

打造短视频营销文案创作助手
场景介绍
随着互联网的发展,短视频已成为了日常生活中不可或缺的一部分,凭借其独特的形式和丰富的内容吸引了大量流量,并为企业和个人提供了一个全新的营销平台。短视频用户希望借助大模型快速生成高质量的口播文案,以提升营销效果和效率。在这种场景下,用户只需提供一些基本信息,大模型就能生成需求的文案,从而大大提高文案的质量和效率。
除了短视频风格的口播文案,营销文案还可以根据需求生成不同风格的文案,如小红书风格、知乎风格,或爆款标题等。
选择基模型/基础功能模型
盘古-NLP-N2-基础功能模型
准备训练数据
本场景不涉及自监督训练,无需准备自监督数据。
微调数据来源:
- 来源一:真实业务场景数据。
- 来源二:基于大模型的数据泛化。基于目标场任务的分析,通过人工标注部分数据样例,然后利用大模型(如盘古提供的任意规格的基础功能模型)采用self-instruct等方式,泛化出更多的业务场景数据。
- 方法一:在大模型输入的Prompt中包含“人设赋予”、“任务描述”、“任务具体要求”和“输出格式要求”等部分后,模型通常能够生成质量较高的数据。示例如下:
大模型输入:
你是一名短视频的知名带货博主,你的日常工作在短视频平台上进行各类产品的带货直播。你很擅长根据一段简要的产品介绍,创作出高质量的带货口播。 请根据如下产品介绍,生成一篇字数不超过200个字的高质量带货口播,产品介绍如下: ``` %s ``` 生成的内容必须满足以下要求: 1.生成内容的字数要求为200个字左右; 2.生成的内容必须生动有趣、丰富多样; 3.生成内容的语言风格必须口语化; 4.生成的内容开头必须能足够引起观众的兴趣,比如可以采取对目标观众反问、对比等方式; 5.生成的内容结尾必须要引导观众购买; 6.生成的内容必须紧扣产品本身,突出产品的特点,不能出现不相关的内容; 7.生成的内容必须完整,必须涵盖产品介绍中的每个关键点,不能丢失任何有价值的细节; 8.生成的内容必须符合客观事实,不能存在事实性错误; 9.生成的内容必须语言通顺; 10.生成的内容中不能出现“带货口播”等这一类字样; 输出格式:口播如下: xxx
- 方法二:产品介绍可以来源于真实的产品信息,也可以通过in-context-learning方式生成。示例如下:
- 方法一:在大模型输入的Prompt中包含“人设赋予”、“任务描述”、“任务具体要求”和“输出格式要求”等部分后,模型通常能够生成质量较高的数据。示例如下:
微调数据要求:
- 数据格式样例:JSONL格式,每行是一条JSON,包含“context”和“target”两个字段。示例如下:
{"context":"轻便折叠户外椅,舒适随行\n请根据以上的内容和要求扩写一篇带货口播文案,注意:1.开头引起观众的兴趣2.扩写要保留以上内容全部信息,结合观众需求突出商品特点3.在结尾引导观众行动。要求口语化。需要300字。", "target": "嗨!亲爱的朋友们,你们是不是也常常遇到户外活动时找不到合适的座椅,坐地上又硬又不舒服?那么,我今天要介绍的产品就能解决你的困扰!它就是轻便折叠户外椅,让你的户外时光更加舒适随行!\n\n这款户外椅不仅轻巧便携,折叠起来只有一只手的大小,非常方便携带!无论是野餐、露营还是旅行,它都能轻松满足你的需要,为你的舒适提供保障!\n\n它采用高质量的材料制造而成,坚固耐用,可以承受220磅的重量,稳如泰山,安全可靠。而且,它的面料柔软舒适,采用透气网布设计,不仅排汗透气,而且可根据你的身体曲线自主调节,提供全方位的支撑和舒适度。\n\n亲爱的朋友们,快来选购这款轻便折叠户外椅,让你的户外生活更加舒适、随心随行!