
SELECT
功能描述
SELECT用于从表或视图中读取数据。
SELECT语句就像叠加在数据库表上的过滤器,利用SQL关键字从数据表中过滤出用户需要的数据。
注意事项
- SELECT支持普通表和HDFS的Join,不支持普通表和GDS外表的join。即SELECT语句中不能同时出现普通表和GDS外表。
- 必须对每个在SELECT命令中使用的字段有SELECT权限。
- 使用FOR UPDATE或FOR SHARE还要求UPDATE权限。

- 尽量避免出现计划不下推的SQL写法(EXPLAIN输出的执行计划中出现"_REMOTE_XXX_QUERY_")。
- 尽量避免行存大表(数据量1000万行以上)的频繁COUNT查询。
- 单SQL的UNION/UNION All分支不能超过50,多表关联不能超过25张非复制表。
- 尽量避免大表关联时缺少关联条件而求笛卡尔积。
- 多表关联查询时,单个语句Stream建议控制在100以内。
- 谨慎使用递归语句(WITH RECURSIVE),需明确数据重复度和终止条件,确保递归可按预期结束。
- 更多开发设计规范参见总体开发设计规范。
语法格式
- 查询数据
1 2 3 4 5 6 7 8 9 10 11 12 13 |
[ WITH [ RECURSIVE ] with_query [, ...] ] SELECT [/*+ plan_hint */] [ ALL | DISTINCT [ ON ( expression [, ...] ) ] ] { * | {expression [ [ AS ] output_name ]} [, ...] } [ FROM from_item [, ...] ] [ WHERE condition ] [ GROUP BY grouping_element [, ...] ] [ HAVING condition [, ...] ] [ WINDOW {window_name AS ( window_definition )} [, ...] ] [ { UNION | INTERSECT | EXCEPT | MINUS } [ ALL | DISTINCT ] select ] [ ORDER BY {expression [ [ ASC | DESC | USING operator ] | nlssort_expression_clause ] [ NULLS { FIRST | LAST } ]} [, ...] ] [ { [ LIMIT { count | ALL } ] [ OFFSET start [ ROW | ROWS ] ] } | { LIMIT start, { count | ALL } } ] [ FETCH { FIRST | NEXT } [ count ] { ROW | ROWS } ONLY ] [ {FOR { UPDATE | SHARE } [ OF table_name [, ...] ] [ NOWAIT ]} [...] ]; |

condition和expression中可以使用targetlist中表达式的别名。
- 只能同一层引用。
- 只能引用targetlist中的别名。
- 只能是后面的表达式引用前面的表达式。
- 不能包含volatile函数。
- 不能包含Window function函数。
- 不支持在join on条件中引用别名。
- targetlist中有多个要应用的别名则报错。
- 其中子查询with_query为:
1 2
with_query_name [ ( column_name [, ...] ) ] AS [ [ NOT ] MATERIALIZED ] ( {select | values | insert | update | delete} )
- 其中指定查询源from_item为:
1 2 3 4 5 6
{[ ONLY ] table_name [ * ] [ partition_clause ] [ [ AS ] alias [ ( column_alias [, ...] ) ] ] |( select ) [ AS ] alias [ ( column_alias [, ...] ) ] |with_query_name [ [ AS ] alias [ ( column_alias [, ...] ) ] ] |function_name ( [ argument [, ...] ] ) [ AS ] alias [ ( column_alias [, ...] | column_definition [, ...] ) ] |function_name ( [ argument [, ...] ] ) AS ( column_definition [, ...] ) |from_item [ NATURAL ] join_type from_item [ ON join_condition | USING ( join_column [, ...] ) ]}
- 其中group子句为:
1 2 3 4 5 6
( ) | expression | ( expression [, ...] ) | ROLLUP ( { expression | ( expression [, ...] ) } [, ...] ) | CUBE ( { expression | ( expression [, ...] ) } [, ...] ) | GROUPING SETS ( grouping_element [, ...] )
- 其中指定分区partition_clause为:
1 2
PARTITION { ( partition_name ) | FOR ( partition_value [, ...] ) }
指定分区只适合普通表。
- 其中设置排序方式nlssort_expression_clause为:
1NLSSORT ( column_name, ' NLS_SORT = { SCHINESE_PINYIN_M | generic_m_ci } ' )
- 简化版查询语法,功能相当于select * from table_name。
1TABLE { ONLY {(table_name)| table_name} | table_name [ * ]};
参数说明
- WITH [ RECURSIVE ] with_query [, ...]
