
文件系统输出流(推荐)
功能描述
创建sink流将数据输出到分布式文件系统(HDFS)或者对象存储服务(OBS)等文件系统。数据生成后,可直接对生成的目录创建非DLI表,通过DLI SQL进行下一步处理分析,并且输出数据目录支持分区表结构。适用于数据转储、大数据分析、备份或活跃归档、深度或冷归档等场景。
对象存储服务(Object Storage Service,简称OBS)是一个基于对象的海量存储服务,为客户提供海量、安全、高可靠、低成本的数据存储能力。
语法格式
1 2 3 4 5 6 7 8 9 |
CREATE SINK STREAM stream_id (attr_name attr_type (',' attr_name attr_type)* ) [PARTITIONED BY (attr_name (',' attr_name)*] WITH ( type = "filesystem", file.path = "obs://bucket/xx", encode = "parquet", ak = "", sk = "" ); |
关键字
|
参数 |
是否必选 |
说明 |
|---|---|---|
|
type |
是 |
输出流类型。“type”为“filesystem”,表示输出数据到文件系统。 |
|
file.path |
是 |
输出目录,格式为: schema://file.path。 当前schame只支持obs和hdfs。
|
|
encode |
是 |
输出数据编码格式,当前支持“parquet”格式和“csv”格式。
|
|
ak |
否 |
输出到OBS时该参数必填。用于访问OBS认证的accessKey,可使用全局变量,屏蔽敏感信息。 关于全局变量在控制台上的使用方法,请参考《数据湖探索用户指南》。 |
|
sk |
否 |
输出到OBS时该参数必填。用于访问OBS认证的secretKey,可使用全局变量,屏蔽敏感信息。 关于全局变量在控制台上的使用方法,请参考《数据湖探索用户指南》。 |
|
krb_auth |
否 |
创建跨源认证的认证名。开启kerberos认证时,需配置该参数。如果创建的MRS集群未开启kerb认证的集群,请确保在DLI队列host文件中添加MRS集群master节点的“/etc/hosts”信息。 |
|
field_delimiter |
否 |
属性分隔符。 当编码格式为“csv”时,需要设置属性分隔符,用户可以自定义,如:“,”。 |
注意事项
- 使用文件系统输出流的Flink作业必须开启checkpoint,保证作业的一致性。
- 为了避免数据丢失或者数据被覆盖,开启作业异常自动重启或者手动重启,需要配置为“从checkpoint恢复”。
- checkpoint间隔设置需在输出文件实时性、文件大小和恢复时长之间进行权衡,比如10分钟。
- checkpoint支持如下两种模式:
- AtLeastOnce:事件至少被处理一次。
- ExactlyOnce:事件仅被处理一次。
- 使用文件系统输出流写入数据到OBS时,应避免多个作业写同一个目录的情况。
- OBS对象存储桶的默认行为为覆盖写,可能导致数据丢失。
- OBS并行文件系统桶的默认行为追加写,可能导致数据混淆。
