
训练作业容错检查
场景描述
用户在训练模型过程中,存在因硬件故障而产生的训练失败场景。针对硬件故障场景,ModelArts提供容错检查功能,帮助用户隔离故障节点,优化用户训练体验。
容错检查包括两个检查项:环境预检测与硬件周期性检查。当环境预检查或者硬件周期性检查任一检查项出现故障时,隔离故障硬件并重新下发训练作业。针对于分布式场景,容错检查会检查本次训练作业的全部计算节点。
下图中有四个场景,其中场景四为正常训练作业失败场景,其他三个场景下可开启容错功能进行训练作业自动恢复。
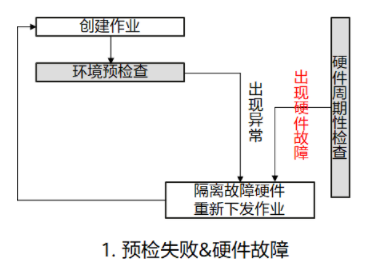
- 场景一:环境预检测失败、硬件检测出现故障,系统隔离所有故障节点并重新下发训练作业。
图1 预检失败&硬件故障
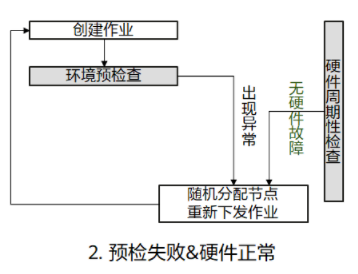
- 场景二:环境预检测失败、硬件无故障,系统随机再分配节点并重新下发训练作业。
图2 预检失败&硬件正常
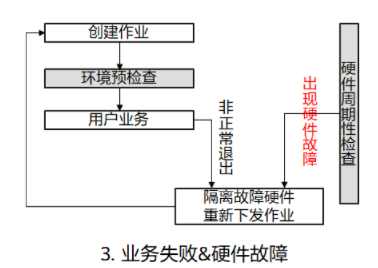
- 场景三:环境预检测成功并进入用户业务阶段,硬件检测出现故障并且用户业务非正常退出,系统隔离所有故障节点并重新下发训练作业。
图3 业务失败&硬件故障
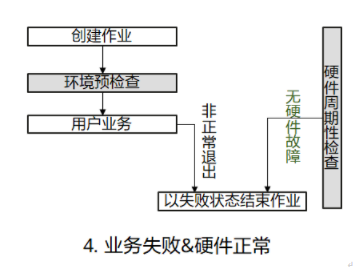
- 场景四:环境预检测成功并进入用户业务阶段,硬件无故障,当用户业务异常时系统以失败状态结束作业。
图4 业务失败&硬件正常
隔离故障节点后,系统会在新的计算节点上重新创建训练作业。如果资源池规格紧张,重新下发的训练作业会以第一优先级进行排队。如果排队时间超过30分钟,训练作业会自动退出。该现象表明资源池规格任务紧张,训练作业无法正常启动,推荐您购买专属资源池补充计算节点。
如果您使用专属资源池创建训练作业,容错检查识别的故障节点会被剔除。系统自动补充健康的计算节点至专属资源池。(该功能即将上线)
容错检查详细介绍请参考:
- 开启容错检查
- 检测项目与执行条件
- 触发容错环境检测达到的效果
- 环境预检查通过后,如果发生硬件故障会导致用户业务中断。您可以在训练中补充reload ckpt的代码逻辑,使能读取训练中断前保存的预训练模型。指导请参考设置断点续训练。
开启容错检查
用户可以在创建训练作业时通过设置自动重启的方式开启容错检查。
- 使用ModelArts Standard控制台的创建训练作业页面设置自动重启:
用户可以在控制台页面通过开关的方式开启自动重启。“自动重启”开关默认不开启,表示不做重新下发作业,也不会启用环境检测。打开开关后,允许设置重启次数为1~128次。
图5 自动重启设置
- 使用API接口设置容错检查:
用户可以通过API接口的方式开启自动重启。创建训练作业时,在“metadata”字段的“annotations”中传入“fault-tolerance/job-retry-num”字段。
添加“fault-tolerance/job-retry-num”字段,视为开启自动重启,value的范围可以设置为1~128的整数。value值表示最大允许重新下发作业的次数。如果不传入则默认为0,表示不做重新下发作业,也不会启用环境检测。
图6 设置API
检测项目与执行条件
|
检测项目 |
item(日志关键字) |
执行条件 |
检测成功要求 |
|---|---|---|---|
|
域名检测 |
dns |
无 |
volcano容器的域名都解析成功(/etc/volcano下的“.host”文件中的域名解析成功) |
|
磁盘空间-容器根目录 |
disk-size root |
无 |
大于32GB |
|
磁盘空间-/dev/shm目录 |
disk-size shm |
无 |
大于1GB |
|
磁盘空间-/cache目录 |
disk-size cache |
无 |
大于32GB |
|
ulimit检查 |
ulimit |
使用IB网络时 |
|
|
gpu检查 |
gpu-check |
使用gpu,且使用v2训练引擎时 |
检测到gpu |
触发容错环境检测达到的效果
- 容错检查正常通过时,会打印检测项目的日志,表示具体涉及的检查项目成功。您可以通过在日志中搜索“item”关键字查看。当容错检查正常通过时,可以减少运行故障上报问题。
- 容错检查失败时,会打印检查失败的日志。您可以通过在日志中搜索“item”关键字查看失败信息。
如果作业重启次数没有达到设定的次数,则会自动做重新下发作业。您可以通过搜索“error,exiting”关键字查找作业重启失败结束的日志。
使用reload ckpt恢复中断的训练
在容错机制下,如果因为硬件问题导致训练作业重启,用户可以在代码中读取预训练模型,恢复至重启前的训练状态。用户需要在代码里加上reload ckpt的代码,使能读取训练中断前保存的预训练模型。具体请参见断点续训练。
查看容错与恢复详情
当训练作业发生故障恢复时(例如NPU原地恢复、JOB级重调度等),作业详情页面中会出现“故障恢复详情”页签,里面记录了训练作业的启停情况。
用户创建训练作业时开启自动重启后,可以在训练作业详情页面查看“重启次数”。“重启次数”会展示当前重启次数/最大重启次数。在训练作业详情页的“容错与恢复”页签,可以查看训练作业重启详情。