用于声明一个或多个可以在主查询中通过名字引用的子查询,相当于临时表。
如果声明了RECURSIVE,那么允许SELECT子查询通过名字引用它自己。
其中with_query的详细格式为:with_query_name [ ( column_name [, ...] ) ] AS [ [ NOT ] MATERIALIZED ] ( {select | values | insert | update | delete} )
- with_query_name指定子查询生成的结果集名字,在查询中可使用该名称访问子查询的结果集。
- 默认情况下,被主查询多次引用的with_query通常只被执行一次,并将其结果集进行物化,供主查询多次查询其结果集;被主查询引用一次的with_query,则不再单独执行,而是将其子查询直接替换到主查询中的引用处,随主查询一起执行。显示指定[ NOT ] MATERIALIZED,可改变默认行为:
- 指定MATERIALIZED时,将子查询执行一次,并将其结果集进行物化。
- 指定NOT MATERIALIZED时,则将其子查询替换到主查询中的引用处。以下几种情况会忽略NOT MATERIALIZED:
- 子查询中含有volatile函数。
- 子查询为含有FOR UPDATE/FOR SHARE的SELECT/VALUES语句。
- 子查询为INSERT/UPDATE/DELETE等语句。
- with_query为RECURSIVE。
- 被引用次数大于1的with_query2引用了外层自引用的with_query1,则with_query2不能被替换到引用处。
- column_name指定子查询结果集中显示的列名。
- 每个子查询可以是SELECT,VALUES,INSERT,UPDATE或DELETE语句。
- plan_hint子句
以/*+ */的形式在SELECT关键字后,用于对SELECT对应的语句块生成的计划进行hint调优,详细用法请参见章节:使用Plan Hint进行调优。
- ALL
声明返回所有符合条件的行,是默认行为,可以省略该关键字。
- DISTINCT [ ON ( expression [, ...] ) ]
从SELECT的结果集中删除所有重复的行,使结果集中的每行都是唯一的。
ON ( expression [, ...] ) 只保留那些在给出的表达式上运算出相同结果的行集合中的第一行。

DISTINCT ON表达式是使用与ORDER BY相同的规则进行解释的。除非使用了ORDER BY来保证需要的行首先出现,否则,"第一行" 是不可预测的。
- SELECT列表
指定查询表中列名,可以是部分列或者是全部(使用通配符*表示)。
通过使用子句AS output_name可以为输出字段取个别名,这个别名通常用于输出字段的显示。
列名可以用下面几种形式表达:
- 手动输入列名,多个列之间用英文逗号(,)分隔。
- 可以是FROM子句里面计算出来的字段。
- FROM子句
为SELECT声明一个或者多个源表。
FROM子句涉及的元素如下所示。
- table_name
- alias
给表或复杂的表引用起一个临时的表别名,以便被其余的查询引用。
别名用于缩写或者在自连接中消除歧义。如果提供了别名,它就会完全隐藏表的实际名字。
- column_alias
- PARTITION
- partition_name
- partition_value
指定的分区键值。在创建分区表时,如果指定了多个分区键,可以通过PARTITION FOR子句指定的这一组分区键的值,唯一确定一个分区。
- subquery
- with_query_name
- function_name
- join_type
- [ INNER ] JOIN
一个JOIN子句组合两个FROM项。可使用圆括弧以决定嵌套的顺序。如果没有圆括弧,JOIN从左向右嵌套。
在任何情况下,JOIN都比逗号分隔的FROM项绑定得更紧。
- LEFT [ OUTER ] JOIN
返回笛卡尔积中所有符合连接条件的行,再加上左表中通过连接条件没有匹配到右表行的那些行。这样,左边的行将扩展为生成表的全长,方法是在那些右表对应的字段位置填上NULL。请注意,只在计算匹配的时候,才使用JOIN子句的条件,外层的条件是在计算完毕之后施加的。
- RIGHT [ OUTER ] JOIN
返回所有内连接的结果行,加上每个不匹配的右边行(左边用NULL扩展)。
这只是一个符号上的方便,因为总是可以把它转换成一个LEFT OUTER JOIN,只要把左边和右边的输入互换位置即可。
- FULL [ OUTER ] JOIN
- CROSS JOIN
