
配置BOT防护规则
您可以通过配置BOT防护规则,防护搜索引擎、扫描器、脚本工具、其它爬虫等爬虫,以及自定义JS脚本反爬虫防护规则。
前提条件
已添加防护网站,详情操作请参见添加防护网站 。
约束条件
BOT管理功能介绍
按照检测执行顺序,BOT管理支持以下功能。
“已知BOT检测”是BOT检测的第一环节,它根据用户请求中携带的UA关键字,与BOT管理中的UA特征库进行比对。如果请求来自某种已知BOT(已知客户端),则按照配置的防护动作处置该请求。
基于互联网开源的UA特征情报,结合网站反爬虫的UA特征库,边缘安全支持10类已知BOT检测。
|
类型 |
说明 |
|---|---|
|
搜索引擎机器人 |
搜索引擎利用网络爬虫聚合并索引在线内容(如网页、图像及其他类型的文件),为用户提供实时信息。 |
|
网络扫描器 |
病毒/漏洞扫描器旨在评估和发现网络资产中是否存在病毒或因配置错误、编程缺陷而产生的漏洞。比较典型的扫描器有Nmap、Sqlmap、WPSec等。 |
|
网页抓取工具 |
在网络上流行的爬虫工具或服务,常用于抓取任何网页并提取内容以满足使用者的需求。如Scrapy、pyspider、Prerender等。 |
|
网站开发和监控服务机器人 |
一些公司利用机器人提供服务,帮助Web开发人员监控他们的站点,以确保它们正常运行。这些机器人可以检查链接和域名的可用性、来自不同地理位置的连接和网页加载时间、DNS解析问题及其他一些功能。 |
|
商业分析和营销机器人 |
SEO优化网站或网页在搜索引擎结果中的排序。许多提供SEO服务的公司,同时也利用机器人为用户评估网站内容,提供受众和竞争分析,支撑在线广告的投放和市场营销。 |
|
新闻和社交媒体机器人 |
新闻和社交媒体平台允许用户在线浏览热点资讯、分享想法和互动交流,许多企业的营销策略包括在这些网站上运营页面,与消费者就产品或服务进行互动。一些公司会利用机器人从这些平台中收集数据,用于媒体趋势和产品的洞察,丰富网络体验。 |
|
屏幕快照机器人 |
一些公司利用机器人对外提供网站截图服务。它可以对网站、社交网络上的帖子、新闻、论坛/博客上的帖子等在线内容进行完整的长屏幕截图。 |
|
学术和研究机器人 |
有些大学和公司会使用机器人从各种网站收集数据,用于学术或研究目的,包括参考文献搜索、语义分析、特定类型的搜索引擎等。 |
|
RSS提要阅读器 |
有些大学和公司会使用机器人从各种网站收集数据,用于学术或研究目的,包括参考文献搜索、语义分析、特定类型的搜索引擎等。 |
|
网络存档器 |
一些组织会使用机器人定期从网络中爬取并存档有价值的在线信息和内容副本,例如维基百科。这些网络存档服务与搜索引擎非常相似,但是提供的数据并不是最新的,它们的目的主要是用于研究。 |
“请求特征检测”是BOT检测的第二环节,它通过识别用户请求中的HTTP请求头域特征,匹配主流的开发框架和HTTP库、仿冒已知BOT、自动化程序来进行检测。如果请求符合某类BOT特征,则按照配置的防护动作处置该请求。
|
类型 |
说明 |
|---|---|
|
HTTP请求头域检测 |
异常的请求头。 |
|
开发框架和HTTP库 |
主流的开发框架和HTTP库,如Apache HttpComponents、OKHttp、Python-requests、Go-http-client等。 |
|
其他 |
|
“BOT行为检测”是BOT检测的第三环节,通过AI智能防护引擎对请求进行分析和自动学习,根据设置的行为检测评分和防护动作处置该攻击行为。
JS脚本反爬虫检测机制
JS脚本检测流程如图1所示,其中,①和②称为“js挑战”,③称为“js验证”。

开启JS脚本反爬虫后,当客户端发送请求时,会返回一段JavaScript代码到客户端。
- 如果客户端是正常浏览器访问,就可以触发这段JavaScript代码再发送一次请求,即边缘安全完成js验证,并将该请求转发给源站。
- 如果客户端是爬虫访问,就无法触发这段JavaScript代码再发送一次请求,即边缘安全无法完成js验证。
- 如果客户端爬虫伪造了认证请求,发送到边缘安全时,会拦截该请求,js验证失败。
通过统计“js挑战”和“js验证”,就可以汇总出JS脚本反爬虫防御的请求次数。例如,图2中JS脚本反爬虫共记录了18次事件,其中,“js挑战”(EdgeSec返回JS代码)为16次,“js验证”(EdgeSec完成JS验证)为2次,“其他”(即爬虫伪造EdgeSec认证请求)为0次。


