
Kafka性能优化
Kafka性能优化
优化客户端配置
生产者配置建议
可参考配置建议。
消费者配置建议
|
参数 |
推荐值 |
说明 |
|
max.poll.records |
500 |
消费者一次能消费到的最大消息数量,默认为500,如果每条消息处理时间较长,建议调小该值,确保在max.poll.interval.ms时间内能完成这一批消息的处理。 |
|
max.poll.interval.ms |
300000 |
两次消费拉取请求允许的最大时间间隔,默认为300秒,超过这个时间会认为消费者异常。 |
|
fetch.min.bytes |
根据业务调整 |
默认为1,每次FETCH请求最少返回数据量。增加该值可以提高吞吐量,同时也会产生一定延迟。 |
观测性能指标
Kafka提供了以下性能相关监控指标,从这些指标可以帮助分析消息堆积、分区数据倾斜、流量倾斜等问题。
|
指标ID |
指标名称 |
指标说明 |
|
broker_disk_usage |
磁盘容量使用率 |
该指标为从Kafka节点虚拟机层面采集的磁盘容量使用率。 |
|
broker_cpu_core_load |
CPU核均负载 |
该指标为从Kafka节点虚拟机层面采集的CPU每个核的平均负载。 |
|
broker_memory_usage |
内存使用率 |
该指标为Kafka节点虚拟机层面采集的内存使用率。 |
|
broker_cpu_usage |
CPU使用率 |
统计Kafka节点虚拟机的CPU使用率。 |
|
group_msgs |
堆积消息数 |
该指标用于统计Kafka实例中所有消费组中总堆积消息数。 |
|
topic_messages_remained |
队列可消费消息数 |
该指标用于统计消费组指定队列可以消费的消息个数。 |
|
broker_messages_in_rate |
每秒消息生产速率 |
统计Kafka节点每秒生产速率。 |
|
broker_connections |
连接数 |
统计Kafka节点连接数。 |
优化数据分区
Kafka将Topic划分为多个分区,所有消息分布式存储在各个分区上。每个分区有一个或多个副本,分布在不同的Broker节点上,每个副本存储一份全量数据,副本之间的消息数据保持同步。Kafka的Topic、分区、副本和代理的关系如下图所示:
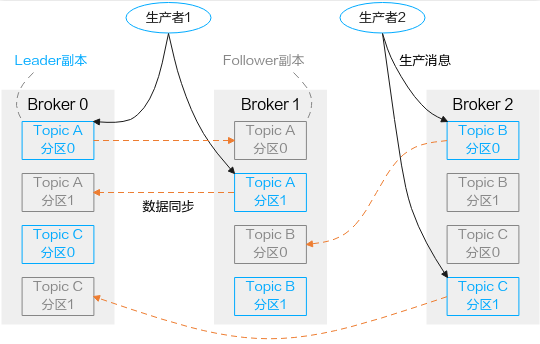
在实际业务过程中可能会遇到各节点间或分区之间业务数据不均衡的情况,业务数据不均衡会降低Kafka集群的性能,降低资源使用率。
业务数据不均衡原因
- 业务中部分Topic的流量远大于其他Topic,会导致节点间的数据不均衡。
- 生产者发送消息时指定了分区,未指定的分区没有消息,会导致分区间的数据不均衡。
- 生产者发送消息时指定了消息Key,按照对应的Key发送消息至对应的分区,会导致分区间的数据不均衡。
- 系统重新实现了分区分配策略,但策略逻辑有问题,会导致分区间的数据不均衡。
- Kafka扩容了Broker节点,新增的节点没有分配分区,会导致节点间的数据不均衡。
- 业务使用过程中随着集群状态的变化,多少会发生一些Leader副本的切换或迁移,会导致个别Broker节点上的数据更多,从而导致节点间的数据不均衡
使用数据压缩
在客户端CPU资源情况可控的情况下,使用压缩算法对数据进行压缩。
常用的压缩算法包括:ZIP,GZIP,SNAPPY,LZ4等。选择压缩算法时,需考虑数据的压缩率和压缩耗时。通常压缩率越高的算法,压缩耗时也越高。
|
压缩方式 |
压缩比 |
客户端CPU占用 |
服务端CPU占用 |
磁盘占用 |
broker带宽占用 |
|
gzip |
中 |
中 |
低 |
中 |
低 |
|
lz4 |
中 |
中 |
中 |
中 |
中 |
|
zstd |
高 |
中 |
低 |
低 |
低 |
|
snappy |
低 |
高 |
高 |
高 |
高 |
如果追求高TPS,建议采用lz4压缩算法;如果追求较低的网络I/O或希望较低的客户端/服务端CPU占用,建议采用zstd压缩算法。这里通常推荐使用lz4压缩算法,同时不建议使用gzip算法,因为它会是一种计算敏感的压缩算法。同时针对一批数据(batch)消息压缩,更好地运用批处理可以获得更高的TPS。