CROSS JOIN等效于INNER JOIN ON(TRUE) ,即没有被条件删除的行。这种连接类型只是符号上的方便,因为它们与简单的FROM和WHERE的效果相同。
必须为INNER和OUTER连接类型声明一个连接条件,即NATURAL ON,join_condition,USING (join_column [, ...]) 之一。但是它们不能出现在CROSS JOIN中。
其中CROSS JOIN和INNER JOIN生成一个简单的笛卡尔积,和在FROM的顶层列出两个项的结果相同。
- [ INNER ] JOIN
- ON join_condition
- USING(join_column[,...])
ON left_table.a = right_table.a AND left_table.b = right_table.b ... 的简写。要求对应的列必须同名。
- NATURAL
- from item
- WHERE子句
WHERE子句构成一个行选择表达式,用来缩小SELECT查询的范围。condition是返回值为布尔型的任意表达式,任何不满足该条件的行都不会被检索。
WHERE子句中可以通过指定"(+)"操作符的方法将表的连接关系转换为外连接。但是不建议用户使用这种用法,因为这并不是SQL的标准语法,在做平台迁移的时候可能面临语法兼容性的问题。同时,使用"(+)"有很多限制:
- "(+)"只能出现在where子句中。
- 如果from子句中已经有指定表连接关系,那么不能再在where子句中使用"(+)"。
- "(+)"只能作用在表或者视图的列上,不能作用在表达式上。
- 如果表A和表B有多个连接条件,那么必须在所有的连接条件中指定"(+)",否则"(+)"将不会生效,表连接会转化成内连接,并且不给出任何提示信息。
- "(+)"作用的连接条件中的表不能跨查询或者子查询。如果"(+)"作用的表,不在当前查询或者子查询的from子句中,则会报错。如果"(+)"作用的对端的表不存在,则不报错,同时连接关系会转化为内连接。
- "(+)"作用的表达式不能直接通过"OR"连接。
- 如果"(+)"作用的列是和一个常量的比较关系, 那么这个表达式会成为join条件的一部分。
- 同一个表不能对应多个外表。
- "(+)"只能出现"比较表达式","NOT表达式",“ANY表达式”,“ALL表达式”,“IN表达式”,“NULLIF表达式”,“IS DISTINCT FROM表达式”,“IS OF”表达式。"(+)"不能出现在其他类型表达式中,并且这些表达式中不允许出现通过“AND”和“OR”连接的表达式。
- "(+)"只能转化为左外连接或者右外连接,不能转化为全连接,即不能在一个表达式的两个表上同时指定"(+)"
对于WHERE子句的LIKE操作符,当LIKE中要查询特殊字符“%”、“_”、“\”的时候需要使用反斜杠“\”来进行转义。
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
CREATE TABLE tt01 (id int,content varchar(50)); INSERT INTO tt01 values (1,'Jack say ''hello'''); INSERT INTO tt01 values (2,'Rose do 50%'); INSERT INTO tt01 values (3,'Lilei say ''world'''); INSERT INTO tt01 values (4,'Hanmei do 100%'); SELECT * FROM tt01; id | content ----+------------------- 3 | Lilei say 'world' 4 | Hanmei do 100% 1 | Jack say 'hello' 2 | Rose do 50% (4 rows) SELECT * FROM tt01 WHERE content like '%''he%'; id | content ----+------------------ 1 | Jack say 'hello' (1 row) SELECT * FROM tt01 WHERE content like '%50\%%'; id | content ----+------------- 2 | Rose do 50% (1 row)
- GROUP BY子句
将查询结果按某一列或多列的值分组,值相等的为一组。
- ROLLUP ( { expression | ( expression [, ...] ) } [, ...] )
ROLLUP是计算一个有序的分组列在GROUP BY中指定的标准聚集值,然后从右到左进一步创建高层次的部分和,最后创建了累积和。一个分组能够看做一系列的分组集。例如:
