
通过DataArts Studio提交MRS Flink作业
Flink作业是基于Flink框架开发的分布式数据处理任务,主要用于流式数据处理和有状态计算。Flink是一个面向流处理和批处理的统一计算框架,其作业以流为核心(批处理可视为有限流),支持高吞吐、低延迟、精准语义的实时数据处理,广泛应用于实时监控、日志分析、金融交易等场景。
DataArts Studio作为一站式数据处理平台,为用户提供了便捷、高效的Flink作业提交能力,帮助企业快速构建实时数据应用,实现数据价值的实时变现。
通过DataArts Studio提交MRS Flink作业流程如图1所示。

|
阶段 |
说明 |
|---|---|
|
准备MRS集群 |
DataArts Studio支持对接MRS Hive、HDFS、Flink、ClickHouse等大数据组件,可基于业务需求按需选择并创建包含有对应组件的MRS集群。 |
|
初始配置DataArts Studio |
DataArts Studio实例的虚拟私有云、子网、安全组信息,需与MRS集群保持一致。 |
|
开发作业或应用程序 |
数据开发是一个一站式的大数据协同开发平台,提供全托管的大数据调度能力。 用户基于业务需求开发相关的SQL脚本作业或者Jar作业。 |
|
运行作业并查看结果 |
用户可以直接通过运行结果查看作业运行情况。 |
在本章节中以开发一个MRS FlinkSQL作业为例进行介绍。
步骤1:准备MRS集群
- 进入购买MRS集群页面。
- 选择“快速购买”,填写软件配置参数。
以购买一个开启Kerberos认证的包含Flink、Kafka组件的MRS集群为例,关键参数配置如表2所示。
更多MRS集群购买参数说明请参考快速购买MRS集群。
表2 创建MRS集群 参数名称
描述
取值样例
计费模式
选择待创建的MRS集群的计费模式。
按需计费
集群名称
待创建的MRS集群名称。
MRS_demo
集群类型
待创建的MRS集群类型。
选择“自定义”
版本类型
待创建的MRS集群版本类型。
LTS版
集群版本
待创建的MRS集群版本。
MRS 3.2.0-LTS.1
组件选择
选择待创建的MRS集群配套的组件。
Hadoop分析集群
可用区
选择集群工作区域下关联的可用区。
可用区1
虚拟私有云
选择需要创建集群的VPC,单击“查看虚拟私有云”进入VPC服务查看已创建的VPC名称和ID。如果没有VPC,需要创建一个新的VPC。
vpc-01
子网
选择需要创建集群的子网,可进入VPC服务查看VPC下已创建的子网名称和ID。如果VPC下未创建子网,请单击“创建子网”进行创建。
subnet-01
Kerberos认证
访问MRS集群时是否启用Kerberos认证。
开启
密码
配置Manager管理员admin用户及集群ECS节点root用户的密码。
Test!@12345。
企业项目
选择集群所属的企业项目。
default
- 单击“立即购买”,等待MRS集群创建成功。
- 集群状态变为“运行中”后,单击集群名称,进入集群详情页。
- 在“概览”页签中,单击“IAM用户同步”右侧的“同步”进行IAM用户同步。
集群开启Kerberos认证时需执行该步骤,若集群未开启Kerberos认证,无需执行本步骤。
IAM用户同步完成后,请等待5分钟,再进行提交作业,更多IAM用户同步说明请参考IAM用户同步MRS集群说明。
- 集群状态变为“运行中”后,单击集群名称,进入集群详情页后选择“前往Manager”,然后继续选择一个弹性公网IP后,进入集群Manager登录界面。
更多MRS集群Manager界面登录方式介绍请参考访问MRS集群Manager。
- 使用admin用户登录集群Manager界面,密码为步骤 2中设置的密码。
- 单击“集群 > 服务 > Kafka”,查看Kafka Broker实例IP地址及连接端口号。
- 在“实例”页签,可查看Kafka Broker实例所在节点的IP地址。
- 在“配置”页签,搜索“sasl.port”参数查看端口号。
- 也可直接在“配置”页签中搜索“bootstrap.servers”,查看Broker连接地址,例如“192.168.42.95:21007,192.168.67.136:21007,192.168.67.142:21007”。
- 选择“系统 > 权限 > 域和互信”,查看并记录“本端域”参数,即为当前MRS集群的系统域名。
步骤2:初始配置DataArts Studio
- 登录DataArts Studio管理控制台,购买一个DataArts Studio实例。
DataArts Studio实例的虚拟私有云、子网、安全组信息,需与MRS集群保持一致。
具体操作请参考购买DataArts Studio实例。
- 进入DataArts Studio实例概览信息页面,选择“空间管理 > 创建工作空间”,创建一个工作空间。
DataArts Studio实例中系统会默认创建一个默认的工作空间“default”,并赋予用户为管理员角色。您可以使用默认的工作空间,也可以在“空间管理”页签中创建一个新的工作空间。
具体操作请参考创建简单模式工作空间。
步骤3:开发Flink SQL作业
- 在DataArts Studio实例概览信息页面,选择当前工作空间下的“数据开发”。
- 在“作业开发”页面中的“作业”目录上右键,选择“新建作业”。
表3 DataArts Studio作业配置参数 参数名称
描述
取值样例
作业名称
自定义作业的名称,只能包含英文字母、数字、中文、“-”、“_”、“.”,且长度为1~128个字符。
job_test
作业类型
- 批处理作业:按调度计划定期处理批量数据,主要用于实时性要求低的场景。批作业是由一个或多个节点组成的流水线,以流水线作为一个整体被调度。被调度触发后,任务执行一段时间必须结束,即任务不能无限时间持续运行。
