

更新时间:2024-07-03 GMT+08:00
规划存储模型
GaussDB支持行列混合存储。行、列存储模型各有优劣,建议根据实际情况选择。通常GaussDB用于TP场景的数据库,默认使用行存储,仅对执行复杂查询且数据量大的AP场景时,才使用列存储。
行存储是指将表按行存储到硬盘分区上,列存储是指将表按列存储到硬盘分区上。默认情况下,创建的表为行存储。行存储和列存储的差异请参见图1。
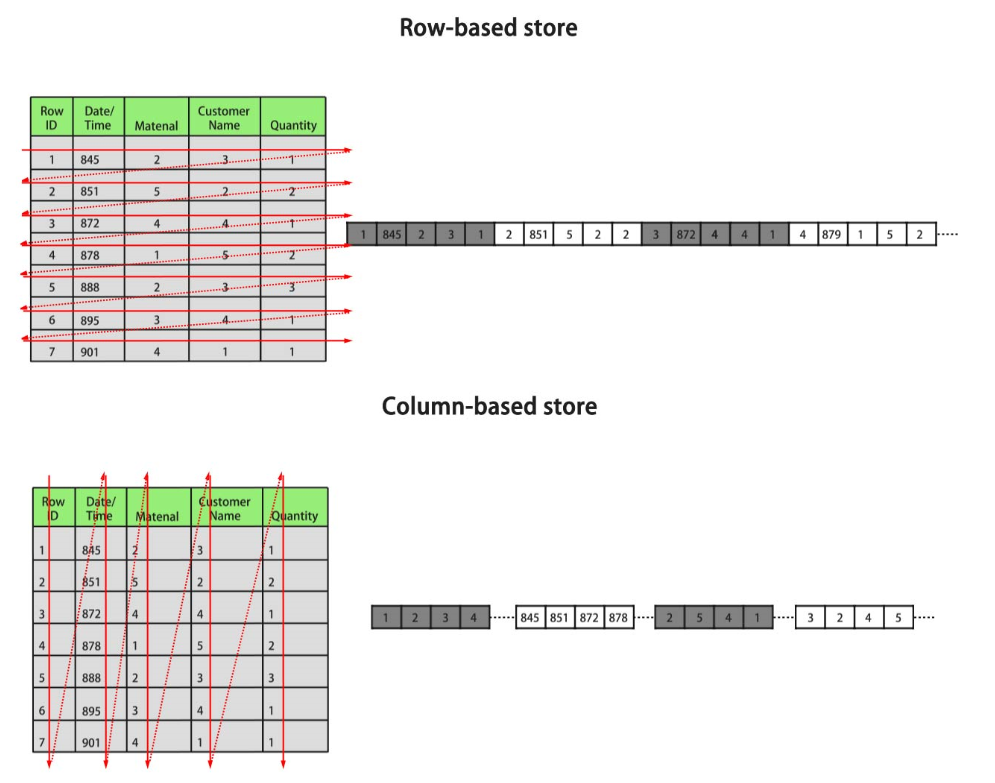
上图中,左上为行存表,右上为行存表在硬盘上的存储方式。左下为列存表,右下为列存表在硬盘上的存储方式。
行、列存储有如下优缺点:
|
存储模型 |
优点 |
缺点 |
|---|---|---|
|
行存 |
数据被保存在一起。INSERT/UPDATE容易。 |
选择(Selection)时即使只涉及某几列,所有数据也都会被读取。 |
|
列存 |
|
|
一般情况下,如果表的字段比较多(大宽表),查询中涉及到的列不多的情况下,适合列存储。如果表的字段个数比较少,查询大部分字段,那么选择行存储比较好。
|
存储类型 |
适用场景 |
|---|---|
|
行存 |
|
|
列存 |
|
行存表
默认创建表的类型。数据按行进行存储,即一行数据是连续存储。适用于对数据需要经常更新的场景。
1 2 3 4 5 6 7 8 9 |
openGauss=# CREATE TABLE customer_t1 ( state_ID CHAR(2), state_NAME VARCHAR2(40), area_ID NUMBER ); --删除表 openGauss=# DROP TABLE customer_t1; |
列存表
数据按列进行存储,即一列所有数据是连续存储的。单列查询IO小,比行存表占用更少的存储空间。适合数据批量插入、更新较少和以查询为主统计分析类的场景。列存表不适合点查询。
1 2 3 4 5 6 7 8 9 10 |
openGauss=# CREATE TABLE customer_t2 ( state_ID CHAR(2), state_NAME VARCHAR2(40), area_ID NUMBER ) WITH (ORIENTATION = COLUMN); --删除表 openGauss=# DROP TABLE customer_t2; |
父主题: 数据库使用