1GROUP BY ROLLUP (a,b,c)
等价于:
1GROUP BY GROUPING SETS((a,b,c), (a,b), (a), ( ))
ROLLUP子句中的元素可以是单独的字段或表达式,也可以是使用括号包含的列表。如果是括号中的列表,产生分组集时它们必须作为一个整体。例如:
1GROUP BY ROLLUP ((a,b), (c,d))
等价于:
1GROUPING SETS ((a,b,c,d), (a,b), (c,d ), ( ))
- CUBE ( { expression | ( expression [, ...] ) } [, ...] )
CUBE是自动对group by子句中列出的字段进行分组汇总,结果集将包含维度列中各值的所有可能组合,以及与这些维度值组合相匹配的基础行中的聚合值。它会为每个分组返回一行汇总信息, 用户可以使用CUBE来产生交叉表值。比如,在CUBE子句中给出三个表达式(n = 3),运算结果为2n = 23 = 8组。 以n个表达式的值分组的行称为常规行,其余的行称为超级聚集行。例如:
1GROUP BY CUBE (a,b,c)
等价于:
1GROUP BY GROUPING SETS((a,b,c), (a,b), (a,c), (b,c), (a), (b), (c), ( ))
CUBE子句中的元素可以是单独的字段或表达式,也可以是使用括号包含的列表。如果是括号中的列表,产生分组集时它们必须作为一个整体。例如:
1GROUP BY CUBE (a, (b, c), d)
等价于:
1GROUP BY GROUPING SETS ((a,b,c,d), (a,b,c), (a), ( ))
- GROUPING SETS ( grouping_element [, ...] )
GROUPING SETS子句是GROUP BY子句的进一步扩展,它可以使用户指定多个GROUP BY选项。选项用于定义分组集,每个分组集都需要包含在单独的括号中,空白的括号(())表示将所有数据当作一个组处理。 这样做可以通过裁剪用户不需要的数据组来提高效率。 用户可以根据需要指定所需的数据组进行查询。
如果SELECT列表的表达式中引用了那些没有分组的字段,则会报错,除非使用了聚集函数,因为对于未分组的字段,可能返回多个数值。
- ROLLUP ( { expression | ( expression [, ...] ) } [, ...] )
- HAVING子句
与GROUP BY子句配合用来选择特殊的组。HAVING子句将组的一些属性与一个常数值比较,只有满足HAVING子句中的逻辑表达式的组才会被提取出来。
- WINDOW子句
一般形式为WINDOW window_name AS ( window_definition ) [, ...],window_name是可以被随后的窗口定义所引用的名称,window_definition可以是以下的形式:
[ existing_window_name ]
[ PARTITION BY expression [, ...] ]
[ ORDER BY expression [ ASC | DESC | USING operator ] [ NULLS { FIRST | LAST } ] [, ...] ]
[ frame_clause ]
frame_clause为窗函数定义一个窗口框架window frame,窗函数(并非所有)依赖于框架,window frame是当前查询行的一组相关行。frame_clause可以是以下的形式:
[ RANGE | ROWS ] frame_start
[ RANGE | ROWS ] BETWEEN frame_start AND frame_end
frame_start和frame_end可以是:
UNBOUNDED PRECEDING
value PRECEDING(RANGE不支持)
CURRENT ROW
value FOLLOWING(RANGE不支持)
UNBOUNDED FOLLOWING
对列存表的查询目前只支持row_number窗口函数,不支持frame_clause。
- UNION子句
UNION计算多个SELECT语句返回行集合的并集。
UNION子句有如下约束条件:
- 除非声明了ALL子句,否则缺省的UNION结果不包含重复的行。
- 同一个SELECT语句中的多个UNION操作符是从左向右计算的,除非用圆括弧进行了标识。
- FOR UPDATE不能在UNION的结果或输入中声明。
一般表达式:
select_statement UNION [ALL] select_statement
