一个UNION ALL集合操作,第一个分支为递归起始查询,第二个分支为递归关联查询,需要自引用第一部分进行不断递归关联。该语句执行时,递归起始查询执行一次,关联查询执行若干次并将结果叠加到起始查询结果集中,直到某一些关联查询结果为空,则返回。
上述查询的执行结果如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
id | parentid | level ----+----------+------- 1 | 0 | 1 2 | 1 | 2 3 | 1 | 2 4 | 2 | 3 5 | 2 | 3 6 | 3 | 3 7 | 3 | 3 8 | 4 | 4 9 | 4 | 4 10 | 6 | 4 11 | 6 | 4 12 | 10 | 5 (12 rows) |
从返回结果可以看出,起始查询结果包含level=1的结果集,关联查询执行了五次,前四次分别输出level=2,3,4,5的结果集,在第五次执行时,由于没有parentid和输出结果集id相等的记录,也就是再没有多余的孩子节点,因此查询结束。

对于WITH RECURSIVE表达式,GaussDB(DWS)支持其分布式执行。由于WITH RECURSIVE涉及到循环运算,GaussDB(DWS)引入了参数max_recursive_times,用于控制WITH RECURSIVE的最大循环次数,默认值为200,超过该次数则报错。
WITH中的数据修改语句
在WITH子句中使用数据修改命令INSERT、UPDATE、DELETE。这允许用户在同一个查询中执行多个不同操作。示例如下所示:
1 2 3 4 5 6 |
WITH moved_tree AS ( DELETE FROM tree WHERE parentid = 4 RETURNING * ) INSERT INTO tree_log SELECT * FROM moved_tree; |
上述查询示例实际上从tree把行移动到tree_log。WITH中的DELETE删除来自tree的指定行,以它的RETURNING子句返回它们的内容,并且接着主查询读该输出并将它插入到tree_log。
WITH子句中的数据修改语句必须有RETURNING子句,用来返回RETURNING子句的输出,而不是数据修改语句的目标表,RETURNING子句形成了可以被查询的其余部分引用的临时表。如果一个WITH中的数据修改语句缺少一个RETURNING子句,则它形不成临时表并且不能在剩余的查询中被引用。
如果声明了RECURSIVE关键字,则不允许在数据修改语句中进行递归自引用。在某些情况中可以通过引用递归WITH的输出来绕过这个限制,例如:
1 2 3 4 5 6 7 8 9 |
WITH RECURSIVE included_parts(sub_part, part) AS ( SELECT sub_part, part FROM parts WHERE part = 'our_product' UNION ALL SELECT p.sub_part, p.part FROM included_parts pr, parts p WHERE p.part = pr.sub_part ) DELETE FROM parts WHERE part IN (SELECT part FROM included_parts); |
这个查询将会移除一个产品的所有直接或间接子部件。
WITH子句中的子语句与主查询同时执行。因此,在使用WITH中的数据修改语句时,指定更新的顺序实际是以不可预测的方式发生的。所有的语句都使用同一个快照中执行,语句的效果在目标表上不可见。这减轻了行更新的实际顺序的不可预见性的影响,并且意味着RETURNING数据是在不同WITH子语句和主查询之间传达改变的唯一方法。
本示例中外层SELECT可以返回更新之前的数据:
1 2 3 4 |
WITH t AS ( UPDATE tree SET id = id + 1 RETURNING * ) SELECT * FROM tree; |
本示例中外部SELECT将返回更新过的数据:
1 2 3 4 |
WITH t AS ( UPDATE tree SET id = id + 1 RETURNING * ) SELECT * FROM t; |
不支持在单个语句中更新同一行两次。这种语句的效果是不可预测的。如果只有一个修改发生了,但却不容易(有时也不可能)预测哪一个发生了修改。