- 实时处理作业:处理实时的连续数据,主要用于实时性要求高的场景。实时作业是由一个或多个节点组成的业务关系,每个节点可单独被配置调度策略,而且节点启动的任务可以永不下线。在实时作业里,带箭头的连线仅代表业务上的关系,而非任务执行流程,更不是数据流。
实时处理
模式
- Pipeline:即传统的流水线式作业,作业通过画布编辑,可以拖入一个或多个节点组成作业,各节点依次被流水线式地执行。
- 单任务:单任务作业可以认为是有且只有一个节点的批处理作业,整个作业即为一个脚本节点。
单任务 > Flink SQL
选择目录
选择作业所属的目录,默认为根目录。
/作业/
责任人
填写该作业的责任人。
-
作业优先级
选择作业的优先级,提供高、中、低三个等级。
作业优先级是作业的一个标签属性,不影响作业的实际调度执行的先后顺序。
高
委托配置
作业执行过程中,以IAM委托的身份与其他服务交互。
若工作空间已配置过委托,则新建的作业默认使用该工作空间级委托。
-
日志路径
选择作业日志的OBS存储路径。
obs://test/dataarts-log/
作业描述
作业的描述信息。
-
图2 新建FlinkSQL作业
- 在编辑器中输入SQL语句,通过SQL语句来实现业务需求。
以下Flink SQL样例创建了一个实时数据管道,将数据从一个Kafka主题“test_source”传输到另一个Kafka主题“test_sink”。
根据实际环境信息,修改Kafka Broker连接信息和MRS集群域名信息。
--源表定义 CREATE TABLE KafkaSource ( `user_id` VARCHAR, `user_name` VARCHAR, `age` INT ) WITH ( 'connector' = 'kafka',--指定使用Kafka连接器 'topic' = 'test_source',--要消费的Kafka主题名称 'properties.bootstrap.servers' = 'Kafka Broker实例IP地址及连接端口号',--Kafka集群地址 'properties.group.id' = 'testGroup',-- Kafka消费者组ID,用于记录消费偏移量 'scan.startup.mode' = 'latest-offset',-- 启动时从最新偏移量开始消费 'format' = 'csv',-- 数据格式 'properties.sasl.kerberos.service.name' = 'kafka',--Kerberos服务名,未开启Kerberos认证的集群不需要该参数 'properties.security.protocol' = 'SASL_PLAINTEXT',--网络安全协议类型,未开启Kerberos认证的集群不需要该参数 'properties.kerberos.domain.name' = 'hadoop.MRS集群域名'--Kerberos域名信息,未开启Kerberos认证的集群不需要该参数 ); --目标表定义 CREATE TABLE KafkaSink( `user_id` VARCHAR, `user_name` VARCHAR, `age` INT ) WITH ( 'connector' = 'kafka', 'topic' = 'test_sink', 'properties.bootstrap.servers' = 'Kafka Broker实例IP地址及连接端口号', 'scan.startup.mode' = 'latest-offset', 'value.format' = 'csv', 'properties.sasl.kerberos.service.name' = 'kafka',--Kerberos服务名,未开启Kerberos认证的集群不需要该参数 'properties.security.protocol' = 'SASL_PLAINTEXT',--网络安全协议类型,未开启Kerberos认证的集群不需要该参数 'properties.kerberos.domain.name' = 'hadoop.MRS集群域名'--Kerberos域名信息,未开启Kerberos认证的集群不需要该参数 ); --数据传输操作,将数据从源表传输到目标表 Insert into KafkaSink select * from KafkaSource;
- 脚本开发完成后,单击开发区右上角的“基本信息”,配置作业相关运行参数信息。
表4 Flink SQL作业运行配置参数 参数名称
描述
取值样例
Flink作业名称
自定义Flink作业的名称,
只能包含英文字母、数字、中文、“-”、“_”、“.”,且长度为1~64个字符。
job_test
集群或数据连接
选择用于运行Flink作业的MRS集群名称。
单任务Flink SQL目前支持MRS 3.2.0-LTS.1及以上版本。
集群 > MRS_demo
运行程序参数
为本次执行的作业配置相关优化参数(例如线程、内存、CPU核数等),用于优化资源使用效率,提升作业的执行性能。
Flink作业运行程序参数可根据执行程序及集群资源情况进行配置,若不配置将使用集群默认值。
常见的Flink作业运行参数如下:
- -ytm:指定每个TaskManager的内存大小(单位为MB,可简写为g表示GB,如-ytm 2g)。
TaskManager是执行具体计算任务的进程,内存需根据作业复杂度(如状态大小、并行度)调整,内存不足会导致 OOM错误。
- -yjm:指定JobManager的内存大小(单位为MB,可简写为g表示GB)。