- select_statement可以是任何没有ORDER BY、LIMIT、FOR UPDATE子句的SELECT语句。
- 如果用圆括弧包围,ORDER BY和LIMIT可以附着在子表达式里。
- INTERSECT子句
INTERSECT计算多个SELECT语句返回行集合的交集,不含重复的记录。
INTERSECT子句有如下约束条件:
- 同一个SELECT语句中的多个INTERSECT操作符是从左向右计算的,除非用圆括弧进行了标识。
- 当对多个SELECT语句的执行结果进行UNION和INTERSECT操作的时候,会优先处理INTERSECT。
一般形式:
select_statement INTERSECT select_statement
select_statement可以是任何没有FOR UPDATE子句的SELECT语句。
- EXCEPT子句
EXCEPT子句有如下的通用形式:
select_statement EXCEPT [ ALL ] select_statement
select_statement是任何没有FOR UPDATE子句的SELECT表达式。
EXCEPT操作符计算存在于左边SELECT语句的输出而不存在于右边SELECT语句输出的行。
EXCEPT的结果不包含任何重复的行,除非声明了ALL选项。使用ALL时,一个在左边表中有m个重复而在右边表中有n个重复的行将在结果中出现max(m-n,0) 次。
除非用圆括弧指明顺序,否则同一个SELECT语句中的多个EXCEPT操作符是从左向右计算的。EXCEPT和UNION的绑定级别相同。
目前,不能给EXCEPT的结果或者任何EXCEPT的输入声明FOR UPDATE子句。
- MINUS子句
与EXCEPT子句具有相同的功能和用法。
- ORDER BY子句
对SELECT语句检索得到的数据进行升序或降序排序。对于ORDER BY表达式中包含多列的情况:
- 首先根据最左边的列进行排序,如果这一列的值相同,则根据下一个表达式进行比较,以此类推。
- 如果对于所有声明的表达式都相同,则按随机顺序返回。
- ORDER BY中排序的列必须包括在SELECT语句所检索的结果集的列中。
- [ { [ LIMIT { count | ALL } ] [ OFFSET start [ ROW | ROWS ] ] } | { LIMIT start, { count | ALL } } ]
LIMIT子句由两个独立的Limit子句、Offset子句和一个多参Limit子句构成:
LIMIT { count | ALL }
OFFSET start [ ROW | ROWS ]
LIMIT start, { count | ALL }
其中,count声明返回的最大行数,而start声明开始返回行之前忽略的行数。如果这两个参数都指定了,会在开始计算count个返回行之前先跳过start行。多参Limit子句不可和单参的Limit子句或Offset子句共同出现。
- FETCH { FIRST | NEXT } [ count ] { ROW | ROWS } ONLY
如果不指定count,默认值为1,FETCH子句限定返回查询结果从第一行开始的总行数。
- FOR UPDATE子句
FOR UPDATE子句将对SELECT检索出来的行进行加锁。这样避免它们在当前事务结束前被其他事务修改或者删除,即其他企图UPDATE、 DELETE、 SELECT FOR UPDATE这些行的事务将被阻塞,直到当前事务结束。
为了避免操作等待其他事务提交,可使用NOWAIT选项,如果被选择的行不能立即被锁住,执行SELECT FOR UPDATE NOWAIT将会立即汇报一个错误,而不是等待。
FOR SHARE的行为类似,只是它在每个检索出来的行上要求一个共享锁,而不是一个排他锁。一个共享锁阻塞其它事务执行UPDATE、DELETE、SELECT,不阻塞SELECT FOR SHARE。
如果在FOR UPDATE或FOR SHARE中明确指定了表名字,则只有这些指定的表被锁定,其他在SELECT中使用的表将不会被锁定。否则,将锁定该命令中所有使用的表。
如果FOR UPDATE或FOR SHARE应用于一个视图或者子查询,它同样将锁定所有该视图或子查询中使用到的表。
多个FOR UPDATE和FOR SHARE子句可以用于为不同的表指定不同的锁定模式。
如果一个表中同时出现(或隐含同时出现)在FOR UPDATE和FOR SHARE子句中,则按照FOR UPDATE处理。类似的,如果影响一个表的任意子句中出现了NOWAIT,该表将按照NOWAIT处理。
- 对于for update/share,执行计划不能下推的SQL,直接返回报错信息;对于执行计划可以下推的,下推到DN执行。
- 对列存表的查询不支持for update/share。