赶快单击下方链接,实现你的户外梦想!"} {"context":"产品:毛绒玩具\n特点:柔软可爱,陪伴成长,给孩子无限温暖的拥抱。\n请根据以上的内容和要求扩写一篇带货口播文案,注意:1.开头引起观众的兴趣2.扩写要保留以上内容全部信息,结合观众需求突出商品特点3.在结尾引导观众行动。要求口语化。需要300字。", "target": "小伙伴们,我来给你们介绍一款超可爱的毛绒玩具!它柔软可爱,真的是陪伴成长、给孩子无限温暖的拥抱!\n\n它是宝宝的小伙伴,不离不弃地陪伴着他们的成长。而且这款毛绒玩每一个细节都呈现出了无限的童真和天真,真的是太可爱了!\n\n除了可爱外,这款毛绒玩具还有一个很重要的功能,它能给孩子带来无限温暖的拥抱。当孩子感到孤独或者失落时,它就像一个亲密的好友一样,安慰着他们的心灵。就像你给亲人一个紧紧的拥抱,让他们感受到你的爱一样,这款毛绒玩具也能给孩子带来同样的温暖和关怀。\n\n所以,我相信这款毛绒玩具一定能成为你宝贝的最爱,给他们带来无尽的欢乐和温暖。现在就单击下方链接,购买一只给宝贝一个最温暖的拥抱吧!"} - 数据量级要求:本场景使用了5000条数据进行微调。
说明:类似场景需要的微调数据量视具体情况而定。从经验上来说,如果实际场景相对单一,比如只需要构建短视频口播文案生成的场景,则使用5000条数据即可;如果场景中涵盖多个细分场景,比如短视频口播生成、小红书风格文案生成等等,则每个子场景各需要准备至少5000条数据。
- 数据质量要求:
- 保证微调数据中的输入(context字段)不重复,否则会造成模型效果不佳。
- 保证微调数据内容干净,不包含异常字符。
- 保证输出(target字段)内容符合业务场景需求。例如,短视频口播场景要求文风可以引起观众兴趣、不丢失产品特点且可以引导观众购买。
微调数据清洗:
下表中列举了本场景常见的数据质量问题以及相应的清洗策略,供您参考:
|
数据问题 |
清洗步骤与手段 |
清洗前 |
清洗后 |
|---|---|---|---|
|
问题一:数据中存在超链接、异常符号等。 |
删除数据中的异常字符。 |
{"context":"轻便折叠户外椅,舒适随行\n请根据以上的内容和要求扩写一篇带货口播文案,注意:1.开头引起观众的兴趣2.扩写要保留以上内容全部信息,结合观众需求突出商品特点3.在结尾引导观众行动。要求口语化。需要300字。", "target": " ????嗨!亲爱的朋友们,你们是不是也常常遇到户外活动时找不到合适的座椅,坐地上又硬又不舒服?那么,我今天要介绍的产品就能解决你的困扰!它就是轻便折叠户外椅,让你的户外时光更加舒适随行!\n\n这款户外椅不仅轻巧便携,折叠起来只有一只手的大小,非常方便携带!无论是野餐、露营还是旅行,它都能轻松满足你的需要,为你的舒适提供保障!\n\n它采用高质量的材料制造而成,坚固耐用,可以承受220磅的重量,稳如泰山,安全可靠。而且,它的面料柔软舒适,采用透气网布设计,不仅排汗透气,而且可根据你的身体曲线自主调节,提供全方位的支撑和舒适度。\n\n亲爱的朋友们,快来选购这款轻便折叠户外椅,让你的户外生活更加舒适、随心随行!赶快单击下方链接,实现你的户外梦想!"} |
