Graph关键字
参数 |
说明 |
必选(M)/可选(O) |
|
|---|---|---|---|
graph_id |
- |
Graph ID,为正整数。 |
O |
priority |
- |
优先级,无需调整。 |
O |
device_id |
- |
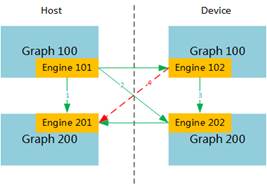
设备ID。不同Graph可以运行在一个或多个芯片上,也可以运行在不同PCIe卡的芯片上,如果运行在不同芯片上,需要在graph的配置中增加device_id项,用于指定Graph运行的device id。如果不指定,默认运行在device id为0的芯片上。device id的id值从0开始,到N-1结束(N表示Device个数)。 |
O |
engines
说明:
多路解码时推荐配置多个Engine,一个Engine对应一个线程,如果一个Engine对应多个线程,解码时无法保证顺序。 |
id |
Engine ID。 |
M |
engine_name |
Engine名称。 |
M |
|
side |
Engine运行target,取值为“HOST”或“DEVICE”,需要注意根据业务需求,配置Engine运行在HOST或DEVICE。 |
M |
|
so_name |
Engine运行时需要从Host侧拷贝动态库so文件名到Device侧。如果FrameworkerEngine运行时,需要依赖第三方库文件或自定义库文件时,依赖的so文件也需要配置在graph文件中(请将以下示例中的“xxx”替换为实际依赖库名。) so_name: "./libFrameworkerEngine.so" so_name: "./libxxx.so" so_name: "./libxxx.so" |
O |
|
thread_num |
线程数量。多路解码时,该参数值推荐设置为“1”,如果“thread_num”的值大于“1”,线程之间的解码将无法保证顺序。 |
M |
|
thread_priority |
线程优先级。取值范围从“1”到“99”,用于设置engine对应的数据处理线程的优先级,采用SCHED_RR调度策略,再根据策略将对应Engine设置为较高优先级。 |
O |
|
queue_size |
队列大小,默认为“200”。 用户需要根据业务负载的波动、Engine接收数据大小、系统内存进行合理配置。 |
O |
|
ai_config |
配置示例:
ai_config{
items{
name: "model_path"
value: "./test_data/model/resnet18.om"
}
}
|
O |
|
ai_model |
配置示例:
ai_model{
name: "" //模型名称
type:"" //模型类型
version:"" //模型版本
size:"" //模型大小
path:"" //模型路径
sub_path:"" //辅助模型路径
key:"" //模型密钥
sub_key:"" //辅助模型密钥
frequency:"UNSET" //设备频率,取值UNSET或0表示取消设置;LOW或1表示低频;MEDIUM或2表示中频;HIGH或3表示高频。
device_frameworktype:"NPU" //模型运行设备类型,取值为NPU/IPU/MLU/CPU。
framework:"OFFLINE" //执行框架,取值为OFFLINE/CAFFE/TENSORFLOW。
}
|
O |
|
oam_config |
配置dump算法数据的方式。当推理不准确时,可以查看某些层或全部层的算法结果。
配置示例:
oam_config{
items{
model_name: "" //相对路径+模型名称+后缀
is_dump_all:"" //是否全部dump,取值为"true"或"false"。
layer: "" //层
}
dump_path:"" //dump路径
}
|
O |
|
internal_so_name |
内置在Device侧的动态库文件,用户可直接使用,无需从Host侧拷贝到Device侧。 |
O |
|
wait_inputdata_max_time |
当前收到数据后等待下一个数据的最大超时时间。
|
O |
|
is_repeat_timeout_flag |
针对Engine未收到数据,是否进行循环超时处理(唤醒),与wait_inputdata_max_time配合使用,取值说明如下:
|
O |
|
holdModelFileFlag |
是否保留本Engine的模型文件,取值说明如下:
|
O |
|
connects |
src_engine_id |
源Engine ID。 |
M |
src_port_id |
源Engine的发送端口号。 对于某个Engine,其端口号从“0”开始顺次增加。端口个数定义一般在相应的头文件中以HIAI_DEFINE_PROCESS宏来定义,代码实现如下: #define SOURCE_ENGINE_INPUT_SIZE 1
#define SOURCE_ENGINE_OUTPUT_SIZE 1
class SrcEngine : public Engine {
HIAI_DEFINE_PROCESS(SOURCE_ENGINE_INPUT_SIZE, SOURCE_ENGINE_OUTPUT_SIZE)
} |
M |
|
target_engine_id |
目的Engine ID。 |
M |
|
target_port_id |
目的Engine的接收端口号。 |
M |
|
target_graph_id |
目的Graph ID。 Engine支持跨Graph串接,在该场景下,需要在connects的配置中增加“target_graph_id”项来表示接收端的Graph ID,如不配置,则默认在同一个graph中串接。 在有多个Ascend 310芯片情况下,可以使用跨Graph串接将各个模型运行在不同的Ascend 310芯片上,故尽量将相同的模型放在一个芯片上进行推理,减少不必要的内存消耗。 【场景说明】 |
O |
|
receive_memory_without_dvpp |
|
O |
|