- NLS_SORT
指定某字段按照特殊方式排序。目前仅支持中文拼音格式排序和不区分大小写排序。
取值范围:
- SCHINESE_PINYIN_M,按照中文拼音排序(目前只支持GBK字符集内的一级汉字排序)。如果要支持此排序方式,在创建数据库时需要指定编码格式为“GBK”,否则排序无效。
- generic_m_ci,不区分大小写排序。
- PARTITION子句
查询某个分区表中相应分区的数据。
示例
先通过子查询得到一张临时表temp_t,然后查询表temp_t中的所有数据。
1
|
WITH temp_t(name,isdba) AS (SELECT usename,usesuper FROM pg_user) SELECT * FROM temp_t; |
为名为temp_t的with_query显示指定MATERIALIZED,然后查询表temp_t中的所有数据。
1
|
WITH temp_t(name,isdba) AS MATERIALIZED (SELECT usename,usesuper FROM pg_user) SELECT * FROM temp_t; |
为名为temp_t的with_query显示指定NOT MATERIALIZED,然后查询表temp_t中的所有数据。
1 2 3 4 |
WITH temp_t(name,isdba) AS NOT MATERIALIZED (SELECT usename,usesuper FROM pg_user) SELECT * FROM temp_t t1 WHERE name LIKE 'A%' UNION ALL SELECT * FROM temp_t t2 WHERE name LIKE 'B%'; |
查询tpcds.reason表的所有r_reason_sk记录,且去除重复。
1
|
SELECT DISTINCT(r_reason_sk) FROM tpcds.reason; |
LIMIT子句示例:获取表中一条记录。
1
|
SELECT * FROM tpcds.reason LIMIT 1; |
LIMIT子句示例:获取表中第三条记录。
1
|
SELECT * FROM tpcds.reason LIMIT 1 OFFSET 2; |
LIMIT子句示例:获取表中前两条记录。
1
|
SELECT * FROM tpcds.reason LIMIT 2; |
查询所有记录,且按字母升序排列。
1
|
SELECT r_reason_desc FROM tpcds.reason ORDER BY r_reason_desc; |
通过表别名,从pg_user和pg_user_status这两张表中获取数据。
1
|
SELECT a.usename,b.locktime FROM pg_user a,pg_user_status b WHERE a.usesysid=b.roloid; |
FULL JOIN子句示例:将pg_user和pg_user_status这两张表的数据进行全连接显示,即数据的合集。
1
|
SELECT a.usename,b.locktime,a.usesuper FROM pg_user a FULL JOIN pg_user_status b on a.usesysid=b.roloid; |
GROUP BY子句示例:根据查询条件过滤,并对结果进行分组。
1
|
SELECT r_reason_id, AVG(r_reason_sk) FROM tpcds.reason GROUP BY r_reason_id HAVING AVG(r_reason_sk) > 25; |
GROUP BY子句示例:通过group by别名来对结果进行分组。
1
|
SELECT r_reason_id AS id FROM tpcds.reason GROUP BY id; |
GROUP BY CUBE子句示例:根据查询条件过滤,并对结果进行分组汇总。
1
|
SELECT r_reason_id,AVG(r_reason_sk) FROM tpcds.reason GROUP BY CUBE(r_reason_id,r_reason_sk); |
GROUP BY GROUPING SETS子句示例:根据查询条件过滤,并对结果进行分组汇总。
1
|
SELECT r_reason_id,AVG(r_reason_sk) FROM tpcds.reason GROUP BY GROUPING SETS((r_reason_id,r_reason_sk),r_reason_sk); |
UNION子句示例:将表tpcds.reason里r_reason_desc字段中的内容以W开头和以N开头的进行合并。
