
更新时间:2025-08-09 GMT+08:00
MRS作业介绍
MRS集群创建成功后,用户可以基于业务需求开发上层应用或脚本,对业务数据进行处理。用户基于大数据组件能力并结合实际业务情况开发作业程序或者脚本,然后与业务数据一同上传云平台后并提交运行,以实现指定的业务目标。
- MRS集群提供了在线的作业管理功能,用户可直接在MRS管理控制台界面中快速创建并运行作业,系统支持包括MapReduce、Spark、HiveSQL和SparkSQL等类型的作业。同时用户也可以通过集群客户端的方式将作业提交至大数据组件服务端运行。
- 华为云数据治理中心DataArts Studio服务提供一站式的大数据协同开发环境、全托管的大数据调度能力,通过DataArts Studio服务,用户可以在线开发调试MRS HiveSQL/SparkSQL脚本、拖拽式地开发MRS应用作业,完成MRS与其他异构数据源之间的数据迁移和数据集成。
图1 DataArts Studio产品架构

DataArts Studio与MRS搭配使用可构建从数据接入、处理到分析的全链路大数据解决方案。
- 在企业数据湖建设场景中,DataArts Studio可通过数据集成模块从多源异构系统采集数据,借助数据开发模块编写Hive、Spark、Flink 脚本,并提交至MRS集群执行分布式计算,利用MRS的HDFS/HBase存储海量原始数据,同时通过DataArts Studio的数据治理功能对数据进行元数据管理、质量监控与血缘追溯。
- 在实时数据处理场景下,DataArts Studio可编排流式作业,对接 MRS的Kafka组件获取实时数据流,通过MRS的Spark Streaming/Flink 集群进行实时清洗与聚合,结果存入MRS的Hive数据仓库后,再由DataArts Studio的报表模块生成动态可视化分析。
- 在离线批处理场景中,DataArts Studio可调度MRS的Hadoop MapReduce作业完成大规模数据的ETL处理,如金融行业的交易数据对账、制造业的设备日志分析等,同时利用DataArts Studio的智能数据建模功能为MRS存储的数据构建业务模型,实现数据价值挖掘与合规治理的一体化运作。
图2 MRS作业提交流程
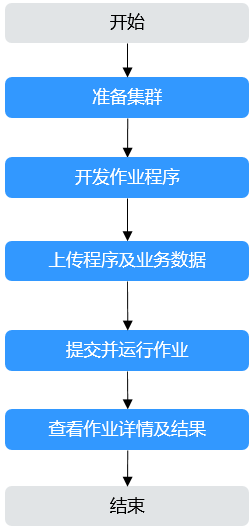
MRS作业处理的数据通常来源于OBS或HDFS,用户创建作业前需要将待分析数据上传至OBS文件系统或者MRS集群内的HDFS中,MRS管理控制台也支持将OBS中的数据快速导入至HDFS中。HDFS和OBS同时支持存储压缩格式的数据,目前支持存储bz2、gz压缩格式的数据。
MRS集群中的常见作业类型如下:
- MapReduce:提供快速并行处理大量数据的能力,是一种分布式数据处理模式和执行环境,MRS支持提交MapReduce Jar程序。
- Spark:基于内存进行计算的分布式计算框架,MRS支持提交SparkSubmit、Spark Script和Spark SQL作业。
- SparkSubmit:提交Spark Jar和Spark Python程序,运行Spark Application计算和处理用户数据。
- SparkScript:提交SparkScript脚本,批量执行Spark SQL语句。
- Spark SQL:使用Spark提供的类似SQL的Spark SQL语句,实时查询和分析用户数据。
- Hive:建立在Hadoop基础上的开源的数据仓库。MRS支持提交HiveScript脚本和直接执行Hive SQL语句。
- Flink:提供一个分布式大数据处理引擎,可对有限数据流和无限数据流进行有状态计算。
- HadoopStreaming:HadoopStreaming作业像普通Hadoop作业一样,除了可以指定输入和输出的HDFS路径的参数外,它还可以指定mapper和reducer的可执行程序。
管理控制台运行作业用户权限说明
用户在MRS管理控制台提交作业时,要先执行IAM用户同步操作,将IAM用户同步至MRS集群的用户系统内。同步的IAM用户是否有提交作业的权限,取决于IAM同步时,用户所绑定的IAM策略,提交作业策略请参考IAM用户同步MRS集群说明章节中表1。
用户提交的作业程序如果涉及到具体组件的资源使用,如HDFS的目录访问、Hive表的访问等相关组件的权限时,需要由集群Manager管理员用户(例如admin)进行用户授权,给提交作业用户赋予相关组件权限。
- 使用admin用户登录集群Manager界面,请参考访问MRS集群Manager。
- 参考管理MRS集群角色内容,增加用户具体需要的组件权限的角色。
- 参考管理MRS集群用户组修改提交作业用户所属的用户组,将新增的组件角色加入到该用户组中。
用户所在用户组绑定的组件角色修改后,权限生效需要一定时间,请耐心等待至少5分钟以上。