“js挑战”和“js验证”的防护动作为仅记录,EdgeSec不支持配置“js挑战”和“js验证”的防护动作。
配置BOT管理防护规则
- 登录EdgeSec服务控制台。
- 在左侧导航栏选择,进入“安全防护”的“域名接入”页面。
- 在目标域名所在行的“防护策略”栏中,单击“已开启N项防护”,进入“防护策略”页面。
图3 网站列表

- 在“BOT管理”配置框中,用户可根据自己的需要参照图4更改BOT管理的“状态”,单击“BOT设置”,进入BOT管理配置页面。
- 在“已知BOT检测”、“请求特征检测”或“BOT行为检测”页签,配置相关规则。

- 单击“已知BOT检测”模块,单击防护规则左侧
 图标,选择所需检测项,打开“启用状态”开关。
开启后,默认配置如图5所示。
图标,选择所需检测项,打开“启用状态”开关。
开启后,默认配置如图5所示。 - 根据实际业务需要,启用或关闭对应规则,配置防护动作。
防护动作说明如下:
- “仅记录”:仅记录满足特征的请求。
- “JS挑战”:识别到特征后,边缘安全向客户端返回一段正常浏览器可以自动执行的JavaScript代码。如果客户端正常执行了JavaScript代码,则边缘安全在一段时间(默认30分钟)内放行该客户端的所有请求(不需要重复验证),否则阻断请求。

请求的Referer跟当前的Host不一致时,JS挑战不生效。
- “拦截”:识别到特征后,将直接被拦截。
- “放行”:放行满足特征的请求。

- 单击“请求特征检测”模块,单击防护规则左侧
 图标,选择所需检测项,打开“启用状态”开关。
开启后,默认配置如图6所示。
图标,选择所需检测项,打开“启用状态”开关。
开启后,默认配置如图6所示。 - 根据实际业务需要,启用或关闭对应规则,配置防护动作。
防护动作说明如下:
- “仅记录”:仅记录满足特征的请求。
- “JS挑战”:识别到特征后,边缘安全向客户端返回一段正常浏览器可以自动执行的JavaScript代码。如果客户端正常执行了JavaScript代码,则边缘安全在一段时间(默认30分钟)内放行该客户端的所有请求(不需要重复验证),否则阻断请求。
请求的Referer跟当前的Host不一致时,JS挑战不生效。
- “拦截”:识别到特征后,将直接被拦截。
- “放行”:放行满足特征的请求。