1 2 3 4 5 6 7 |
SELECT r_reason_sk, tpcds.reason.r_reason_desc FROM tpcds.reason WHERE tpcds.reason.r_reason_desc LIKE 'W%' UNION SELECT r_reason_sk, tpcds.reason.r_reason_desc FROM tpcds.reason WHERE tpcds.reason.r_reason_desc LIKE 'N%'; |
NLS_SORT子句示例:中文拼音排序。
1 2 3 |
CREATE TABLE stu_pinyin_info (id bigint, name text) DISTRIBUTE BY REPLICATION; INSERT INTO stu_pinyin_info VALUES (1, '雷锋'),(2, '石传祥'); SELECT * FROM stu_pinyin_info ORDER BY NLSSORT (name, 'NLS_SORT = SCHINESE_PINYIN_M' ); |

不区分大小写排序:
1 2 3 |
CREATE TABLE stu_icase_info (id bigint, name text) DISTRIBUTE BY REPLICATION; INSERT INTO stu_icase_info VALUES (1, 'aaaa'),(2, 'AAAA'); SELECT * FROM stu_icase_info ORDER BY NLSSORT (name, 'NLS_SORT = generic_m_ci'); |

创建分区表tpcds.reason_p,并插入数据,再从tpcds.reason_p的表分区P_05_BEFORE中获取数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
CREATE TABLE tpcds.reason_p ( r_reason_sk integer, r_reason_id character(16), r_reason_desc character(100) ) PARTITION BY RANGE (r_reason_sk) ( partition P_05_BEFORE values less than (05), partition P_15 values less than (15), partition P_25 values less than (25), partition P_35 values less than (35), partition P_45_AFTER values less than (MAXVALUE) ); INSERT INTO tpcds.reason_p values(3,'AAAAAAAABAAAAAAA','reason 1'),(10,'AAAAAAAABAAAAAAA','reason 2'),(4,'AAAAAAAABAAAAAAA','reason 3'),(10,'AAAAAAAABAAAAAAA','reason 4'),(10,'AAAAAAAABAAAAAAA','reason 5'),(20,'AAAAAAAACAAAAAAA','reason 6'),(30,'AAAAAAAACAAAAAAA','reason 7'); |
1
|
SELECT * FROM tpcds.reason_p PARTITION (P_05_BEFORE); |

1 2 |
——查询分区P_15的行数: SELECT count(*) FROM tpcds.reason_p PARTITION (P_15); |
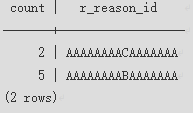
GROUP BY子句示例:按r_reason_id分组统计tpcds.reason_p表中的记录数。
1
|
SELECT COUNT(*),r_reason_id FROM tpcds.reason_p GROUP BY r_reason_id; |
GROUP BY CUBE子句示例:根据查询条件过滤,并对查询结果分组汇总。
1
|
SELECT * FROM tpcds.reason GROUP BY CUBE (r_reason_id,r_reason_sk,r_reason_desc); |
GROUP BY GROUPING SETS子句示例:根据查询条件过滤,并对查询结果分组汇总。
1
|
SELECT * FROM tpcds.reason GROUP BY GROUPING SETS ((r_reason_id,r_reason_sk),r_reason_desc); |