JobManager负责协调任务调度、检查点管理等,内存需求通常小于TaskManager,但需保证足够运行(建议至少 1GB)。
- -yn:指定YARN集群中启动的TaskManager数量。
- -ys:指定每个TaskManager的Slot数量。
- -ynm:指定作业在YARN集群中的应用名称(自定义标识)。
- -c:指定Flink作业的入口类(即包含main方法的类的全限定名)。
- -s:从指定的保存点(Savepoint)恢复作业。
保存点是手动触发的全局状态快照,用于作业升级、重启时恢复状态,需提前通过flink savepoint命令生成。
查询checkpoint列表时,配置-s参数,鼠标单击参数值输入框,checkpoint列表参数值会自动弹出。
- -yD:动态设置Flink配置参数(覆盖“flink-conf.yaml”中的默认配置)。
Flink配置项(如检查点间隔、状态后端等)调整,适合临时调整作业参数,无需修改全局配置文件。
例如:
要使Flink Checkpoint生效,需要配置两个运行参数:
- 用来控制Checkpoint触发频率间隔时间
- 用来控制保留的checkpoint数量
更多关于Flink作业参数说明,可参考https://nightlies.apache.org/flink/flink-docs-release-1.17/。
-
Flink作业执行参数
程序执行的关键参数,该参数由用户程序内的函数指定,多个参数间使用空格隔开。
-
重跑策略
配置Flink作业重新运行策略。
- 从上一个检查点重跑:当作业失败自动重启或手动重启时,Flink会自动从最近的检查点恢复状态。
- 重新启动:作业失败后重新启动作业。
重新启动
输入数据路径
设置输入数据路径,系统支持从HDFS或OBS的目录路径进行配置。
-
输出数据路径
设置输出数据路径,系统支持从HDFS或OBS的目录路径进行配置。
-
作业状态轮询时间(秒)
作业运行过程中,根据设置的作业状态轮询时间查询作业运行状态。
30
最长等待时间
设置作业执行的超时时间,如果作业配置了重试,在超时时间内未执行完成,该作业将会再次重试。
6 小时
失败重试
如果作业节点配置了重试,并且配置了超时时间,该节点执行超时后,系统支持再重试。
当“失败重试”配置为“是”才显示“超时重试”。
否
- -ytm:指定每个TaskManager的内存大小(单位为MB,可简写为g表示GB,如-ytm 2g)。
步骤4:运行作业
- 单击画布上方的“提交”,将当前作业提交为一个新版本。
- 单击画布上方的“启动”,等待Flink作业启动成功。
单击“运维调度 > 作业监控”界面,可查看当前作业运行状态。
图3 运行Flink SQL作业
如果作业启动异常或失败,可单击“查看日志”查看作业运行详细信息。
- 如果当前集群已开启Kerberos认证,登录集群Manager界面,在Manager界面中创建一个具有Kafka操作权限的业务用户,请参考创建MRS集群用户。
本示例中,创建一个人机用户testuser,关联用户组“supergroup”及角色“System_administrator”。
- 安装MRS集群客户端。
具体操作可参考安装MRS集群客户端。
MRS集群中默认安装了一个客户端用于作业提交,也可直接使用该客户端。MRS 3.x及之后版本客户端默认安装路径为Master节点上的“/opt/Bigdata/client”,MRS 3.x之前版本为Master节点上的“/opt/client”。
- 执行以下命令进入客户端安装目录。
cd /opt/Bigdata/client
加载环境变量:
source bigdata_env
如果当前集群已开启Kerberos认证,执行以下命令进行用户认证,如果当前集群未开启Kerberos认证,则无需执行kinit操作。
kinit testuser
- 执行以下命令,查看Kafka Topic是否生成。
cd /opt/client/Kafka/kafka/bin
./kafka-topics.sh --list --bootstrap-server Kafka Broker实例IP地址及连接端口号 --command-config /opt/client/Kafka/kafka/config/client.properties可查看到“test_source”主题已创建成功:
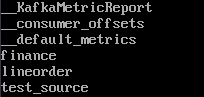
- 向“test_source”主题中写入数据。
sh kafka-console-producer.sh --broker-list Kafka Broker实例IP地址及连接端口号 --topic test_source --producer.config /opt/client/Kafka/kafka/config/producer.properties - 重新打开一个客户端连接窗口,执行以下命令查看Sink表中是否接收到数据。
sh kafka-console-consumer.sh --topic test_sink --bootstrap-server Kafka Broker实例IP地址及连接端口号 --consumer.config /opt/client/Kafka/kafka/config/consumer.properties - 在步骤 7中打开的输入窗口中,发送消息内容。
1,clw,33
在步骤 8的消费窗口中可查看到消息被成功写入。

相关文档
- 关于DataArts Studio平台更多数据开发实践案例,请参考DataArts Studio数据开发进阶实践。
- 更多关于DataArts Studio作业开发操作说明及注意事项,请参考作业开发流程。
- 更多MRS应用开发样例程序,请参见MRS应用开发指南。