{"context":"轻便折叠户外椅,舒适随行\n请根据以上的内容和要求扩写一篇带货口播文案,注意:1.开头引起观众的兴趣2.扩写要保留以上内容全部信息,结合观众需求突出商品特点3.在结尾引导观众行动。要求口语化。需要300字。", "target": "嗨!亲爱的朋友们,你们是不是也常常遇到户外活动时找不到合适的座椅,坐地上又硬又不舒服?那么,我今天要介绍的产品就能解决你的困扰!它就是轻便折叠户外椅,让你的户外时光更加舒适随行!\n\n这款户外椅不仅轻巧便携,折叠起来只有一只手的大小,非常方便携带!无论是野餐、露营还是旅行,它都能轻松满足你的需要,为你的舒适提供保障!\n\n它采用高质量的材料制造而成,坚固耐用,可以承受220磅的重量,稳如泰山,安全可靠。而且,它的面料柔软舒适,采用透气网布设计,不仅排汗透气,而且可根据你的身体曲线自主调节,提供全方位的支撑和舒适度。\n\n亲爱的朋友们,快来选购这款轻便折叠户外椅,让你的户外生活更加舒适、随心随行!赶快单击下方链接,实现你的户外梦想!"} |
|
问题二: 存在未转义的字符。 |
进行转义。 |
{"context":"舒适随行的"骆驼牌"轻便折叠户外椅,\n请根据以上的内容和要求扩写一篇带货口播文案,注意:1.开头引起观众的兴趣2.扩写要保留以上内容全部信息,结合观众需求突出商品特点3.在结尾引导观众行动。要求口语化。需要300字。", "target": …} |
{"context":"舒适随行的\"骆驼牌\"轻便折叠户外椅\n请根据以上的内容和要求扩写一篇带货口播文案,注意:1.开头引起观众的兴趣2.扩写要保留以上内容全部信息,结合观众需求突出商品特点3.在结尾引导观众行动。要求口语化。需要300字。", "target": …} |
|
问题三:存在重复数据。 |
删除重复数据。 |
略 |
略 |
训练模型
自监督训练:
不涉及
有监督微调:
本场景采用了下表中的微调参数进行微调,您可以在平台中参考如下参数进行训练:
|
训练参数 |
设置值 |
|---|---|
|
数据批量大小(batch_size) |
8 |
|
训练轮数(epoch) |
4 |
|
学习率(learning_rate) |
7.5e-05 |
|
学习率衰减比率(learning_rate_decay_ratio) |
0.067 |
|
热身比例(warmup) |
0.01 |
评估和优化模型
模型评估:
您可以从平台的训练日志中获取到每一步的Loss,并绘制成Loss曲线。本场景的一个Loss曲线示例如下:
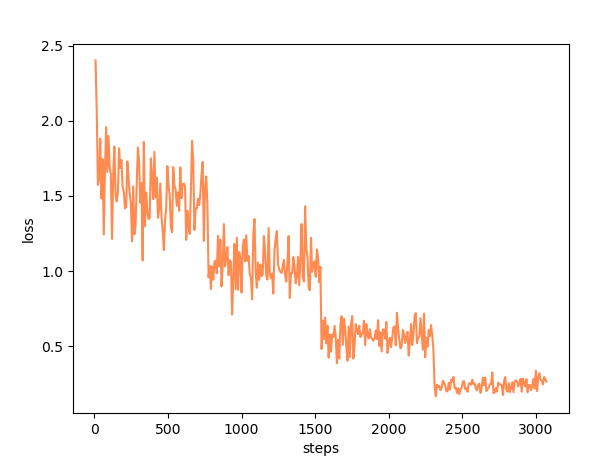
通过观察,该Loss曲线随着迭代步数的增加呈下降趋势直至稳定,证明整个训练状态是正常的。若Loss曲线呈现轻微阶梯式下降,为正常现象。
模型持续优化:
本场景采用了下表中的推理参数进行解码,您可以在平台部署后参考如下参数调试:
|
推理参数 |
设置值 |
|---|---|
|
最大Token限制(max_token) |
4096 |
|
温度(temperature) |
0.3 |
|
核采样(top_p) |
1.0 |
|
话题重复度控制(presence_penalty) |
0 |
部署推理服务后,可以采用人工评测的方案来评估模型效果。若评测过程中出现如下问题,可以参考解决方案进行优化:
- 问题一:模型答案没有按照Prompt要求回答。例如,要求文案在300字以内,但是模型回答字数仍然超出300字。
解决方案:在数据质量要求中提到要求训练数据的输出(target字段)需要符合业务场景需求。因此,针对该问题,需要严格控制数据质量。若输入(context字段)要求文案300字以内,则输出必须要满足300字以内。
- 问题二:模型生成的文案中重复讨论一个相同的话题。
解决方案:对于这种情况,可以尝试修改推理参数。例如,降低“话题重复度控制”参数的值。若调整推理参数不生效,则检查数据质量,确认数据中不存在重复数据和高度相似数据。