HAVING子句示例:按r_reason_id分组统计tpcds.reason_p表中的记录,并只显示r_reason_id个数大于2的信息。
1
|
SELECT COUNT(*) c,r_reason_id FROM tpcds.reason_p GROUP BY r_reason_id HAVING c>2; |

IN子句示例:按r_reason_id分组统计tpcds.reason_p表中的r_reason_id个数,并只显示r_reason_id值为 AAAAAAAABAAAAAAA或AAAAAAAADAAAAAAA的个数。
1
|
SELECT COUNT(*),r_reason_id FROM tpcds.reason_p GROUP BY r_reason_id HAVING r_reason_id IN('AAAAAAAABAAAAAAA','AAAAAAAADAAAAAAA'); |

INTERSECT子句示例:查询r_reason_id等于AAAAAAAABAAAAAAA,并且r_reason_sk小于5的信息。
1
|
SELECT * FROM tpcds.reason_p WHERE r_reason_id='AAAAAAAABAAAAAAA' INTERSECT SELECT * FROM tpcds.reason_p WHERE r_reason_sk<5; |

EXCEPT子句示例:查询r_reason_id等于AAAAAAAABAAAAAAA,并且去除r_reason_sk小于4的信息。
1
|
SELECT * FROM tpcds.reason_p WHERE r_reason_id='AAAAAAAABAAAAAAA' EXCEPT SELECT * FROM tpcds.reason_p WHERE r_reason_sk<4; |

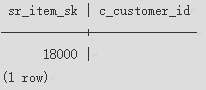
通过在where子句中指定"(+)"来实现左连接。
1 2 |
select t1.sr_item_sk ,t2.c_customer_id from store_returns t1, customer t2 where t1.sr_customer_sk = t2.c_customer_sk(+) order by 1 desc limit 1; |
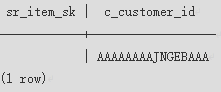
通过在where子句中指定"(+)"来实现右连接。
1 2 |
select t1.sr_item_sk ,t2.c_customer_id from store_returns t1, customer t2 where t1.sr_customer_sk(+) = t2.c_customer_sk order by 1 desc limit 1; |
通过在where子句中指定"(+)"来实现左连接,并且增加连接条件。
1
|
select t1.sr_item_sk ,t2.c_customer_id from store_returns t1, customer t2 where t1.sr_customer_sk = t2.c_customer_sk(+) and t2.c_customer_sk(+) < 1 order by 1 limit 1; |

不支持在where子句中指定"(+)"的同时使用内层嵌套AND/OR的表达式。
1
|
select t1.sr_item_sk ,t2.c_customer_id from store_returns t1, customer t2 where not(t1.sr_customer_sk = t2.c_customer_sk(+) and t2.c_customer_sk(+) < 1); |

where子句在不支持表达式宏指定"(+)"会报错。
1
|
select t1.sr_item_sk ,t2.c_customer_id from store_returns t1, customer t2 where (t1.sr_customer_sk = t2.c_customer_sk(+))::bool; |
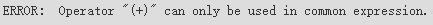
where子句在表达式的两边都指定"(+)"会报错。
1
|
select t1.sr_item_sk ,t2.c_customer_id from store_returns t1, customer t2 where t1.sr_customer_sk(+) = t2.c_customer_sk(+); |