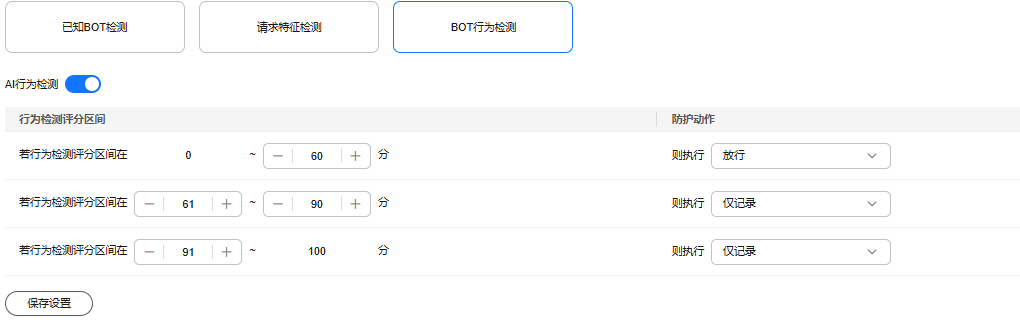
- 单击“BOT行为检测”模块,打开“AI行为检测”开关。
开启后,默认配置如图7所示。
- 根据实际业务需要,设置三个行为检测评分区间。评分区间为0~100,评分越接近0分表示请求特征越像正常请求,越接近100表示请求特征越像BOT。
- 为每个区间配置防护动作。
防护动作说明如下:
- “仅记录”:仅记录满足特征的请求。
- “JS挑战”:识别到特征后,边缘安全向客户端返回一段正常浏览器可以自动执行的JavaScript代码。如果客户端正常执行了JavaScript代码,则边缘安全在一段时间(默认30分钟)内放行该客户端的所有请求(不需要重复验证),否则阻断请求。
请求的Referer跟当前的Host不一致时,JS挑战不生效。
- “拦截”:识别到特征后,将直接被拦截。
- “放行”:放行满足特征的请求。
配置JS脚本反爬虫
- 登录EdgeSec服务控制台。
- 在左侧导航栏选择,进入“安全防护”的“域名接入”页面。
- 在目标域名所在行的“防护策略”栏中,单击“已开启N项防护”,进入“防护策略”页面。
图8 网站列表
- 在“BOT管理”配置框中,用户可根据自己的需要参照图9更改BOT管理的“状态”。
- 选择“JS脚本反爬虫”页签,用户可根据业务需求更改JS脚本反爬虫的“状态”和“防护模式”。
默认关闭JS脚本反爬虫,单击
 ,在弹出的“警告”提示框中,单击“确定”,开启JS脚本反爬虫
,在弹出的“警告”提示框中,单击“确定”,开启JS脚本反爬虫 。
。JS脚本反爬虫规则提供了三种防护动作:
- 拦截:JavaScript挑战失败后,立即阻断并记录。
- 仅记录:JavaScript挑战失败后,只记录不阻断。
- 人机验证:JavaScript挑战失败后,以验证码的形式进行验证。
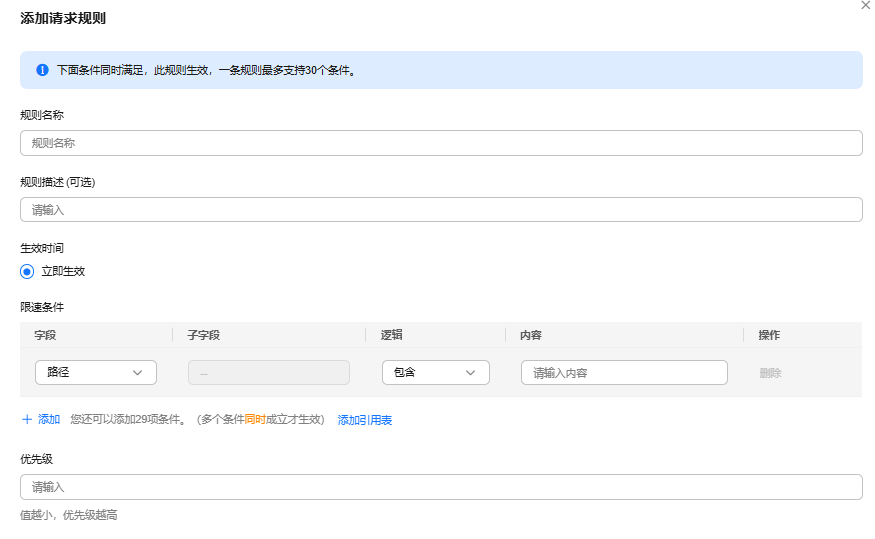
- 根据业务配置JS脚本反爬虫规则,相关参数说明如表1所示。
JS脚本反爬虫规则提供了“防护所有请求”和“防护指定请求”两种防护动作。
表1 JS脚本反爬虫参数说明 参数
参数说明
示例
规则名称
自定义规则名称。
EdgeSec
规则描述
可选参数,设置该规则的备注信息。
-
生效时间
立即生效。
立即生效
条件列表
条件设置参数说明如下:
- 字段:在下拉列表中选择需要防护的字段,当前仅支持“路径”、“User Agent”。
- 子字段
- 逻辑:在“逻辑”下拉列表中选择需要的逻辑关系。
说明:
选择“包含任意一个”、“不包含任意一个”、“等于任意一个”、“不等于任意一个”、“包含任意前缀”、“不包含任意前缀”、“包含任意后缀”或者“不包含任意后缀”时,“内容”需要选择引用表名称,创建引用表的详细操作请参见创建引用表。
- 内容:输入或者选择条件匹配的内容。
“路径”包含“/admin/”
优先级
设置该条件规则检测的顺序值。如果您设置了多条规则,则多条规则间有先后匹配顺序,即访问请求将根据您设定的优先级依次进行匹配,优先级较小的规则优先匹配。
5
相关操作
- 若需要修改添加的JS脚本反爬虫规则,可单击待修改的路径规则所在行的“编辑”,修改该规则。
- 若需要删除添加的JS脚本反爬虫规则时,可单击待删除的路径规则所在行的“删除”,删除该规则。
配置示例-搜索引擎
放行百度或者谷歌的搜索引擎,同时拦截百度的POST请求。
- 参照1将“搜索引擎机器人”设置为放行,即将“搜索引擎机器人”的“状态”设置为
 。
。 - 参照配置精准访问防护规则配置如图12的规则。