因为以上OBS桶类型行为的区别,为避免作业异常重启可能导致的数据异常问题,请根据您的业务需求选择OBS桶类型。
HDFS代理用户配置
- 登录MRS管理页面。
- 选择MRS的HDFS Namenode配置,在“自定义”中添加配置参数。
图1 HDFS服务配置
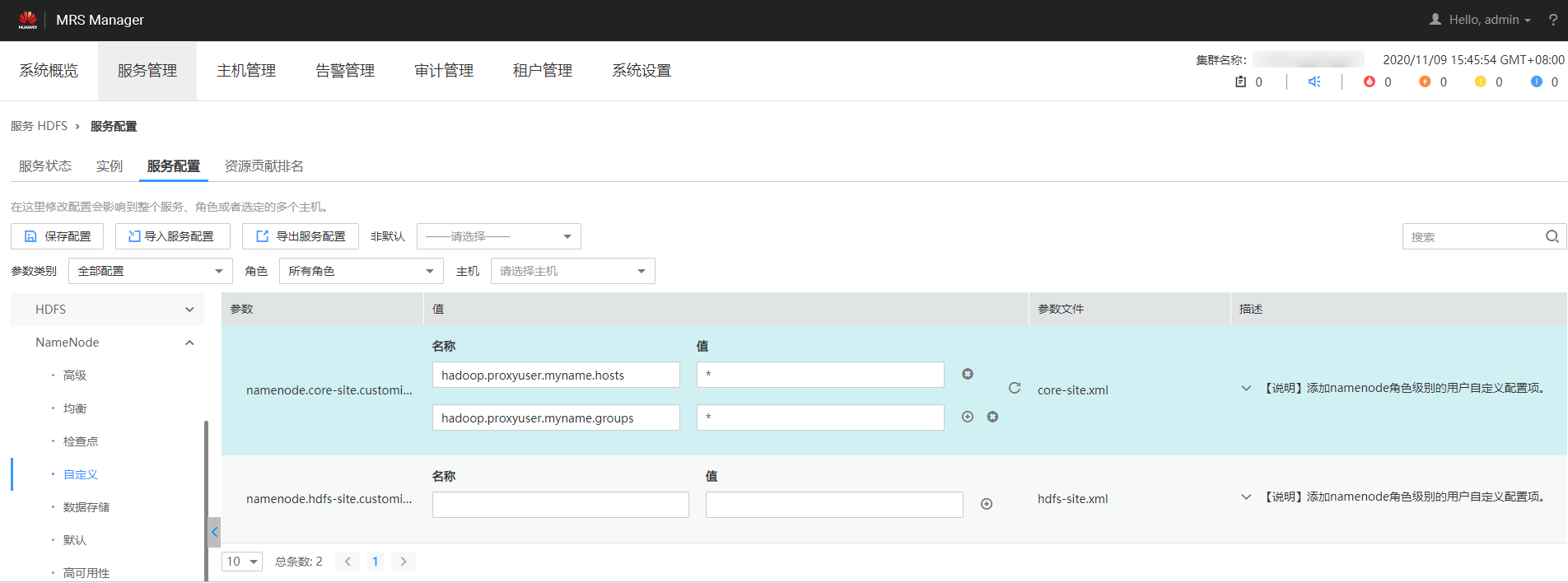
其中,core-site值名称“hadoop.proxyuser.myname.hosts”和“hadoop.proxyuser.myname.groups”中的“myname”为传入的krb认证用户名称。

需要保证写入HDFS数据路径权限为777。
- 配置完成后,单击“保存配置”进行保存。
示例
- 示例一:
该示例将car_info数据,以buyday字段为分区字段,parquet为编码格式,转储数据到OBS。
1 2 3 4 5 6 7 8 9 10 11 12 13
create sink stream car_infos ( carId string, carOwner string, average_speed double, buyday string ) partitioned by (buyday) with ( type = "filesystem", file.path = "obs://obs-sink/car_infos", encode = "parquet", ak = "{{myAk}}", sk = "{{mySk}}" );
数据最终在OBS中的存储目录结构为:obs://obs-sink/car_infos/buyday=xx/part-x-x。
数据生成后,可通过如下SQL语句建立OBS分区表,用于后续批处理:
- 创建OBS分区表。
1 2 3 4 5 6 7 8
create table car_infos ( carId string, carOwner string, average_speed double ) partitioned by (buyday string) stored as parquet location 'obs://obs-sink/car_infos';
- 从关联OBS路径中恢复分区信息。
1alter table car_infos recover partitions;
- 创建OBS分区表。
- 示例二
该示例将car_info数据,以buyday字段为分区字段,csv为编码格式,转储数据到HDFS。
1 2 3 4 5 6 7 8 9 10 11 12
create sink stream car_infos ( carId string, carOwner string, average_speed double, buyday string ) partitioned by (buyday) with ( type = "filesystem", file.path = "hdfs://node-master1sYAx:9820/user/car_infos", encode = "csv", field_delimiter = "," );
数据最终在HDFS中的存储目录结构为:/user/car_infos/buyday=xx/part-x-x。




